 447
447 
Содержание
- Суть концепции "слабой связанности" простыми словами
- Design for failure и причины выбрать слабую связанность
- Как работает Loosely Coupled архитектура?
- Общение через контракты
- Асинхронность и брокеры сообщений
- Слабая связанность в Data Engineering
- Loosely Coupled в Machine Learning
- Примеры кода на Python
- Визуализация концепций
- Заключение
- Референсы и источники
Cлабая связанность (Loosely Coupled) — это фундаментальный архитектурный паттерн в разработке программного обеспечения. При таком подходе различные компоненты системы обладают минимальным знанием друг о друге. Они обмениваются данными исключительно через строго определенные интерфейсы или сетевые контракты. Разработчики могут свободно изменять внутреннюю логику одного модуля. Это действие совершенно не сломает работу остальных частей большого приложения. Данная концепция является абсолютной основой для создания современных микросервисов и надежных распределенных систем.
Суть концепции «слабой связанности» простыми словами
Давайте разберем этот сложный термин на простом бытовом примере. Представьте старую советскую елочную гирлянду. Все ее лампочки соединены последовательно в одну общую электрическую цепь. Это классический пример жесткой связанности или Tightly Coupled архитектуры. Если перегорает всего одна маленькая лампочка, цепь разрывается. Вся гирлянда мгновенно гаснет. Вы вынуждены тратить часы на поиск неисправного элемента. В программировании монолитные приложения работают точно так же. Ошибка в модуле комментариев может легко обрушить весь новостной портал.
Теперь посмотрим на современную качественную гирлянду. В ней реализовано параллельное подключение всех светящихся элементов. Каждая лампа получает питание абсолютно независимо от своих соседей. Это наглядная иллюстрация Loosely Coupled архитектуры. Если одна деталь выходит из строя, остальные продолжают нормально светить. Вы можете спокойно заменить перегоревшую лампочку прямо во время работы. Система не замечает потери одного бойца.
В современной ИТ-индустрии инженеры мыслят аналогичными категориями. Они намеренно дробят огромный неподъемный код на маленькие независимые блоки. Каждый такой блок выполняет только одну конкретную бизнес-задачу. Программы общаются между собой через универсальные протоколы связи. Внутреннее устройство чужого сервиса скрыто черным ящиком.
Design for failure и причины выбрать слабую связанность
В мире высоких нагрузок идеальных условий просто не существует. Жесткие диски физически выходят из строя. Сетевые маршрутизаторы периодически теряют пакеты данных. Базы данных зависают от наплыва новых пользователей. Здесь на помощь приходит важнейшая инженерная концепция Design for failure. Мы изначально проектируем систему с полным пониманием того, что она обязательно сломается. Архитектура должна уметь выживать в условиях частичной деградации.
Слабая связанность предоставляет инженерам несколько критически важных преимуществ при проектировании.
- Изоляция системных сбоев. Падение платежного шлюза не блокирует работу каталога товаров. Пользователи продолжают добавлять вещи в корзину до восстановления оплаты.
- Независимое масштабирование серверов. Тяжелый сервис аналитики требует мощных процессоров и много памяти. Легкий сервис авторизации обходится минимальными ресурсами. Их можно масштабировать отдельно друг от друга.
- Безопасное обновление логики. Команды разработчиков могут выкатывать новые версии своих микросервисов независимо. Им не нужно синхронизировать релизы с другими отделами компании.
- Упрощение модульного тестирования. QA-инженеры легко изолируют проверяемый компонент от внешнего мира. Они заменяют реальные базы данных легковесными программными заглушками.
Эти факторы критически важны для быстрого развития любого цифрового продукта. Они позволяют бизнесу внедрять новые функции без страха разрушить работающий механизм.
Как работает Loosely Coupled архитектура?
Для реализации слабой связанности недостаточно просто разнести код по разным папкам. Инженер должен грамотно спроектировать каналы связи между компонентами. Существует два основных подхода к решению этой непростой архитектурной задачи. Выбор конкретного метода зависит от требований бизнеса к скорости ответа.
