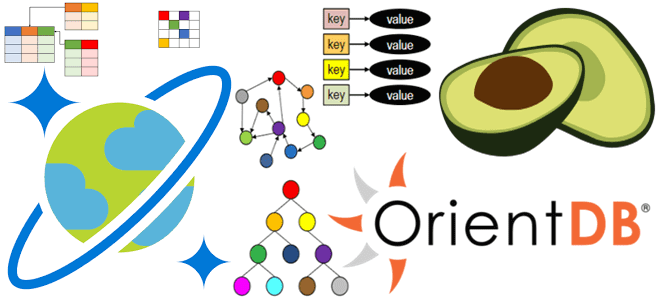
Как устроены по-настоящему мультимодельные базы данных, чем они отличаются от реляционных и NoSQL-СУБД, а также какова истинная природа универсального подхода к хранению и оперированию данными. Разбираемся на примере ArangoDB, OrientDB и Cosmos DB. Что такое мультимодельная СУБД и зачем она нужна Любая технология предназначена, прежде всего, для решения конкретных проблем,...
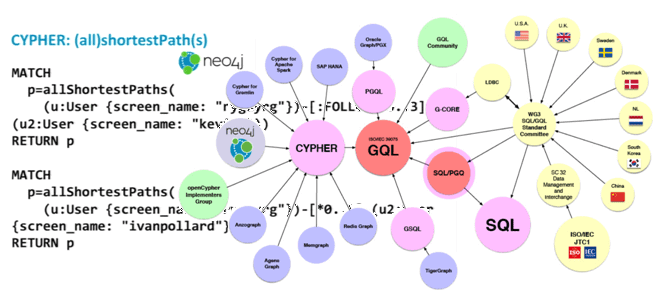
Кто и зачем создает аналог SQL для запросов к графовым базам данных, когда выйдет официальная версия стандарт и при чем здесь Cypher из Neo4j. Что такое GQL и кто его разрабатывает В рамках продвижения нашего курса по графовым алгоритмам в бизнес-приложениях мы часто рассказываем про инструменты хранения и анализа графовых...
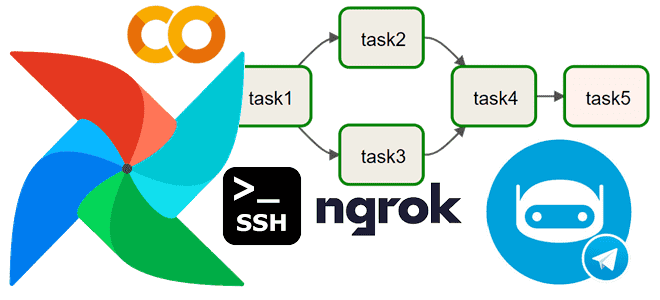
В этой статье рассмотрим, как добавить собственное соединение в Apache AirFlow, запустив его в интерактивной среде Colab с помощью Python-кода, и использовать его при отправке результатов выполнения задач DAG в свой чат-бот Телеграм. Постановка задачи: DAG с отправкой данных в Телеграм Недавно я подробно рассказывала, как настроить AirFlow в Google...
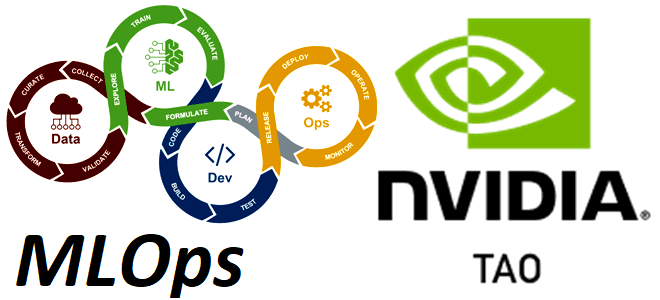
Сегодня познакомимся с набором инструментов TAO Toolkit от NVIDIA на основе TensorFlow и PyTorch, который позволяет получить эффективный рабочий процесс с помощью лучших практик MLOps и возможностей трансферного обучения за счет оптимизации тренировки модели и ее пропускной способности для логического вывода на целевой платформе. Что такое TAO Toolkit от NVIDIA...
Почему запросы Flink SQL перестают работать эффективно при больших объемах несбалансированном распределенных данных и как это исправить с помощью мини-пакетной агрегации. Что такое MiniBatch, как это работает и чем может опасно. Перекос данных по ключу группировки в Apache Flink Flink SQL — это мощный инструмент, объединяющий пакетную и потоковую обработку...
Как кодек сжатия snappy может вызвать ошибку нехватки памяти на брокерах, что может нарушить пользовательская JAAS-конфигурация клиента с протоколом безопасности на основе SASL и еще 4 уязвимости Apache Kafka в 2023 и 2022 гг. Уязвимости Apache Kafka 2023 года В 2023 году обнаружена уязвимость CVE-2023-34455, связанная с тем, что клиенты,...

