 331
331 
Содержание
- Как Airflow может "слушать" сообщения в топике Kafka
- Шаг 1. Добавляем Kafka в песочницу AirFlow
- Шаг 2. Как Airflow "потребляет" события из топика Apache Kafka
- Шаг 3. Реализация DAG Airflow - Event-Driven Pipeline из Kafka
- Как это работает в динамике
- Проблема "Consumer Group" в контексте Airflow
- Deferrable Operators - будущее уже здесь
- Troubleshooting: Когда тишина в эфире
- Помощь Cursor: Генерация продюсера Kafka для DAG Apache AirFlow
- Использованные референсы и материалы
- Полный перечень статей Бесплатного курса "Apache Airflow для начинающих"
До этого момента все наши DAG-и жили по расписанию. schedule_interval=’@daily’ — это классика. Но современный бизнес не хочет ждать «утреннего отчета». Если данные прилетели в 14:00, отчет должен быть готов в 14:10, а не на следующее утро.
Здесь мы сталкиваемся с фундаментальным конфликтом:
- Airflow — это Batch-инструмент (запускает задачи пачками).
- Kafka — это Streaming-инструмент (поток событий).
Многие новички пытаются обрабатывать сообщения из Kafka прямо внутри Airflow (например, в цикле PythonOperator). Это архитектурная ошибка. Airflow не предназначен для вычитывания миллионов сообщений в секунду. Правильный паттерн использования Airflow с Kafka — это Event-Based Triggering (Запуск по событию).
Сценарий: В Kafka падает сообщение: {«status»: «batch_ready», «s3_path»: «s3://bucket/data.csv»}. Airflow «слушает» топик. Как только видит это спец-сообщение — запускает тяжелый DAG на Spark или Dask для обработки указанного файла.
Как Airflow может «слушать» сообщения в топике Kafka
Есть три способа заставить Airflow ждать события, и два из них — плохие.
Сенсор в режиме mode=»poke» (Плохо) Воркер занимает слот, подключается к Kafka и в бесконечном цикле спрашивает: «Есть сообщение? Нет. А сейчас? Нет.».
- Вы сжигаете ресурсы воркера. Если у вас 10 сенсоров и 10 слотов на воркере, весь кластер встанет в ожидании, и полезная работа не будет делаться.
Сенсор в режиме mode=»reschedule» (Лучше) Воркер проверяет Kafka. Если пусто — задача «умирает» (освобождает слот) и планирует следующую проверку через 5 минут.
- Задержка реакции. Сообщение пришло в 12:01, а проверка будет только в 12:05.
Deferrable Operators / Triggers (Идеально) Это технология Airflow 2.2+. Задача освобождает воркер полностью и передает обязанность ожидания специальному легкому сервису — Triggerer. Один процесс Triggerer может асинхронно (через AsyncIO) ждать тысячи событий одновременно, почти не потребляя память.
- Нужно запустить еще один контейнер triggerer в инфраструктуре.
В этой статье мы реализуем Сенсор, так как это база, но будем держать в уме, что в HighLoad-системах его нужно переписывать на Триггер.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
18 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Шаг 1. Добавляем Kafka в песочницу AirFlow
Нам нужен брокер сообщений. Добавим Kafka без Zookeeper (он теперь не нужен для управления Кафкой) в docker-compose.yaml.
kafka:
profiles:
- broker
image: apache/kafka:3.9.0
container_name: kafka
ports:
- "9092:9092"
environment:
CLUSTER_ID: "MkU3OEVBNTcwNTJENDM2Qk"
KAFKA_NODE_ID: 1
KAFKA_PROCESS_ROLES: broker,controller
KAFKA_LISTENERS: PLAINTEXT://kafka:9092,CONTROLLER://kafka:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@kafka:9093
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 1
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 1
Также нам нужно научить Airflow работать с Kafka. Добавьте библиотеку в Dockerfile: RUN pip install confluent-kafka (или используйте готовый провайдер apache-airflow-providers-apache-kafka, но для обучения мы напишем логику руками, чтобы понять суть).

Не забудьте пересобрать образы: docker-compose up -d —build. В случае если провайдер Kafka не появляется, потребуется жесткая пересборка имиджа airflow-hdfs:2.8.1
docker build --no-cache -t airflow-hdfs:2.8.1 . docker compose up -d --force-recreate
Теперь главное проверим что все необходимое работает и в сборе.
Пробуем зайти в docker Kafka

#--- подключаемся внутрь консоли docker container c Kafka и создаем топик для нашего DAG "etl_start"
docker exec -it kafka bash
bin/kafka-topics.sh --bootstrap-server kafka:9092 --create --topic etl_start
#--- подключаемся продюсером из консоли кафка и кидаем сообщение для запуска процессинга {"status": "ready", "date": "2026-02-03"}
bin/kafka-console-producer.sh --bootstrap-server kafka:9092 --topic etl_start
Шаг 2. Как Airflow «потребляет» события из топика Apache Kafka
Мы не будем читать все данные. Мы будем ждать сигнал. Для этого напишем кастомный сенсор. Почему кастомный? Потому что стандартные сенсоры часто либо слишком сложны в настройке, либо не поддерживают специфическую логику (например, «прочитать JSON и проверить поле status»).