Общение через контракты
Первый способ подразумевает использование строгих сетевых контрактов. Сервисы общаются напрямую, но делают это через стандартизированный интерфейс. Самый популярный пример такого подхода — это REST API. Клиентское мобильное приложение ничего не знает о серверной базе данных. Оно просто отправляет сетевой запрос и получает в ответ понятный текстовый JSON. Если бэкенд перепишут с языка Python на язык Go, клиент этого даже не заметит. Главное условие — сохранение прежнего формата ответов.
Асинхронность и брокеры сообщений
Синхронные прямые вызовы обладают одним существенным скрытым недостатком. Если принимающая сторона отвечает слишком медленно, вызывающий сервис тоже начинает тормозить. Проблема решается переходом к асинхронному обмену сообщениями через посредников. Эту роль выполняют надежные брокеры сообщений вроде Apache Kafka или RabbitMQ.
Асинхронное взаимодействие строится на нескольких базовых принципах.
- Сервис-отправитель просто публикует событие в центральный брокер сообщений.
- Отправитель не ждет ответа и сразу продолжает выполнять свои задачи.
- Сервис-получатель читает новые сообщения из брокера в удобном ему темпе.
- Если получатель временно недоступен, сообщения безопасно копятся в брокере.
Такой подход гарантирует максимальную независимость всех элементов ИТ-системы. Это идеальный выбор для обработки больших потоков разрозненных данных.
Слабая связанность в Data Engineering
Инженерия данных претерпела колоссальные изменения за последние несколько лет. Ранее специалисты использовали тяжелые монолитные процессы трансформации информации. Огромный скрипт подключался к источнику, сложно фильтровал данные и сохранял результат. Если на этапе сохранения обрывалась сеть, весь многочасовой процесс завершался фатальной ошибкой. Инженерам приходилось запускать тяжелую обработку с самого начала.
Сегодня аналитические хранилища строятся исключительно по принципу слабой связанности. Инженеры используют современные оркестраторы задач для управления процессами. Инструменты вроде Apache Airflow позволяют разбить один большой скрипт на цепочку маленьких шагов. Каждый шаг выполняет строго одну функцию и работает изолированно.
Разделение логики дает команде данных множество неоспоримых технических плюсов.
- Точечный перезапуск процессов. При сбое мы чиним код и перезапускаем только упавший конкретный шаг.
- Четкое разделение ответственности. Выгрузкой данных из сторонних API занимается один инструмент. Сложной внутрибазовой трансформацией управляет другой сервис.
- Повторное использование кода. Очищенную таблицу клиентов могут использовать разные аналитические витрины без дублирования расчетов.
Современный Data Lake невозможно построить без применения принципов изоляции процессов. Жесткая связанность в аналитике неизбежно приводит к хаосу и неверным отчетам.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
7 сентября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Loosely Coupled в Machine Learning
В сфере машинного обучения монолитный код является источником постоянной головной боли. Часто начинающие специалисты пишут весь пайплайн в одном интерактивном блокноте. Там они собирают данные, обучают сложную нейросеть и делают предсказания. Для локальных экспериментов этот подход работает вполне сносно. Однако в промышленной эксплуатации такая архитектура обречена на громкий провал.
Правильный подход диктует методология MLOps. Она требует строгого разделения жизненного цикла алгоритма на независимые этапы. Процесс длительного обучения всегда должен быть отделен от процесса быстрой выдачи результатов пользователям.
Архитектура надежной ML-системы обычно включает следующие слабо связанные компоненты.
- Изолированный пайплайн обучения. Скрипт запускается по расписанию и тренирует новую версию алгоритма на свежих данных.
- Централизованный реестр моделей. Обученные веса нейросети сохраняются в специальное хранилище вроде MLflow.
- Независимый сервис инференса. Легкое приложение скачивает актуальную модель и быстро обрабатывает входящие запросы клиентов.
