
Сегодня рассмотрим ключевые достоинства и недостатки резидентных СУБД для больших данных на примере Tarantool. Читайте в нашей статье про основные сценарии использования In-Memory Database (IMDB) в области Big Data с конкретными кейсами из реального бизнеса от Альфа-Банка, Аэрофлота, Тинькофф-Банка и Мегафона. Где и как используются In-Memory в Big Data: 4...

Вчера мы разбирали In-Memory СУБД на примере Tarantool. Сегодня поговорим про Arenadata Grid: что это такое, чем хороша эта база данных, каким образом она связана с Тарантул и чем от него отличается. Также рассмотрим, как Arenadata Grid интегрируется с внешними Big Data системами, в т.ч. основными компонентами инфраструктуры Apache Hadoop...

В этой статье мы рассмотрим резидентные (In-Memory) базы данных на примере Tarantool и Arenadata Grid: что это, как они работают и где используются. Еще поговорим, каким образом эти Big Data системы могут ускорить работу распределенных приложений без замены существующих СУБД, а также при чем здесь промышленный интернет вещей и экосистема...

Сегодня мы расскажем, что такое программная печать, зачем ритейлеры используют эту технологию и как programmatic print связана с Big Data. Читайте в нашей статье, как IKEA, «Рив Гош», «Ив Роше» и Bonprix используют Big Data для персонального маркетинга в своих рекламных кампаниях, а также повышают лояльность клиентов и стимулируют продажи...

В продолжение темы про использование технологий Big Data и Machine Learning в FMCG-бизнесе, сегодня мы поговорим, как распознавание лиц помогает сформировать персональные маркетинговые предложения и насколько это законно. Разбираемся с видеоаналитикой и 152-ФЗ «О персональных данных» на примерах отечественных и зарубежных ритейлеров. От воров до VIP-клиентов: 5 примеров распознавания лиц...

Современное видеонаблюдение в ритейле – это не только обнаружение магазинных воришек, а полноценная аналитика Big Data с мощными алгоритмами Machine Learning для оперативного и стратегического управления. В этой статье мы приготовили для вас 7 сценариев практического использования технологий видеоаналитики в FMCG-секторе с реальными кейсами их внедрения в России на примере...

Цифровизация ритейла – это не только внедрение Apache Hadoop, Spark, Kafka и Machine Learning для аналитики больших данных, прогнозирования спроса и оптимизации складской логистики. Сегодня мы расскажем, что такое коботы и как эти технологии помогают бизнесу. В этой статье мы собрали для вас 7 примеров использования коллаборативных роботов в FMCG....
Вчера мы затрагивали тему управления поставками в ритейле с помощью технологий Big Data и Machine Learning. Теперь разберем подробнее, как большие данные, машинное обучение и интернет вещей меняют складскую логистику и насколько это выгодно бизнесу. Сегодня мы собрали для вас 7 практических примеров: кейсы от отечественных и зарубежных транспортных компаний,...
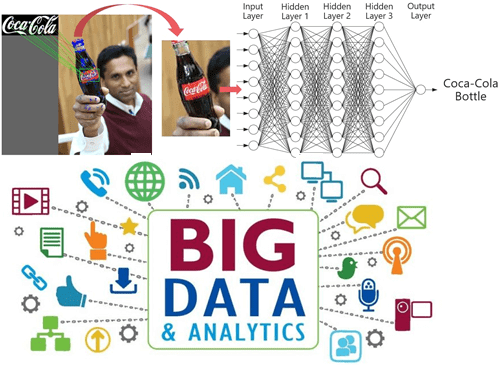
Продолжая рассказывать про применение технологий Big Data и Machine Learning в ритейле, сегодня мы собрали для вас еще 3 интересных примера от FMCG-гигантов. Читайте в нашей статье, как большие данные и машинное обучение помогли Coca-Cola, Starbucks, Neutrogena, Magnum, Procter&Gamble и Nestlé наладить геолокационный маркетинг, повысить узнаваемость своих брендов и улучшить...

По запросу одного из наших клиентов, этой статьей мы открываем серию публикаций про применение технологий Big Data и Machine Learning в торговле быстрооборачиваемых товаров повседневного спроса (FMCG, Fast moving consumer goods). Сегодня рассмотрим, как большие данные, машинное обучение и прочие методы искусственного интеллекта используются в производстве и продаже газированных напитков...

Сегодня поговорим про достоинства и недостатки массово-параллельной архитектуры для хранения и аналитической обработки больших данных, рассмотрев Greenplum и Arenadata DB. Читайте в нашей статье, что такое MPP-СУБД, где и как это применяется, чем полезны эти Big Data решения и с какими проблемами можно столкнуться при их практическом использовании. Что MPP-СУБД...

Вчера мы рассказывали про применение Arenadata DB в крупной отечественной сети розничного ритейла. Сегодня рассмотрим еще один Big Data продукт от российской компании Аренадата, который Х5 Retail Group использует для быстрой аналитики больших данных. Читайте в нашей статье, что такое Arenadata QuickMarts и при чем здесь ClickHouse от Яндекса. Что...

