 544
544 
Содержание
- Введение в мир машинного понимания текста
- Развенчиваем мифы о NLP и блокчейне
- Базовые подходы к разбиению текста
- Пословная токенизация
- Символьная токенизация
- Сабворд токенизация
- Главные алгоритмы обработки текста
- Алгоритм Byte Pair Encoding
- Алгоритм WordPiece
- Алгоритм SentencePiece
- Анатомия LLM почему токены так важны сегодня
- Контекстное окно и бюджет
- Баги алгоритмов разбиения
- Практика пишем код на Python для демонстрации токенизации
- Классический подход с NLTK
- Продвинутая обработка с Hugging Face
- Заключение
- Референсные ссылки
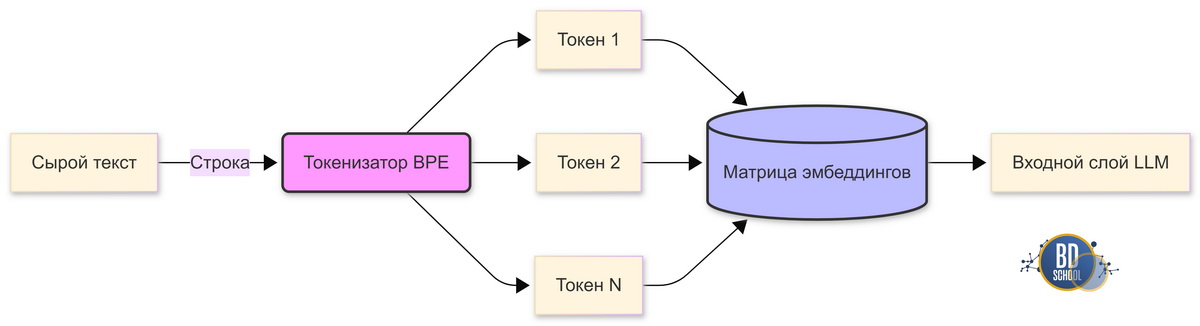
Токенизация (tokenization) — это процесс разбиения текста на минимальные смысловые единицы (токены), такие как слова, подслова или символы, используемые для последующей обработки и анализа в задачах обработки естественного языка. Эти базовые фрагменты называются токенами. В качестве такого элемента может выступать целое слово. Иногда алгоритм выделяет отдельный слог или морфему. Часто в роли базовой единицы выступает одиночный символ. Это самый первый этап подготовки данных в машинном обучении. Данный шаг критически важен для обработки информации. Он необходим для перевода человеческого языка в математический формат. Без этой процедуры не работает ни одна современная языковая модель.
Компьютеры совершенно не понимают обычные буквы. Они умеют вычислять только числовые матрицы и векторы. Поэтому любой входящий текст необходимо предварительно преобразовать. Слова нужно превратить в понятные алгоритму числовые значения. Именно здесь на сцену выходит механизм разбиения текста. Это надежный мост между человеческой речью и строгой математикой.
Введение в мир машинного понимания текста
Давайте детально разберемся в базовых понятиях обработки естественного языка. Исходный текст для вычислительной машины представляет собой просто длинную строку. Нам нужно аккуратно разбить эту текстовую строку на осмысленные атомы. Затем каждый уникальный атом получает свой строгий порядковый номер.
Этот уникальный идентификатор берется из заранее составленного системного словаря. Нейросеть получает на вход готовую последовательность этих номеров. В результате сложный алгоритм видит не привычный нам текст. Он видит многомерную и сложную математическую структуру. Следовательно, качество исходного разбиения прямо влияет на будущий интеллект модели. Плохое разбиение текста гарантированно приведет к глупым ответам алгоритма. Хорошее разделение поможет модели уловить тончайшие смысловые связи.
Развенчиваем мифы о NLP и блокчейне
Новички часто путаются в современной технической терминологии. Одно популярное слово звучит абсолютно одинаково в разных сферах IT. Однако технический смысл этого термина кардинально отличается в зависимости от контекста. Мы кратко рассмотрим основные различия этих популярных концепций.
