 370
370 
Содержание
- Что такое DeepSeek и почему о нем все говорят?
- Архитектурные инновации: Как DeepSeek экономит ресурсы
- Multi-head Latent Attention (MLA)
- DeepSeekMoE - Эволюция смеси экспертов
- Революция в обучении - DeepSeek-R1 и логическое мышление
- Group Relative Policy Optimization (GRPO)
- Сценарии использования и доступные модели
- Практическая работа с DeepSeek
- DeepSeek vs GPT-4 — Сравнение экономики и эффективности
- Анатомия "Chain of Thought" в DeepSeek-R1
- Заключение
- Референсные ссылки
DeepSeek — это семейство языковых и специализированных моделей искусственного интеллекта, разработанных компанией DeepSeek, ориентированных на задачи генерации текста, программирования и аналитики данных. Проект нацелен на радикальное снижение стоимости вычислений. Сегодня DeepSeek меняет устоявшиеся правила игры в индустрии. Нейросети компании показывают невероятно высокую производительность. Они успешно конкурируют с самыми мощными западными аналогами. При этом их архитектура работает намного эффективнее. Разработчики применили нестандартные математические и инженерные подходы. Это позволило снизить затраты на обучение в десятки раз. Таким образом, по-настоящему сильный искусственный интеллект стал доступнее для всего сообщества.
Что такое DeepSeek и почему о нем все говорят?
В последние годы рынок нейросетей контролировали крупные корпорации. Обучение флагманских моделей требовало огромных вычислительных кластеров. Затраты на такие проекты исчислялись сотнями миллионов долларов. Однако команда DeepSeek бросила вызов этой тенденции. Они создали модели с открытыми весами и потрясающей эффективностью.
Успех проекта базируется на глубоком переосмыслении классических алгоритмов. Инженеры отказались от экстенсивного наращивания параметров нейросети. Вместо этого они сосредоточились на оптимизации внутренних механизмов. Такой подход дал удивительные результаты. Модель DeepSeek-V3 быстро заняла лидирующие позиции в рейтингах. Затем появилась версия DeepSeek-R1. Эта модель продемонстрировала выдающиеся способности к логическим рассуждениям. Мир технологий был поражен соотношением цены и качества этих решений.
Архитектурные инновации: Как DeepSeek экономит ресурсы
Современные языковые модели требуют огромных объемов памяти. Это особенно критично при обработке длинных текстов. DeepSeek решает эту проблему с помощью двух ключевых архитектурных инноваций.
Multi-head Latent Attention (MLA)
Механизм внимания — это сердце любой современной текстовой нейросети. Он позволяет модели понимать связи между словами. В стандартной архитектуре этот процесс потребляет слишком много памяти. DeepSeek использует технологию скрытого многоголового внимания.

Данный механизм имеет несколько важных особенностей. Они кардинально меняют процесс обработки информации. Вот суть этой технологии:
-
Сжатие контекста. Алгоритм упаковывает данные в скрытое представление меньшего размера.
-
Снижение нагрузки. Объем кэшируемых данных уменьшается в несколько раз.
-
Восстановление данных. При генерации ответа исходная информация быстро распаковывается.
Эти шаги происходят мгновенно внутри видеокарты. Таким образом, модель может обрабатывать огромные документы без сбоев. Расход дорогой видеопамяти при этом остается минимальным.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
3 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
DeepSeekMoE — Эволюция смеси экспертов
Традиционные плотные нейросети активируют все свои параметры для каждого слова. Это крайне неэффективный способ расхода вычислительных ресурсов. Технология Mixture of Experts (MoE) решает эту проблему. Модель разбивается на множество небольших специализированных блоков.