- Автономная система мониторинга. Отдельный сервис постоянно проверяет качество предсказаний и сигнализирует о деградации точности.
Такое разделение позволяет дата-саентистам безопасно экспериментировать с новыми крутыми алгоритмами. Бизнес получает стабильно работающий сервис без неожиданных простоев.
Разработка и внедрение ML-решений
Код курса
MLOPS
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Примеры кода на Python
Для закрепления материала рассмотрим практический пример рефакторинга программного кода. Мы перейдем от жесткой привязки к слабой связанности с помощью паттерна Dependency Injection (внедрение зависимостей).
Сначала напишем неудачный вариант. Здесь сервис жестко привязан к конкретной реализации базы данных.
# Tightly Coupled: Жесткая связанность
class MySQLDatabase:
def save_data(self, data: str) -> None:
print(f"Сохранение {data} в MySQL")
class UserService:
def __init__(self):
# Ошибка архитектуры: прямая зависимость от конкретного класса
self.db = MySQLDatabase()
def create_user(self, username: str) -> None:
self.db.save_data(username)
Теперь применим правильный архитектурный подход. Мы создадим абстрактный интерфейс с использованием встроенного модуля typing. Сервис больше не создает базу данных самостоятельно. Он получает ее извне через параметры конструктора.
# Loosely Coupled: Слабая связанность
from typing import Protocol
# Создаем абстрактный контракт для всех будущих баз данных
class DatabaseInterface(Protocol):
def save_data(self, data: str) -> None:
pass
class PostgreSQLDatabase:
def save_data(self, data: str) -> None:
print(f"Сохранение {data} в PostgreSQL")
class UserService:
def __init__(self, db: DatabaseInterface):
# Сервис зависит только от абстрактного контракта
self.db = db
def create_user(self, username: str) -> None:
self.db.save_data(username)
# Инициализация происходит снаружи сервиса
active_db = PostgreSQLDatabase()
user_service = UserService(active_db)
user_service.create_user("Иван")
Этот простой прием делает ваш код невероятно гибким. Если завтра бизнес решит сменить базу данных, вы напишете новый класс. Сам сервис пользователей останется абсолютно нетронутым.
Визуализация концепций
Ниже представлены наглядные схемы, описывающие различные технические аспекты слабой связанности.
- Сравнение архитектурных подходов
 Блок-схема, показывающая разницу между запутанными связями монолита и четкой иерархией микросервисов через шлюз.
Блок-схема, показывающая разницу между запутанными связями монолита и четкой иерархией микросервисов через шлюз.
- Асинхронный поток данных
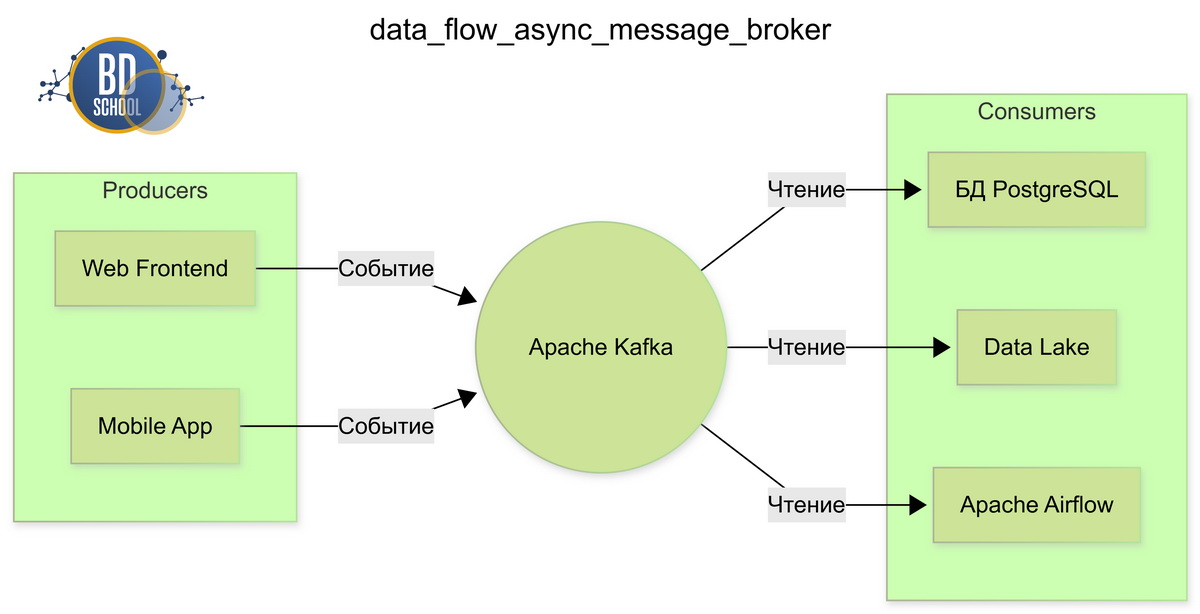 Схема потока данных, где центральный брокер Kafka асинхронно распределяет события от клиентов к независимым базам и оркестратором.