- В машинном обучении это строгое разбиение текста на фрагменты.
- В банковской сфере это замена данных карты на безопасный код.
- В блокчейне это технический выпуск нового цифрового актива.
Разница между этими технологиями весьма существенная и понятная. В рамках данной статьи мы говорим исключительно про обработку текстов. Финансовые и криптографические технологии мы полностью оставляем за кадром. Нас интересует только грамотная подготовка данных для искусственного интеллекта.
Базовые подходы к разбиению текста
Индустрия машинного обучения прошла очень долгий и сложный путь. Подходы к подготовке текстовых данных постоянно эволюционировали вместе с мощностью компьютеров. Изначально исследователи пробовали применять самые простые и очевидные пути. Мы детально рассмотрим три исторически значимых метода обработки данных.
Пословная токенизация
Это самый старый и очевидный способ разделения любого предложения. Алгоритм просто ищет пробелы и стандартные знаки препинания в строке. В результате каждое отдельное слово становится самостоятельным независимым атомом. У этого классического метода есть четкие плюсы и минусы.
- Понятный любому человеку базовый принцип работы алгоритма.
- Сохранение цельного исходного смысла каждого отдельного слова.
- Огромный размер итогового словаря из-за различных падежей и склонений.
- Постоянная проблема неизвестных слов при встрече редких терминов.
В итоге системный словарь быстро разрастается до сотен тысяч элементов. Нейросети становится слишком тяжело хранить математические связи между таким количеством слов. Поэтому сегодня этот устаревший подход практически не используется инженерами в чистом виде.
Символьная токенизация
Инженеры решили пойти от обратного для решения проблемы огромного словаря. Они попробовали радикально разбить текст на самые мелкие возможные детали. В этом конкретном случае базовым атомом становится каждая отдельная буква. Это решение очень элегантно устранило проблему слишком огромных словарей.
- Общий словарь радикально сокращается до нескольких десятков базовых символов.
- Полностью исчезает неприятная проблема неизвестных алгоритму новых слов.
- Нейросеть вынуждена самостоятельно изучать сложные правила составления слов.
- Окно контекста заполняется невероятно быстро из-за обилия мелких деталей.
Этот радикальный метод на практике оказался слишком ресурсоемким и неэффективным. Модели тратили непозволительно много вычислительных ресурсов на понимание самых простых слов. Смысловая нагрузка одной буквы слишком мала для быстрого и качественного обучения.
Сабворд токенизация
Исследователи стали активно искать золотую середину между двумя крайними подходами. Им был жизненно нужен грамотный компромисс между словами и отдельными буквами. Так появилась гениальная идея делить текст на составные части слов. Этот продвинутый подход сегодня называется сабворд-разбиением.
- Часто встречающиеся слова остаются в системном словаре совершенно целыми.
- Редкие и сложные слова разбиваются на логические приставки и корни.
- Максимальный размер словаря жестко фиксируется программистами заранее при обучении.
- Модель может легко понять незнакомое слово по его известным частям.
Сегодня это абсолютный и непререкаемый индустриальный стандарт во всем мире. Именно так работают абсолютно все передовые языковые алгоритмы на планете. Этот современный подход идеально балансирует между вычислительной эффективностью и смысловой нагрузкой.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Главные алгоритмы обработки текста
Существуют разные программные способы реализации сабворд-разбиения на практике. Крупные технологические компании годами разрабатывали свои уникальные математические алгоритмы для токенизации. Они тщательно оптимизировали внутреннюю логику под разные архитектуры глубоких нейросетей. Мы подробно изучим три самых важных алгоритма современности.