Создайте папку plugins/sensors (если нет) и файл kafka_custom_sensor.py:
import json
import logging
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.apache.kafka.sensors.produce_consume import AwaitMessageTriggerFunctionSensor
from datetime import datetime
# Функция-обработчик. Airflow будет передавать в нее каждое новое сообщение из топика.
# Важно: она должна лежать на уровне модуля, чтобы Airflow мог ее сериализовать.
def check_event(message):
try:
# message - это объект confluent_kafka.Message
val = message.value().decode('utf-8')
data = json.loads(val)
if data.get("status") == "ready":
logging.info("Отмашка получена, запускаем обработку.")
return True # Возвращаем True, сенсор успешно завершает работу
except Exception as e:
logging.warning(f"Пришло сообщение в другом формате, игнорируем: {e}")
return False # Возвращаем False, сенсор продолжает слушать эфир
def process_data():
logging.info("Имитация тяжелой обработки данных...")
with DAG(
dag_id="08.kafka_event_driven",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False
) as dag:
wait_for_event = AwaitMessageTriggerFunctionSensor(
task_id="wait_for_kafka_msg",
kafka_config_id="kafka_default", # Ссылка на подключение в Airflow
topics=["etl_start"],
# Здесь указываем путь к нашей функции проверки.
# Если файл называется 08_kafka_event_driven.py, то путь такой:
apply_function="08_kafka_event_driven.check_event",
poll_interval=10,
poll_timeout=3600,
)
run_job = PythonOperator(
task_id="process_data",
python_callable=process_data
)
wait_for_event >> run_job
Шаг 3. Реализация DAG Airflow — Event-Driven Pipeline из Kafka
Допустим внешняя система загрузила файл и кинула событие в топик etl_start. Мы ждем это событие и запускаем обработку. Вот финальный код для файла 08_kafka_event_driven.py, который решает эту проблему.
import json
import logging
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.apache.kafka.sensors.kafka import AwaitMessageSensor
from datetime import datetime
# Функция для фонового процесса (триггера)
def check_event(message):
try:
val = message.value().decode('utf-8')
data = json.loads(val)
if data.get("status") == "ready":
logging.info("Сигнал получен, завершаем ожидание")
return data
except Exception as e:
logging.warning(f"Неизвестный формат сообщения, пропускаем: {e}")
# Явный возврат пустоты заставляет сенсор ждать следующее сообщение
return None
def process_data():
logging.info("Имитация тяжелой выгрузки данных")
with DAG(
dag_id="08.kafka_event_driven",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False,
tags=['kafka']
) as dag:
wait_for_event = AwaitMessageSensor(
task_id="wait_for_kafka_msg",
kafka_config_id="kafka_default",
topics=["etl_start"],
apply_function="08_kafka_event_driven.check_event",
poll_interval=10,
poll_timeout=3600,
)
run_job = PythonOperator(
task_id="process_data",
python_callable=process_data
)
wait_for_event >> run_job
Как это работает в динамике
- Вы запускаете DAG. Задача wait_for_kafka_msg переходит в статус UP_FOR_RESCHEDULE. Она не занимает слот воркера.
- Каждые 30 секунд Airflow «просыпается», запускает мини-задачу проверки Kafka и засыпает снова.
- Вы (через консоль или скрипт) отправляете сообщение в Kafka: {«status»: «ready», «file_id»: «file_123»}.
- При следующей проверке Сенсор ловит JSON, видит status: ready, возвращает True.
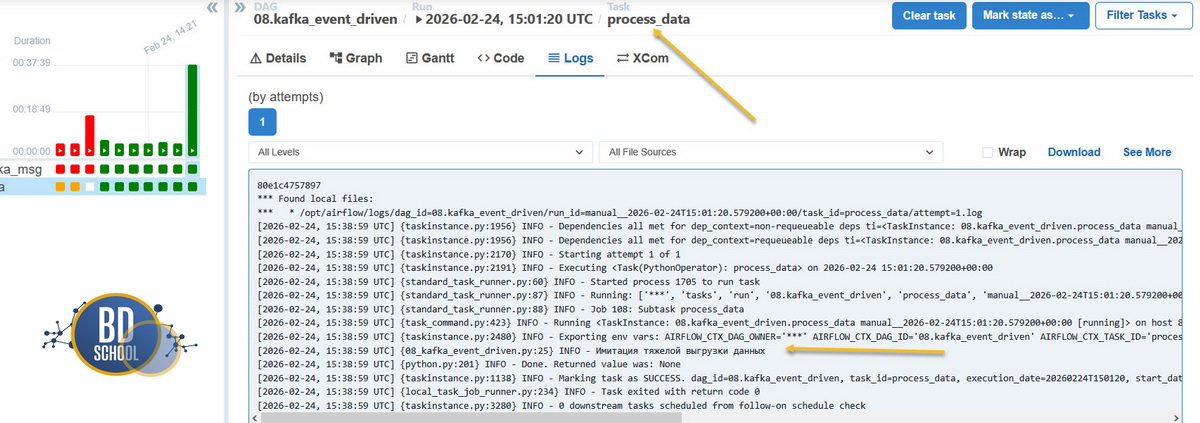
- DAG переходит к задаче process_data, которая печатает «запускает task execution«.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Проблема «Consumer Group» в контексте Airflow
Это самый тонкий момент, о который спотыкаются все инженеры.
