Apache KNOX - REST API и шлюз приложений для компонентов экосистемы Apache Hadoop, обеспечивает единую точку доступа для всех HTTP соединений с кластерами Apache Hadoop и систему единой аутентификации Single Sign On (SSO) для сервисов и пользовательского интерфейса компонент Apache Hadoop. В сочетании с средствами сетевой изоляции и аутентификацией Kerberos, KNOX...
KSQL - это движок SQL для Apache Kafka, который может использоваться для анализа данных в режиме реального времени с использованием операторов SQL вместо написания большого количества кода на Java. KSQL, построенный на основе API Kafka Streams, поддерживает операции обработки потоков, такие как фильтрация, преобразования, агрегации, соединения, оконные операции и сессии....

ksqlDB – это база данных потоковой передачи событий, построенная по архитектуре клиент-сервер, которую можно запустить с одним сервером или сгруппировать несколько серверов вместе, чтобы использовать ее API на основе SQL для запроса и обработки данных, хранящихся в топиках Apache Kafka. KsqlDB позволяет выполнять различные операции потоковой аналитики больших данных: фильтрация,...

Kubernetes (K8s) – это программное обеспечение для автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Поддерживает основные технологии контейнеризации (Docker, Rocket) и аппаратную виртуализацию [1]. Зачем нужен Kubernetes Kubernetes необходим для непрерывной интеграции и поставки программного обеспечения (CI/CD, Continuos Integration/ Continuos Delivery), что соответствует DevOps-подходу. Благодаря «упаковке» программного окружения в контейнер,...

Kudu – это колоночное хранилище данных в экосистеме Apache Hadoop, нереляционная СУБД (NoSQL) с открытым исходным кодом от компании Cloudera для оперативной аналитики быстро меняющихся данных в режиме реального времени. Назначение, история разработки и развития Основное назначение Apache Kudu состоит в заполнении аналитического разрыва между 2-мя движками хранения данных Apache...

Lakehouse - это архитектурный подход к хранению и обработке данных, который объединяет гибкость Data Lake и надёжность Data Warehouse, обеспечивая единый слой для аналитики, машинного обучения и управления данными без дублирования. Архитектура Data LakeHouse представляет собой современный подход к управлению данными. Она объединяет лучшие характеристики озер данных (Data Lakes) и корпоративных...
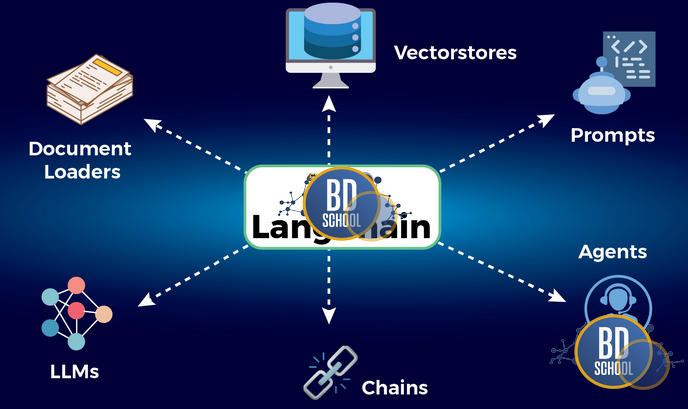
LangChain — это фреймворк с открытым исходным кодом для разработки приложений на базе больших языковых моделей (LLM). Его главная цель — решить фундаментальную проблему изолированности LLM. По умолчанию языковые модели, такие как GPT или Claude, ограничены статичными данными своего обучения. Они не могут получать актуальную информацию из интернета...

Lazy Evaluation (Ленивые вычисления) - это стратегия выполнения программного кода, при которой запуск вычислений откладывается до тех пор, пока их результат не потребуется явно (например, для вывода на экран или сохранения на диск). В экосистеме Big Data (в частности, в Apache Spark) этот подход является фундаментальным: он позволяет...

LLAMA (Large Language Model Meta AI) — это семейство больших языковых моделей, созданное компанией Meta AI. Эти модели являются фундаментальной технологией в области искусственного интеллекта. Они предназначены для понимания и генерации текста, похожего на человеческий. Ключевой особенностью LLAMA стал её открытый подход. Meta предоставила доступ к весам моделей...

LLM (Large Language Model) — это тип системы искусственного интеллекта (ИИ), обученный на огромных объемах текстовых данных для понимания, генерации и прогнозирования человеческого языка с высокой точностью. Эти модели являются основой для множества современных приложений. Они могут писать эссе, переводить языки, отвечать на вопросы и даже создавать программный код. По...