Алгоритм Byte Pair Encoding
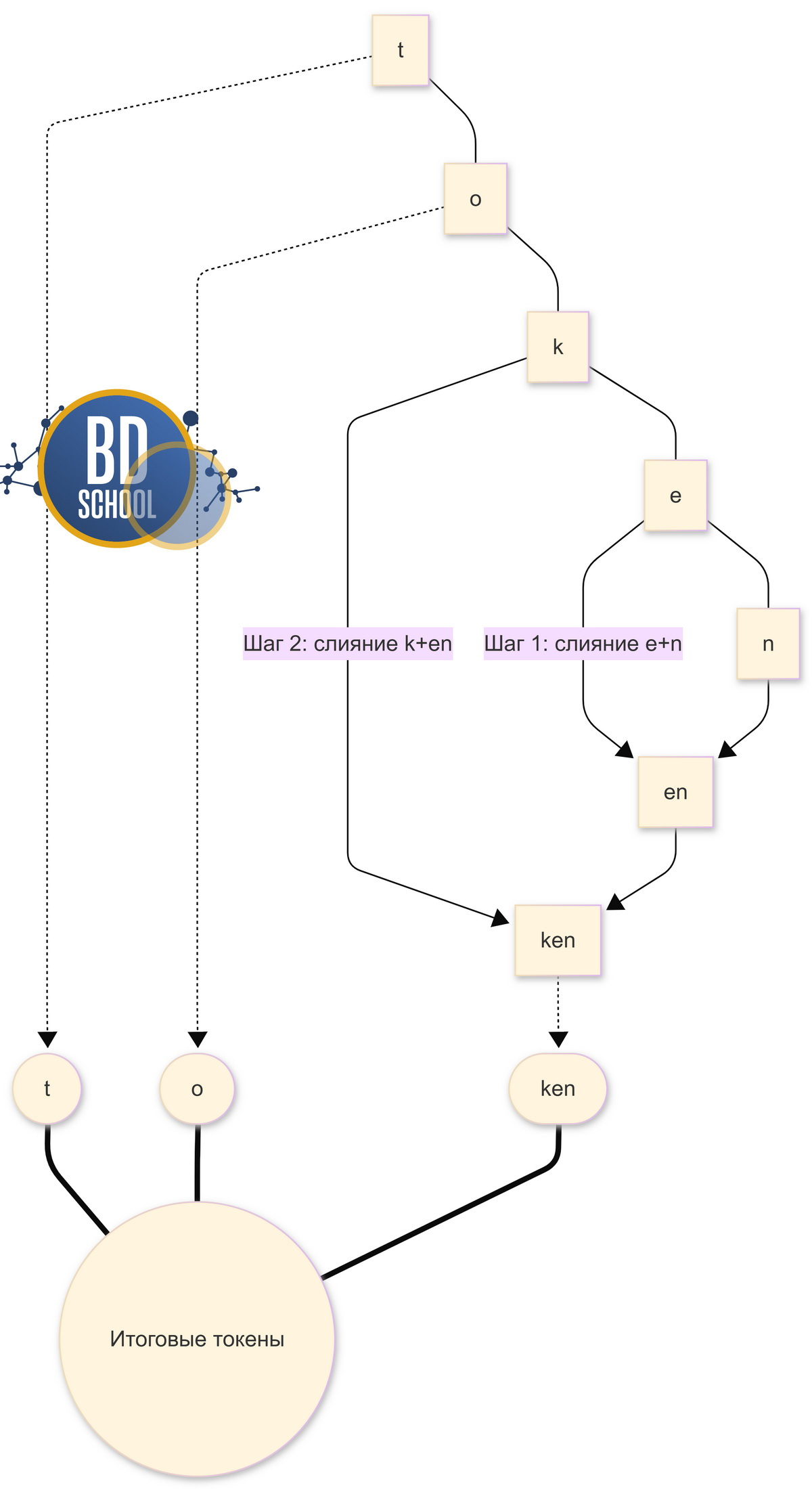
Этот невероятно популярный метод пришел в NLP из систем сжатия данных. Его английская аббревиатура звучит как BPE. Изначально этот алгоритм просто искал часто повторяющиеся пары байтов в файлах. Затем умные исследователи успешно адаптировали его для обработки обычных текстов. Алгоритм токенизациия берет отдельные базовые символы и начинает их последовательно объединять. Он ищет пары символов, которые чаще всего стоят рядом в обучающем корпусе. Затем он навсегда сливает их в один новый неделимый символ — токен. Данный процесс циклично повторяется тысячи раз до достижения жесткого лимита словаря. Именно этот эффективный метод лежит в основе всех популярных генеративных моделей.
