
Недавно мы рассматривали, как повысить производительность конвейеров Apache Spark и повысить скорость распределенных приложений для аналитики больших данных. Сегодня разберемся, почему тормозят отдельные Spark-задачи и как их ускорить. Читайте далее про инициализацию Спарк-контекста, предзагрузку артефактов и применение клиентского режима. Почему некоторые задачи в быстром Apache Spark выполняются так медленно Напомним,...

В заключение цикла статей о сравнении Apache Kafka с Pulsar, сегодня мы перечислим, когда следует предпочесть второй вариант для построения распределенных масштабируемых систем потоковой аналитики больших данных. Также читайте далее, с какими ограничениями придется мириться в случае выбора этого Big Data фреймворка. 5 случаев, когда Apache Pulsar лучше Kafka При...

Вчера мы опровергали мифы о превосходстве молодого Apache Pulsar над зрелой Kafka, наглядно показав, что именно второй Big Data фреймворк больше подходит для построения по-настоящему масштабных и высоконадежных распределенных масштабируемых систем потоковой аналитики больших данных. Тем не менее, благодаря своим архитектурным особенностям Pulsar постепенно завоевывает собственную нишу и становится все...

Оставив за рамками этой статьи бенчмаркинговые войны по оценке производительности Apache Pulsar в сравнении с Kafka и RabbitMQ, сегодня разберем 5 популярных мифов о превосходстве молодого Пульсар над зрелой Кафка – платформой потоковой обработки событий с точки зрения администрирования и эксплуатации. Читайте далее, правда ли управлять кластером Pulsar проще, чем...

Продолжая разбирать сходства и различия Apache Pulsar с Kafka и RabbitMQ, сегодня попытаемся выяснить, какой Big Data фреймворк все-таки лучше: погрузимся в особенности бенчмаркинговых исследований, сравнивающих эти платформы. Читайте далее, почему не стоит безоговорочно доверять локальным бенчмаркинг-тестам оценки производительности и какие факторы действительно нужно учитывать при выборе фреймворка для разработки...

Недавно мы разбирали, что такое Apache Pulsar: архитектуру, принципы работы, сходства и различия с Kafka и RabbitMQ. В продолжение этого разговора, сегодня рассмотрим основные мифы и их опровержения в горячем споре о технологиях Big Data. Читайте далее про холивар Apache Kafka vs Pulsar vs RabbitMQ: что лучше выбрать для построения...

Продвигая наши обновленные курсы по Kafka, сегодня рассмотрим, почему в последнее время эту Big Data платформу потоковой обработки событий стали активно сравнивать с Apache Pulsar. Читайте далее, как устроен этот молодой, но интересный фреймворк потоковой обработки больших данных, чем он отличается от Kafka и RabbitMQ, что между ними общего и...

Вчера мы говорили про сложности развертывания множества stateful-приложений Apache Kafka Streams в кластере Kubernetes и роль контроллера StatefulSet, который поддерживает состояние реплицированных задач за пределами жизненного цикла отдельных подов. В продолжение этой темы, сегодня рассмотрим механизм проб, которые позволяют определить состояние распределенного приложения, развернутого на платформе контейнерной виртуализации. В качестве...
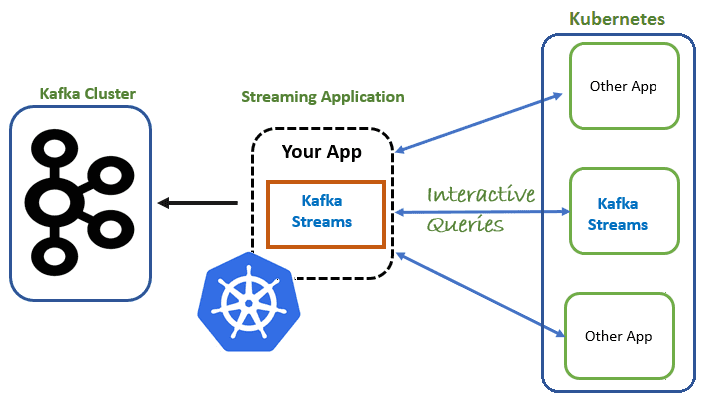
Сегодня рассмотрим особенности запуска приложений Apache Kafka Streams для потоковой обработки больших данных с отслеживанием состояния в кластере Kubernetes. Читайте далее, в чем проблема управления stateful-приложениями Kafka Streams в Kubernetes и как ее решает контроллер StatefulSet. Что обеспечивает хранение состояний в Apache Kafka Streams Напомним, Kafka Streams – это легковесная...
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud. Постановка задачи: CDC с Big Data в реальном времени Рассмотрим кейс, который часто...