Low Code - это подход к созданию программного обеспечения, который позволяет разрабатывать приложения с минимальным объемом ручного кодирования. Вместо написания тысяч строк кода на языках программирования, Low Code платформы предлагают "визуальный конструктор". Вы "собираете" приложение из готовых блоков, модулей и шаблонов в графическом интерфейсе, используя технологию Drag-and-drop...
LTV (Lifetime Value) — это совокупная прибыль компании, получаемая от одного клиента за все время сотрудничества с ним. Увеличивается при уменьшении уровня оттока клиентов (Churn Rate). Каждая компания стремится увеличить LTV, удерживая клиента с помощью различных мер повышения лояльности (скидки, акции, подарки и пр.), т.к. привлечение нового пользователя обходится в 8-10...

Machine learning - множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить задачу не прямым способом, а на основе поиска закономерностей в разнообразных входных данных. Что такое Machine Learning Общий термин «Machine Learning» или «машинное обучение» обозначает множество математических, статистических и вычислительных методов для разработки алгоритмов, способных решить...

Make, широко известный под своим предыдущим названием Integromat, — это мощная Low-Code платформа для автоматизации рабочих процессов, которая позволяет визуально проектировать, создавать и автоматизировать интеграции между тысячами веб-приложений. Make относится к классу iPaaS (Integration Platform as a Service), но его фундаментальное отличие от многих аналогов заключается в уникальном визуальном...

MapR Convergent Data Platform (MapRCDP) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит Apache Software Foundation, а также средств собственной разработки американской компании MapR для больших данных (Big Data) и машинного обучения (Machine Learning) [1]. Существует три версии MapRCDP: Community Edition (M3) - бесплатная версия сообщества; Enterprise Edition...
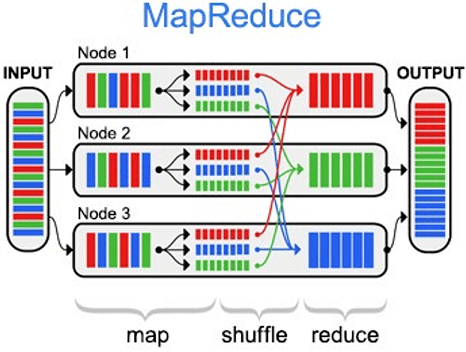
MapReduce – это модель распределённых вычислений от компании Google, используемая в технологиях Big Data для параллельных вычислений над очень большими (до нескольких петабайт) наборами данных в компьютерных кластерах, и фреймворк для вычисления распределенных задач на узлах (node) кластера [1]. Назначение и области применения MapReduce можно по праву назвать главной технологией...
Matplotlib - это фундаментальная библиотека для визуализации данных в языке программирования Python. Это мощный инструмент, позволяющий создавать статические, анимированные и интерактивные графики высокого качества. В мире Data Science она считается стандартом де-факто, на базе которого построены многие современные высокоуровневые инструменты. Если Pandas отвечает за обработку данных, а Scikit-learn...
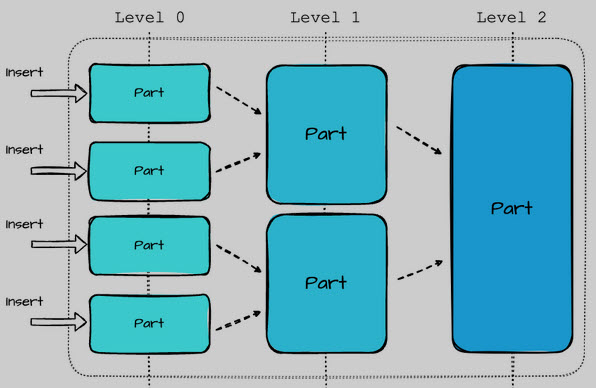
MergeTree – это семейство движков таблиц в ClickHouse, разработанное для хранения данных, отсортированных по первичному ключу. Эти движки обеспечивают высокую производительность для широкого спектра аналитических запросов, поддерживая быструю вставку данных и их последующую фоновую обработку (слияние кусков данных). Семейство MergeTree engine является основой для большинства высоконагруженных задач в ClickHouse. Основные...

Mirror Maker - это инструмент Apache Kafka, предназначенный для реализации зеркального копирования данных внутри брокера. Зеркальное копирование в Kafka подразумевает доступ к записям из разделов основного кластера с целью формирования локальной копии на дополнительном (целевом) кластере. Mirror Maker представляет собой набор потребителей, объединенных в одну группу, которые считывают данные из...

Mixture of Experts (MoE) — это архитектура нейросети, где несколько специализированных моделей-экспертов работают параллельно, но для каждого запроса активируется только часть из них. Это позволяет создавать огромные модели с относительно небольшими вычислительными затратами. Эта архитектура является одним из ключевых "чит-кодов" современного искусственного интеллекта. Она решает фундаментальный парадокс:...