Схема потока данных, где центральный брокер Kafka асинхронно распределяет события от клиентов к независимым базам и оркестратором.
- Процесс внедрения ML-моделей
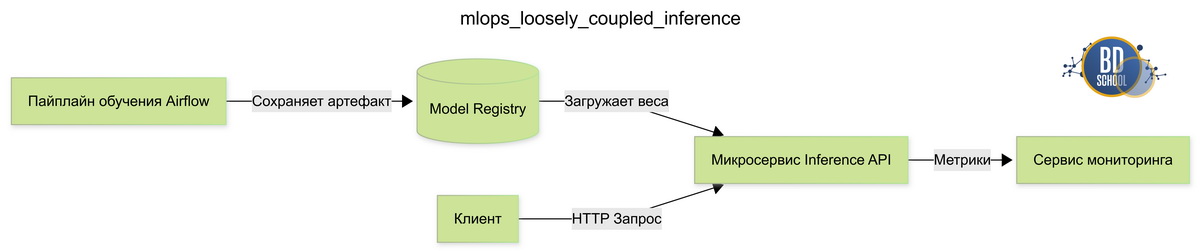
Архитектура машинного обучения, разделяющая тяжелый процесс обучения модели и быстрый сервис выдачи предсказаний через реестр моделей.
Заключение
Слабая связанность — это мощнейший инструмент в арсенале современного технического специалиста. Она блестяще решает проблемы масштабирования продукта и защищает систему от глобальных каскадных сбоев. Однако важно понимать, что распределенные системы значительно сложнее в отладке и локальном развертывании. Ваша главная задача как инженера — найти правильный баланс. Не усложняйте проект сложной микросервисной архитектурой на самом старте. Внедряйте контракты и брокеры сообщений постепенно, отталкиваясь от реальных потребностей растущего бизнеса.
Референсы и источники
Для глубокого погружения в тему отказоустойчивых систем рекомендую изучить следующие актуальные материалы.
- Design for Failure in Distributed Systems — подробный разбор паттернов надежности от архитекторов Amazon (Блог AWS Architecture, 2025). https://aws.amazon.com/blogs/architecture/
- Building Event-Driven Microservices — руководство по построению потоковых пайплайнов данных (Документация Confluent, 2026). https://developer.confluent.io/learn/event-driven-architecture/
- MLOps: Continuous delivery pipelines — стандарты внедрения моделей машинного обучения в продакшен (Google Cloud Architecture Center, 2025). https://cloud.google.com/architecture/mlops-continuous-delivery-and-automation-pipelines-in-machine-learning
- Microservices Guide — обновленный справочник по проектированию слабо связанных сервисов от создателя паттерна (Martin Fowler, 2026). https://martinfowler.com/microservices/
Данные ресурсы помогут вам закрепить теоретические знания и посмотреть на сложные примеры из реальной практики крупных компаний.