Вчера мы говорили про ускорение аналитики больших данных в конвейере из множества заданий Apache Spark. Продолжая речь про обучение инженеров данных, сегодня рассмотрим, как снизить стоимость выполнения Spark-приложений, сократив накладные расходы на обработку Big Data и повысив эффективность использования кластерной инфраструктуры. Экономика Big Data систем: распределенная разработка и операционные затраты...

Сегодня рассмотрим несколько простых способов ускорить обработку больших данных в рамках конвейера задач Apache Spark. Читайте далее про важность тщательной оценки входных и выходных данных, рандомизацию рабочей нагрузки Big Data кластера и замену JOIN-операций оконными функциями. Оптимизируй это: почему конвейеры аналитической обработки больших данных с Apache Spark замедляются Обычно со...

В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

В конце 2020 года вышел мажорный релиз Apache AirFlow, основные фишки которого мы рассмотрим в этой статье. Читайте далее про 10 главных обновлений Apache AirFlow 2.0, благодаря которым этот DataOps-инструмент для пакетных заданий обработки Big Data стал еще лучше. 10 главных обновлений Apache AirFlow 2.0 Напомним, разработанный в 2014 году...

Недавно мы уже рассматривали выполнение Join-операций в Apache Spark SQL. Сегодня поговорим про особенности потокового соединения в модуле Structured Streaming этого популярного фреймворка аналитики больших данных. Читайте далее, в чем специфика внешних и внутренних соединений потоков Big Data в Apache Spark Structured Streaming, а также как и зачем Inner/Outer Join...

Отвечая на вопрос, что такое большие данные для чайников, сегодня мы рассмотрим 3 практических примера использования технологий Big Data в малом и среднем бизнесе. Никакой Rocket Science, только понятные кейсы, которые актуальны для любой современной компании, даже если она состоит из пары человек: аналитика больших данных и машинное обучение для...

Совместное использование Apache Kafka и Spark очень часто встречается в потоковой аналитике больших данных, например, в прогнозировании пользовательского поведения, о чем мы рассказывали вчера. Однако, временные метки (timestamp) в приложении Spark Structured Streaming могут отличаться от времени события в топике Kafka. Читайте далее, почему это случается и какие подходы к...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
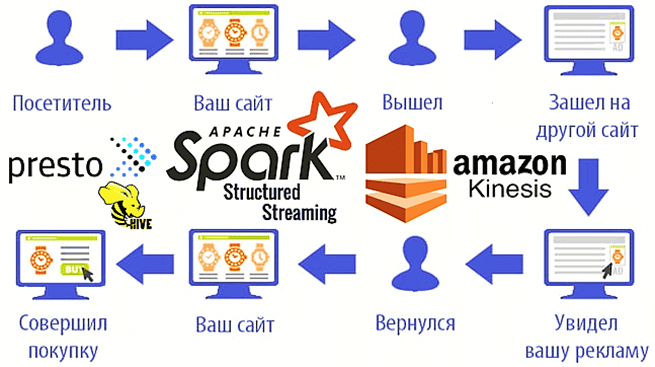
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...