Алгоритм WordPiece
Этот мощный метод был разработан талантливыми инженерами корпорации Google. Он концептуально очень сильно похож на предыдущий рассмотренный нами алгоритм. Однако здесь используется совершенно другая математическая логика финального слияния символов. Модель оценивает не просто банальную частоту появления парных символов в тексте. Она строго оценивает вероятность повышения языковой ценности при их математическом слиянии. Если объединение символов улучшает предсказательную способность алгоритма, они немедленно сливаются. В противном случае эти символы навсегда остаются раздельными в базе данных. Именно этот продвинутый алгоритм подарил нашему миру знаменитую архитектуру трансформеров.
Алгоритм SentencePiece
Предыдущие методы очень сильно и критично зависят от наличия пробелов. Они всегда считают классический пробел жесткой границей между разными словами. Однако далеко не все языки мира используют такие разделители. Например, китайский или японский языки исторически строятся по совершенно другим правилам. Поэтому был создан этот полностью универсальный и независимый метод обработки. Он воспринимает абсолютно весь исходный текст как единый непрерывный поток символов. Пробел в нем считается самым обычным рядовым символом текста. Это блестяще позволяет алгоритму работать с любыми языками без предварительной сложной очистки.
Анатомия LLM почему токены так важны сегодня
Обычные пользователи часто совершенно не понимают внутреннюю экономику современных нейросетей. Они привыкли традиционно измерять тексты в печатных страницах или тысячах знаков. Однако провайдеры искусственного интеллекта считают вычислительные объемы совершенно иначе. Мы подробно разберем, почему фрагменты текста стали главной цифровой валютой современности.
Контекстное окно и бюджет
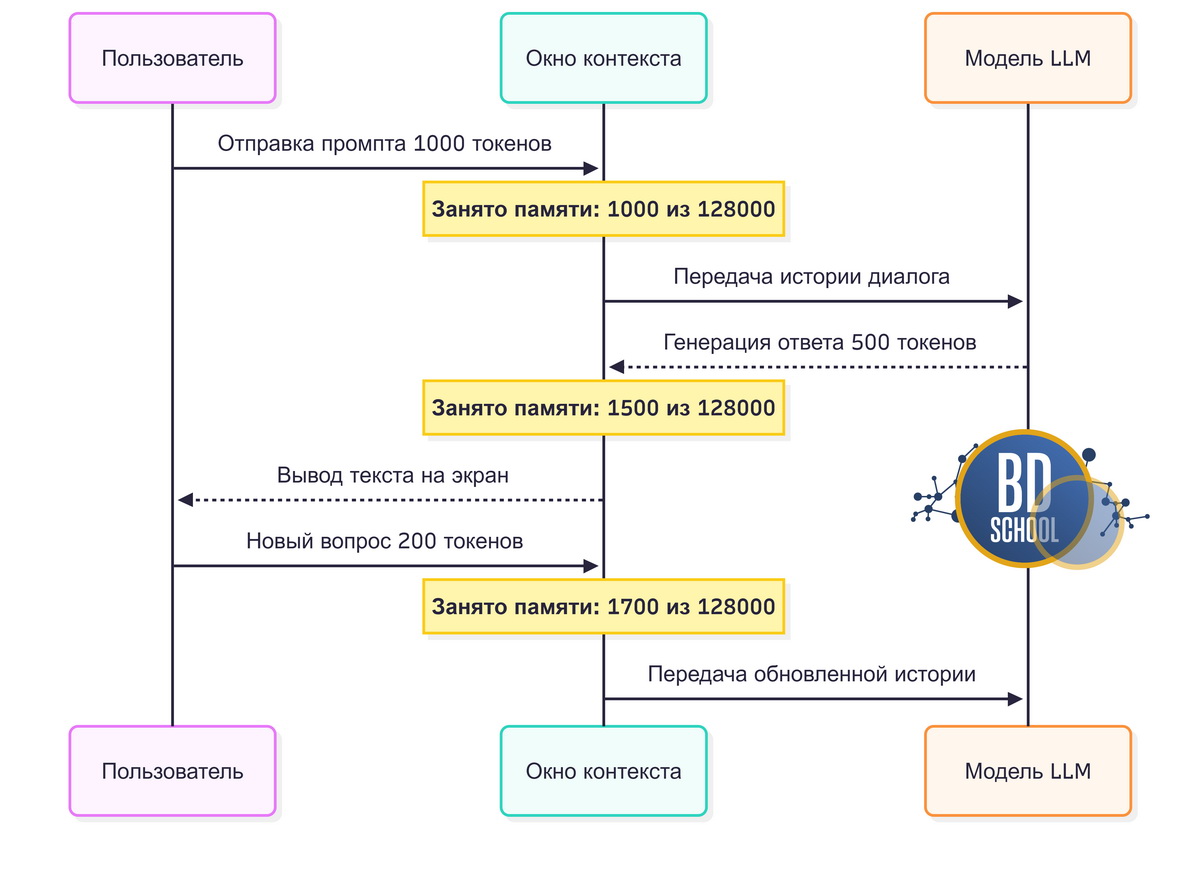
Каждая языковая нейросеть имеет строго ограниченный объем быстрой оперативной памяти. Этот фиксированный объем традиционно называется окном контекста языковой модели. Оно всегда измеряется инженерами строго в количестве базовых структурных элементов. Рассмотрим ключевые особенности и правила работы этой важной метрики.
