Продолжая разбирать production-кейсы реального использования этих технологий Big Data, сегодня поговорим подробнее, каковы плюсы совместного применения Kudu, Spark Streaming, Kafka и Cloudera Impala на примере аналитической платформы для мониторинга событий информационной безопасности банка «Открытие». Также читайте в нашей статье про возможности этих технологий в контексте машинного обучения (Machine Learning), в...

Сегодня мы рассмотрим практический кейс использования Apache Kudu с Kafka, Storm и Cloudera Impala в крупной китайской корпорации, которая производит смартфоны. На базе этих Big Data технологий компания Xiaomi построила собственную платформу для BI-аналитики больших данных и генерации отчетности в реальном времени. История Kudu-проекта в Xiaomi Корпорация Xiaomi начала использовать...
Вчера мы говорили про интеграцию Apache Kudu со Spark SQL, Kafka и Cloudera Impala для эффективной организации озера данных (Data Lake), обеспечивающего быструю аналитику больших данных в режиме реального времени. В продолжение этой темы, сегодня рассмотрим 5 примеров практического использования kudu в Big Data проектах, уделив особое внимание системам бизнес-аналитики...

В продолжение темы про совместное использование Apache Kudu с другими технологиями Big Data, сегодня рассмотрим, как эта NoSQL-СУБД работает вместе с Kafka, Spark и Cloudera Impala для построения озера данных (Data Lake) для быстрой аналитики больших данных в режиме реального времени. Также читайте в нашей статье про особенности интеграции Apache...

В этой статье продолжим разговор про Apache Kudu и рассмотрим, как эта NoSQL-СУБД используется с Hadoop и Cloudera Impala, чем она полезна в организации озера данных (Data Lake) и почему Куду не заменяет, а успешно дополняет HDFS и HBase для эффективной работы с большими данными (Big Data). Apache Kudu в...

Сегодня поговорим про движки хранения больших данных в экосистеме Apache Hadoop и рассмотрим, что такое Kudu, каковы особенности применения, достоинства и недостатки этой колоночной NoSQL-СУБД. Также читайте в нашей статье, как Kudu связан с Impala, Spark и другими Big Data фреймворками. Что такое Apache Kudu и где это используется Распределенная...

Сегодня поговорим про еще один open-source проект от Apache Software Foundation – Bigtop, который позволяет собрать и протестировать собственный дистрибутив Hadoop или другого Big Data фреймворка, например, Greenplum. Читайте в нашей статье, что такое Apache Bigtop, как работает этот инструмент, какие компоненты он включает и где используется на практике. Что...

Продолжая разговор про успехи применения отечественных Big Data продуктов, сегодня мы рассмотрим пример использования Arenadata DB в одной из ведущих отечественных компаний розничного ритейла. Читайте в нашей статье про особенности внедрения распределенной отказоустойчивой MPP-СУБД для аналитики больших данных в Х5 Retail Group. Зачем ритейлеру еще одно Big Data решение: специфика...

Однажды мы уже рассматривали, зачем Apache Kafka, Hadoop, HBase и другие Big Data системы используют Zookeeper, почему он необходим в распределенных проектах и чем можно заменить его заменить. Сегодня поговорим о том, как работает этот популярный централизованный сервис для поддержки информации о конфигурации, именования, обеспечения синхронизации распределенных приложений и предоставления...
Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...
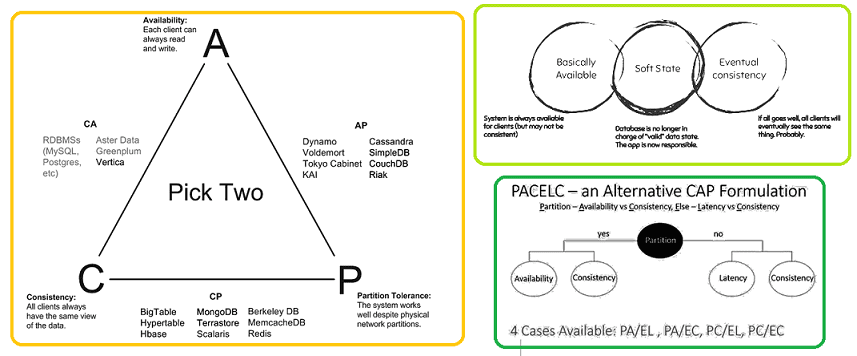
В этой статье мы расскажем про краеугольный камень распределенных Big Data систем – CAP-теорему, в которой одновременно возможно реализовать только 2 свойства из 3-х, по аналогии с треугольником ограничений в проектном менеджменте «Быстро-Качественно-Дешево». Также рассмотрим, за что критикуют модель CAP и почему современные NoSQL-СУБД стоит рассматривать с позиций BASE и...

Рассмотрев ключевые сходства и различия Cassandra и HBase, сегодня мы поговорим, в каких случаях стоит выбирать ту или иную нереляционную СУБД для обработки больших данных (Big Data) в NoSQL-хранилище. Где используются NoSQL-СУБД в Big Data Прежде всего отметим основные области применения рассматриваемых нереляционных СУБД. Проанализировав наиболее известные примеры использования (use...

Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...
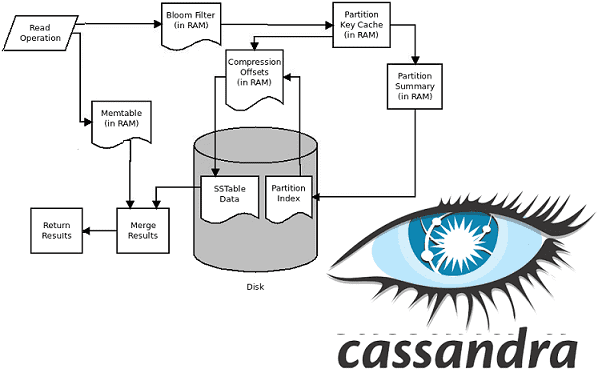
В прошлой статье мы разобрали, как настраиваемые уровни согласованности влияют на скорость работы с данными в Apache Cassandra. Сегодня поговорим, как в этой нереляционной базе данных выполняются операции записи, чтения, уплотнения и удаления. Читайте в нашей статье, что такое memTable, SSTable и Bloom-фильтр, благодаря которым рассматриваемая распределенная NoSQL-СУБД может обработать...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...

Сегодня мы рассмотрим еще один инструмент стека SQL-on-Hadoop: Apache Phoenix, позволяющий выполнять SQL-запросы к нереляционной СУБД HBase. Читайте в нашей статье, что представляет собой этот исполнительный механизм, как он работает и чем отличается от других Big Data решений подобного класса (Cloudera Impala, Apache Hive и Drill). Также мы собрали для...

Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
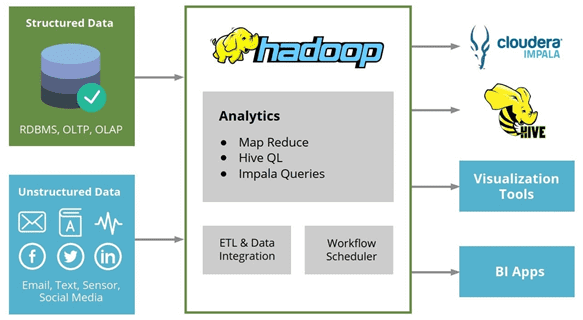
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...