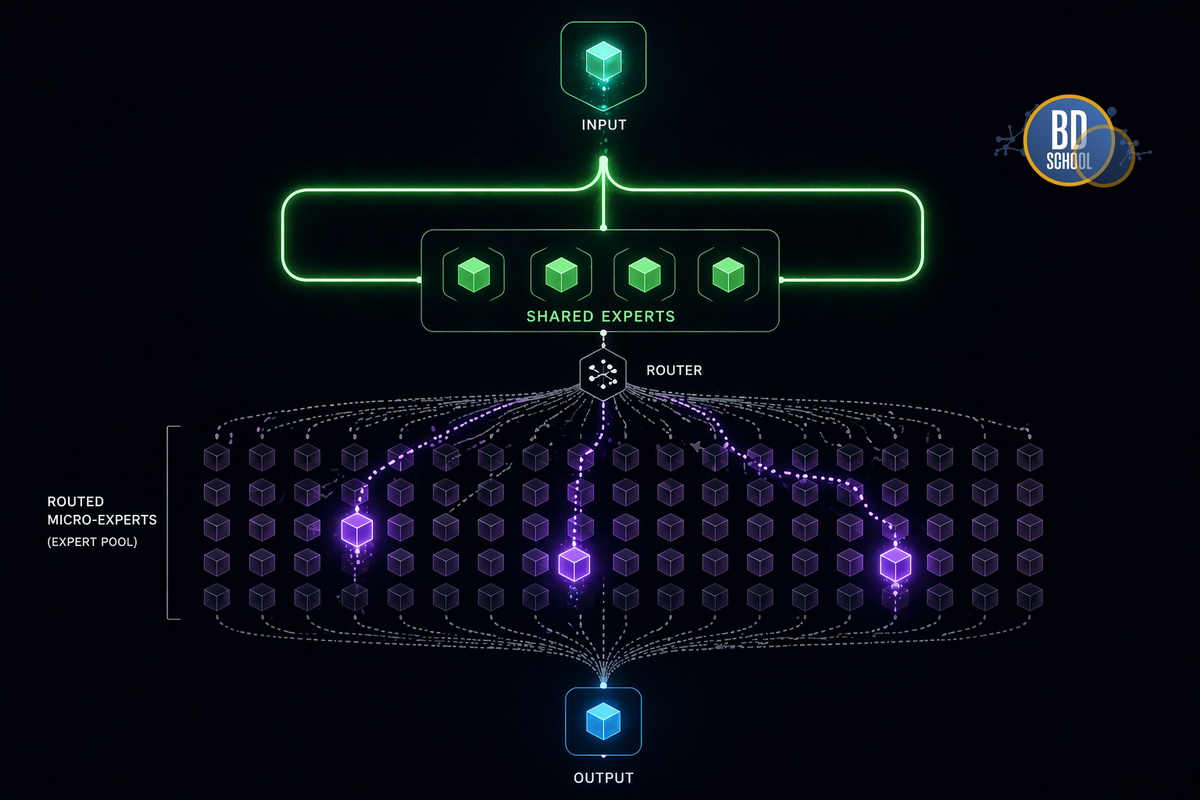
Архитектура DeepSeekMoE выводит этот подход на новый уровень. Она содержит общих и узкоспециализированных экспертов. Рассмотрим, как это работает на практике:
-
Разделение задач. Модель использует сотни микро-экспертов вместо нескольких крупных блоков.
-
Общие знания. Выделенные эксперты всегда активны для сохранения общего контекста.
-
Точечная активация. Для каждого токена выбираются только самые подходящие микро-эксперты.
Такая структура гарантирует высочайшую гибкость работы сети. Она позволяет хранить колоссальные объемы знаний. При этом во время генерации ответа задействуется лишь малая часть параметров. Следовательно, скорость работы значительно возрастает.
Революция в обучении — DeepSeek-R1 и логическое мышление
Создание моделей с навыками рассуждения обычно требует огромных размеченных датасетов. Люди вручную пишут сложные примеры для обучения. Это долгий и невероятно дорогой процесс. Модель DeepSeek-R1 была создана иначе.
Group Relative Policy Optimization (GRPO)
Для обучения рассуждениям применяется обучение с подкреплением (RL). Классический метод требует наличия отдельной модели-критика. Этот критик оценивает действия основной модели. Работа двух больших моделей требует двойного объема памяти.