- Русский текст часто требует больше элементов разбиения из-за особенностей кириллицы.
- Английский текст обычно более компактен для встроенного словаря нейросети.
- Оплата по API всегда рассчитывается разработчиками за количество переданных нейросети фрагментов.
- Превышение установленного лимита окна неизбежно приводит к потере начала текущего диалога.
Поэтому грамотные разработчики всегда стараются тщательно оптимизировать свои системные промпты. Меньшее количество передаваемого текста очень серьезно экономит бюджет любого IT-проекта. Кроме того, компактный текстовый запрос значительно ускоряет итоговый ответ облачного сервера.
Баги алгоритмов разбиения
Внутренняя архитектура алгоритмов часто порождает весьма забавные проблемы взаимодействия с пользователем. Мощные современные нейросети часто выглядят откровенно глупыми в самых простых задачах. Это происходит именно из-за специфического способа аппаратного чтения исходного текста. Языковая модель видит не отдельные буквы, а целые готовые куски слов.
Поэтому она физически не может правильно сосчитать буквы внутри этого монолитного куска. Также она очень плохо играет в детские игры по первым буквам слов. Ей невероятно сложно программно перевернуть длинное слово задом наперед. Все эти странности вызваны исключительно внутренним математическим разбиением исходного текста. Алгоритм просто не имеет прямого доступа к отдельным символам введенного слова.
Практика пишем код на Python для демонстрации токенизации
Любая сложная техническая теория всегда должна подкрепляться реальной инженерной практикой. Специалисты по данным постоянно используют готовые открытые библиотеки для повседневной работы. Мы напишем простой и понятный программный код для двух разных подходов. Это обязательно поможет читателю гораздо лучше понять техническую реализацию описанного процесса токенизации.