23 июня 2023 года опубликован очередной релиз Apache Spark 3.4.1, который считается отладочным выпуском для предыдущего, содержащий исправления стабильности. Помимо исправления ошибок, в нем также 16 новых фичей и более 20 улучшений, самые главные из которых мы рассмотрим далее. Исправления ошибок и новые фичи Apache Spark 3.4.1 Поскольку выпуск считается...
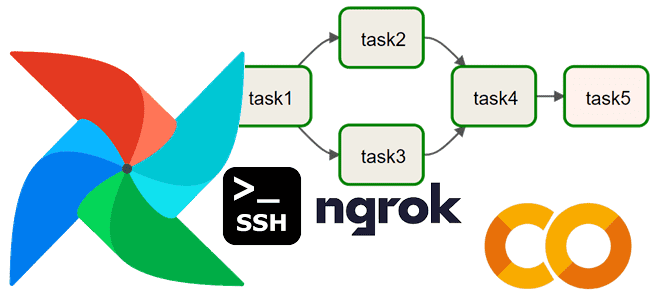
Сегодня рассмотрим, как выполнить DAG Apache AirFlow, запустив его в интерактивной среде Colab и получив доступ в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. В качестве примера построим простой конвейер из 5 задач. Запуск Apache AirFlow в Google Colab Чтобы не повторять содержимое...

Зачем биомедикам понадобился свой язык описания онтологий, как эти задачи решает BioCypher и при чем здесь Neo4j: практическое приложение Data Science и графовых алгоритмов в биомедицинской сфере. Что такое BioCypher Графовые алгоритмы активно применяются в биомедицине для анализа различных биологических данных, таких как геномные, протеомные, данные о белковых взаимодействиях и...
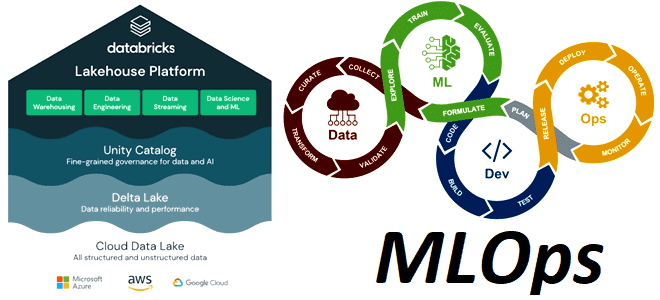
Мы уже писали, какие инструменты пригодятся MLOps-инженеру для развертывания моделей машинного обучения в производственных средах. Сегодня рассмотрим, как сделать это, используя MLOps-паттерны и средства платформы Databricks Lakehouse. MLOps в production: шаблоны развертывания на платформе Databricks MLOps представляет собой набор лучших практик и инструментов для автоматизации управления кодом, данными и моделями,...

15 июня 2023 года опубликован очередной выпуск самой популярной распределенной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.5.0, особенно важными для разработчиков, дата-инженеров и администраторов кластера. Обновления брокеров, контроллеров, продюсеров и потребителей Релиз Apache Kafka 3.5.0 богат на новинки: в нем 50 улучшений и почти 80 исправленных ошибок....
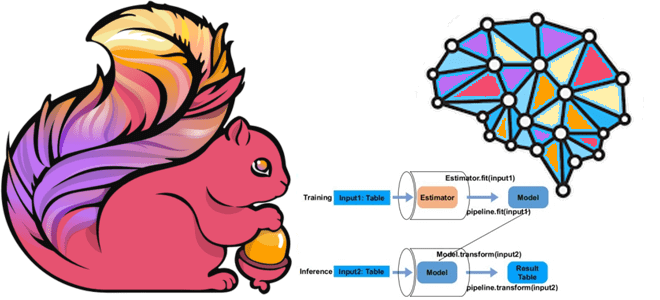
Как построить конвейер машинного обучения с помощью библиотеки Flink ML, из каких компонентов она состоит и как работает, а также что позволяет объединить алгоритмы потоковой обработки данных Apache Flink с ML-моделями. Что такое Flink ML Помимо MLeap, библиотеки сериализации для моделей машинного обучения, Apache Flink также включает Flink ML —...