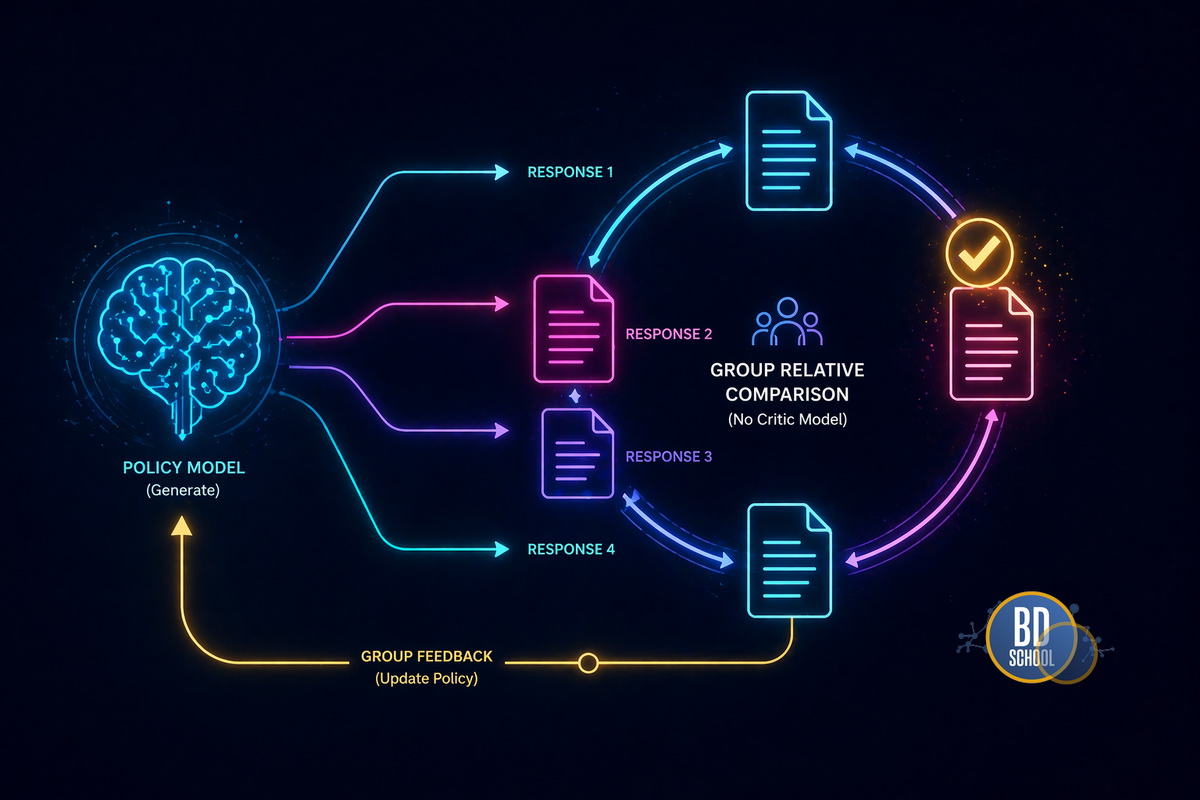
Разработчики из DeepSeek создали алгоритм GRPO. Он полностью исключает модель-критика из конвейера обучения. Принцип работы алгоритма состоит в следующем:
-
Групповая генерация. Модель генерирует сразу несколько вариантов ответа на один вопрос.
-
Внутренняя оценка. Алгоритм сравнивает эти ответы между собой математически.
-
Начисление награды. Лучший ответ из группы получает положительное подкрепление.
Этот изящный метод экономит колоссальное количество серверных ресурсов. Кроме того, он позволяет модели обучаться самостоятельно. Нейросеть буквально учится думать путем проб и ошибок.
Сценарии использования и доступные модели
Семейство моделей DeepSeek предлагает решения для разных задач. Выбор конкретной версии зависит от ваших целей и ресурсов. Существует две основные флагманские ветки развития.
Модель DeepSeek-V3 предназначена для общих задач. Она отлично справляется с написанием текстов и переводом. Также она обладает широкими энциклопедическими знаниями. Версия DeepSeek-R1 создана для сложных аналитических задач. Она идеально подходит для программирования и решения математических уравнений.