Классический подход с NLTK
Библиотека NLTK заслуженно считается нестареющей классикой базового анализа текстовых данных ( мы уже о ней писали и не раз). Она просто отлично подходит для простых академических и начальных учебных задач. Мы реализуем базовое программное разбиение короткого предложения на отдельные смысловые слова.
# Импортируем нужный инструмент из базовой библиотеки
from nltk.tokenize import word_tokenize
import nltk
# Загружаем языковую модель для корректной работы алгоритма
nltk.download('punkt_tab')
# Создаем исходный текст для нашего простого анализа
text_data = "Изучать машинное обучение очень интересно!"
# Выполняем простое пословное разбиение введенного текста
tokens_result = word_tokenize(text_data)
# Выводим финальный результат работы алгоритма на экран
print(tokens_result)
# Вывод будет таким: ['Изучать', 'машинное', 'обучение', 'очень', 'интересно', '!']

Этот очень простой код работает на любом домашнем компьютере невероятно быстро. Однако он категорически не подходит для современных тяжелых и сложных языковых нейросетей. Он создает слишком много уникальных смысловых элементов для большой математической модели.
Нейронные сети на Python
Код курса
PYNN
Ближайшая дата курса
12 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Продвинутая обработка с Hugging Face
В реальных коммерческих IT-проектах всегда используются передовые библиотеки от создателей моделей. Самой популярной облачной платформой сегодня является портал Hugging Face. Мы загрузим реальный рабочий алгоритм от современного популярного текстового трансформера для примера работы с токенизацией.
Не забудьте установить необходимые пакет в venv

# Импортируем класс для работы с алгоритмом современного трансформера
from transformers import AutoTokenizer
# Загружаем готовый инструмент из облачного публичного репозитория модели
# Мы используем популярную легкую модель известного семейства BERT
tokenizer_tool = AutoTokenizer.from_pretrained("bert-base-multilingual-cased")
# Создаем технически сложный текст на родном русском языке
complex_text = "Нейротрансформеры меняют индустрию."
# Преобразуем исходный текст в строгий многомерный математический формат
encoded_data = tokenizer_tool(complex_text)
# Смотрим на полученные внутренние числовые идентификаторы словаря
print("Идентификаторы:", encoded_data["input_ids"])
# Восстанавливаем текст для проверки качества внутреннего разбиения
decoded_tokens = tokenizer_tool.convert_ids_to_tokens(encoded_data["input_ids"])
print("Текстовые части:", decoded_tokens)

Здесь мы наглядно видим реальную практическую работу передового сабворд-разбиения. Сложные и редкие слова будут аккуратно разделены алгоритмом на приставки и корни. Нейросеть мгновенно получит готовый массив правильных и понятных ей чисел. Это абсолютная основа современной повседневной работы с любым искусственным интеллектом.
Заключение
Мы очень подробно разобрали важнейший базовый механизм современного машинного обучения. Преобразование текста в числа напрямую определяет итоговое качество работы любых нейросетей. Алгоритмы BPE и WordPiece стали настоящим золотым стандартом современной IT-индустрии. Они элегантно и эффективно решили сложнейшую проблему неизвестных слов и огромных словарей.
Инженеры по всему миру продолжают активно улучшать эти технологии каждый день. Возможно, будущие поколения алгоритмов научатся эффективно работать напрямую с сырыми байтами. Однако сегодня глубокое понимание сабворд-разбиения остается критически важным техническим навыком. Это абсолютно базовая компетенция любого уважающего себя специалиста по большим данным.
Референсные ссылки
-
Neural Machine Translation with Subword Units. Базовое исследование Рико Сеннриха. Здесь впервые описано успешное применение алгоритма BPE для языковых задач.
-
Документация Hugging Face Transformers. Официальное руководство по программному модулю PreTrainedTokenizer. Внутри очень подробно описана логика работы со словарями нейросетей.
-
Исходный репозиторий проекта SentencePiece. Открытый код мощного универсального токенизатора от инженеров корпорации Google. Желающие могут дополнительно изучить оригинальную статью создателей алгоритма.