Продолжая разговор про успехи применения отечественных Big Data продуктов, сегодня мы рассмотрим пример использования Arenadata DB в одной из ведущих отечественных компаний розничного ритейла. Читайте в нашей статье про особенности внедрения распределенной отказоустойчивой MPP-СУБД для аналитики больших данных в Х5 Retail Group. Зачем ритейлеру еще одно Big Data решение: специфика...

В этой статье мы продолжим рассказывать про практическое использование отечественных Big Data решений на примере российского дистрибутива Arenadata Hadoop (ADH) и массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB). Сегодня мы приготовили для вас еще 3 интересных кейса применения этих решений в проектах цифровизации бизнеса и государственном...

Сегодня мы поговорим про продукты компании Arenadata – отечественного разработчика дистрибутива Apache Hadoop (ADH), массивно-параллельной СУБД для хранения и анализа больших данных Arenadata DB (ADB) и других Big Data платформ. Читайте в нашей статье, где внедрены эти решения и какую пользу они уже успели принести бизнесу. Облака и банк: 3...

В этом материале рассмотрим, для чего современному менеджеру нужно обучение технологиям Big Data, когда стоит строить собственное Data Lake, чем цифровизация отличается от автоматизации, а также почему курс Аналитика больших данных для руководителей – это эффективная инвестиция в будущее вашего бизнеса. Почему вам нужна аналитика больших данных: мотивация эффективного обучения...

Жесткий режим карантина и самоизоляции из-за нового коронавируса кардинально изменил мировую экономику, сократив доходы большинства работающего населения. Однако, в некоторых отраслях наблюдается беспрецедентный рост продаж. Сегодня мы расскажем, какие компании продолжают успешно развиваться, несмотря на COVID-19 и вызванные им ограничительные меры. Спойлер: все они связаны с большими данными (Big Data)...
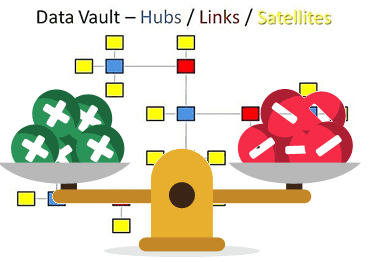
В этой статье мы рассмотрим основные плюсы и минусы Data Vault – популярного подхода к моделированию сущностей при проектировании корпоративных хранилищ данных (КХД). Читайте сегодня, почему промежуточные базы перед витринами данных упрощают ETL-процессы, за счет чего обеспечивается отсутствие избыточности и как много таблиц могут усложнить жизнь архитектора Big Data. Чем...
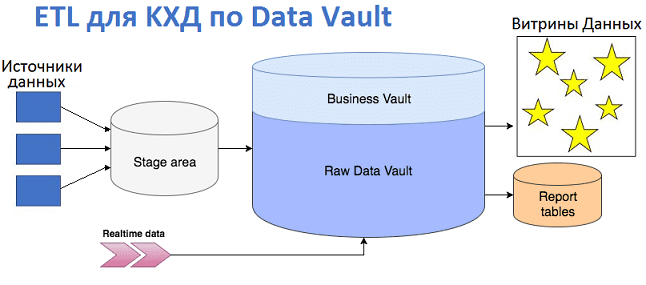
Продолжая разговор про проектирование корпоративных хранилищ данных с использованием подхода Data Vault, сегодня мы рассмотрим, как эта модель влияет на дизайн ETL-процессов и их реализацию. Читайте в нашей статье про загрузку данных в КХД по модели Data Vault и проблемы, которые могут при этом возникнуть, а также способы их решения...
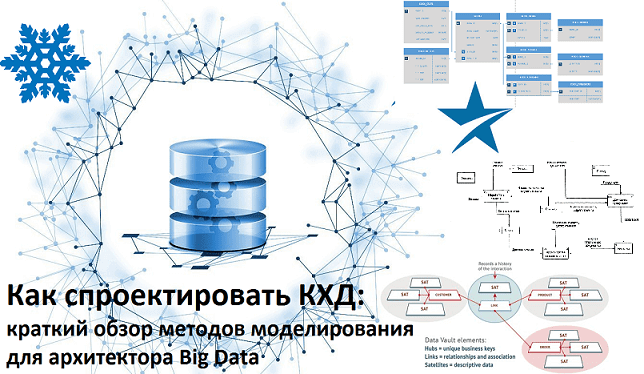
Сегодня мы поговорим о проектировании архитектуры корпоративных хранилищ данных (КХД) и рассмотрим, какие методы и инструменты используются для моделирования структуры DWH и динамики ETL-процессов. В этой статье про основы Data Modelling разберем, что такое OLAP и OLTP, почему 3-я нормальная форма стала стандартом в SQL-СУБД, чем схемы звезды отличается от...