Как расширить возможности MPP-СУБД Greenplum, используя фоновые рабочие процессы и почему это небезопасно. А также рассмотрим, что такое API Greenplum Partner Connector и как это использовать. Фоновые рабочие процессы Обычно фоновыми процессами в СУБД называются системные задания, которые запускаются при запуске базы данных и выполняют различные служебные задачи. К таким рутинным сервисным задачам...
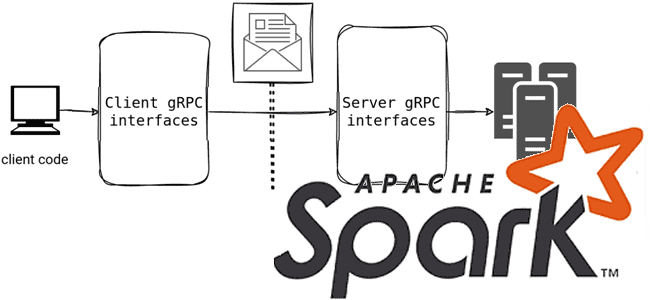
Мы уже писали, что в выпуске 3.4.0 от апреля 2023 года Spark Connect представил несвязанную архитектуру клиент-сервер, которая обеспечивает удаленное подключение к кластерам Spark из любого приложения, работающего в любом месте. Сегодня рассмотрим подробнее, как это работает и каковы плюсы для практического использования. Что такое Spark Connect и зачем это...
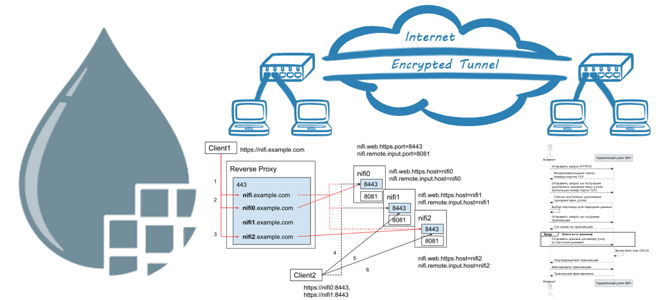
Будучи распределенным ETL/ELT-инструментом потоковой передачи данных, Apache NiFi имеет соответствующие средства, которые обеспечивают взаимодействия между разными узлами кластера. Одним из них является протокол Site-to-Site (S2S), с которым мы познакомимся далее. Что такое протокол S2S При отправке данных из одного экземпляра NiFi в другой можно использовать множество различных протоколов, наиболее предпочтительным...

Формат данных в озере или гибридном хранилище типа Data LakeHouse сильно влияет на скорость выполнения аналитических запросов. Сегодня рассмотрим, как Apache CarbonData делает аналитику больших данных в реальном времени еще быстрее. Что такое Apache CarbonData Традиционные форматы данных, часто используемые в проектах Big Data, такие как CSV и AVRO, имеют...

Сегодня рассмотрим, как запустить Apache AirFlow на мощностях Google в интерактивной среде Colab и войти в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. Запуск Apache AirFlow в Google Colab Хотя Google Colab является мощным облачным окружением для запуска и написания Python-кода, выполнение написанных...
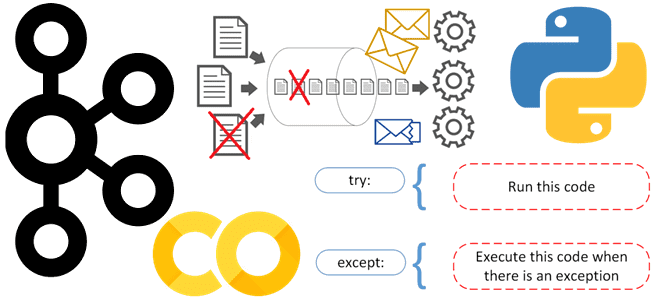
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...
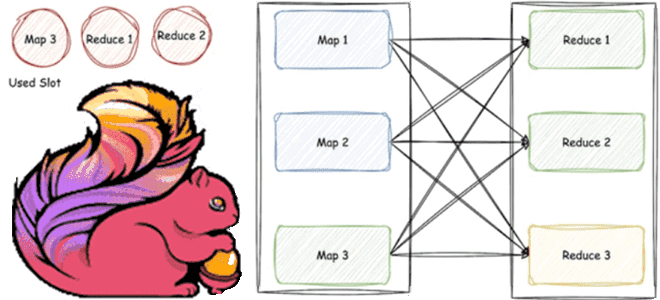
Что не так с планированием задач shuffle-операций, какие проблемы пакетной обработки данных устраняет введение гибридной перетасовки в Apache Flink 1.16 и как работает этот режим Hybrid Shuffle. Что такое режим гибридного перемешивания в Apache Flink В версии Apache Flink 1.16, о которой мы писали здесь, был впервые представлен режим гибридной...

Сегодня заглянем внутрь Neo4j, чтобы разобраться с базовыми концепциями этой графовой базы данных. Какие уровни изоляции транзакций поддерживаются в Neo4j, почему одна установка по умолчанию содержит две базы данных, что такое составная БД и как с этим работать. Транзакции в Neo4j Neo4j — это популярная нативная графовая СУБД, способная управлять...