Кроме того, компания выпустила дистиллированные версии моделей. Дистилляция — это передача знаний от большой модели к малой. Они основаны на популярных архитектурах вроде Llama и Qwen. Эти небольшие модели можно легко запускать на домашнем компьютере. Они сохраняют высокую способность к логическим рассуждениям.
Практическая работа с DeepSeek
Начать работу с технологиями DeepSeek довольно просто. Вы можете использовать официальный интерфейс программирования приложений (API). Платформа предоставляет полную совместимость со стандартами индустрии.
Вы можете интегрировать нейросеть в свои проекты на Python. Для этого потребуется только ключ доступа к платформе. Ниже представлен базовый пример взаимодействия через стандартную библиотеку запросов.
import requests
api_key = "your_secret_key"
url = "https://api.deepseek.com/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}"
}
data = {
"model": "deepseek-reasoner",
"messages": [
{"role": "user", "content": "Напиши алгоритм сортировки."}
]
}
response = requests.post(url, headers=headers, json=data)
result = response.json()
print(result)
Также доступен локальный запуск через платформу Ollama. Это полностью бесплатный и безопасный способ тестирования. Ваши данные не будут отправляться на сторонние серверы. Для этого достаточно скачать нужную версию через командную строку.

DeepSeek vs GPT-4 — Сравнение экономики и эффективности
Появление DeepSeek-R1 вызвало настоящий шок в индустрии. Главная причина кроется в невероятной экономической эффективности проекта. Западные корпорации тратят огромные средства на обучение. Затраты на тренировку моделей уровня GPT-4 оцениваются в десятки миллионов долларов.
Китайская команда добилась аналогичных результатов за скромную сумму. Обучение модели R1 стоило около шести миллионов долларов. Разница в затратах оказалась просто колоссальной. Это стало возможным благодаря архитектуре MoE и алгоритму GRPO.
Стоимость использования API также приятно удивляет разработчиков. Цена за генерацию токенов в несколько раз ниже конкурентов. Это открывает двери для создания массовых приложений. Стартапы получают доступ к мощному интеллекту без огромных бюджетов. Таким образом, монополия крупных игроков на рынке постепенно рушится.
Анатомия «Chain of Thought» в DeepSeek-R1
Цепочка рассуждений (Chain of Thought) — это важнейший элемент современных нейросетей. Она позволяет модели разбивать сложную задачу на простые шаги. В классическом подходе модель имитирует рассуждения человека. Она делает это на основе заученных шаблонов из обучающей выборки.
DeepSeek-R1 генерирует такие цепочки совершенно по-другому. Модель научилась этому сама благодаря обучению с подкреплением. Процесс генерации ответа содержит интересные особенности:
-
Теги мышления. Ответ всегда начинается со специального технического тега.
-
Самопроверка. Модель часто замечает свои ошибки и пишет об этом в тексте.
-
Многократные попытки. Нейросеть пробует разные подходы к задаче до нахождения верного пути.
Эти рассуждения скрыты от пользователя в обычном интерфейсе. Однако разработчики могут получать их через программные запросы. Анализ этих цепочек помогает лучше понять логику работы алгоритма.
Заключение
Феномен DeepSeek доказал важную истину. Для создания передового искусственного интеллекта не всегда нужны гигантские вычислительные мощности. Инновационные математические алгоритмы способны победить грубую силу «железа». Архитектура скрытого внимания и обновленная смесь экспертов задали новый стандарт индустрии.
Технология групповой оптимизации GRPO открыла путь к дешевому обучению логике. Открытый статус моделей ускоряет развитие всей отрасли. Независимые исследователи теперь имеют доступ к инструментам мирового уровня. Будущее машинного обучения определенно движется в сторону эффективности и открытости.
Референсные ссылки
-
[DeepSeek-V3 Technical Report] (https://arxiv.org/abs/2412.19437)
-
[DeepSeek-R1: Incentivizing Reasoning Capability] (https://arxiv.org/abs/2501.12948)
-
[Understanding Mixture of Experts] (https://huggingface.co/blog/moe)