Kafka помнит, что «группа пользователей» прочитала сообщение, сдвигая offset (указатель). Если ваш DAG упал и перезапустился с тем же group.id, он не увидит старое сообщение, потому что Kafka считает, что «вы его уже читали».
- Для событий: Часто используют auto.offset.reset’: ‘latest‘, чтобы реагировать только на то, что происходит сейчас.
- Для гарантии доставки: Если важно не пропустить ни одного сигнала (даже если Airflow лежал), нужно управлять оффсетами вручную или использовать уникальные group.id для каждого запуска (что засоряет Kafka).
Deferrable Operators — будущее уже здесь
Код классического сенсора хорош, но он все равно дергает планировщик каждые 30 секунд. Если таких сенсоров тысячи, планировщик задохнется. В современном Airflow с провайдером apache-airflow-providers-apache-kafka архитектура работает иначе. Разница подходов:
-
Sensor — Воркер спрашивает про наличие данных. Если их нет, он уходит в сон, потом просыпается и спрашивает снова.
-
Trigger — Воркер просит триггер разбудить его при появлении нужного сообщения и полностью освобождает ресурсы. Отдельный сервис держит открытым сокет к Kafka. Как только байты прилетели, триггер дает сигнал Airflow, и воркер возвращается к работе.
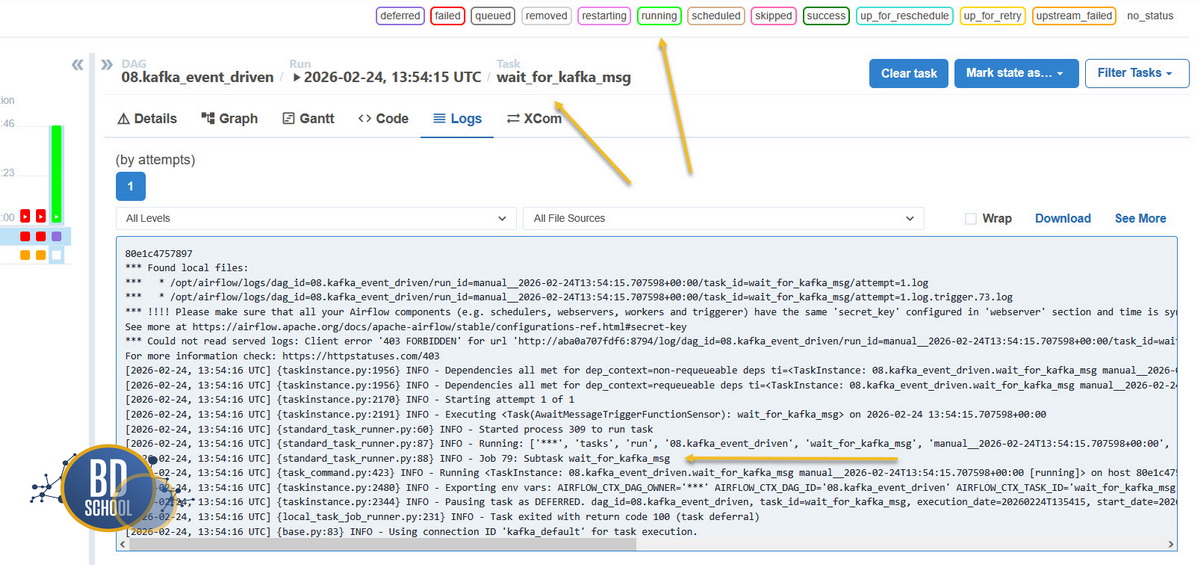
На практике это выглядит так: задача переходит в режим ожидания и окрашивается в специфический бледно-зеленый цвет статуса deferred. В этот момент она не потребляет вычислительные ресурсы кластера. Для новичка настройка Triggerer может быть сложной, но знать о ней обязательно. При переходе на этот механизм критически важно правильно выбрать класс оператора. Библиотека предлагает два похожих решения, работу которых легко спутать при чтении логов.
Класс AwaitMessageTriggerFunctionSensor спроектирован как бесконечный слушатель. Его цель заключается в непрерывном мониторинге топика. При появлении сообщения он вызывает функцию проверки, отрабатывает логику и моментально возвращается на пост дожидаться следующего сигнала. Такой инструмент никогда не переходит в статус успеха по своей воле.
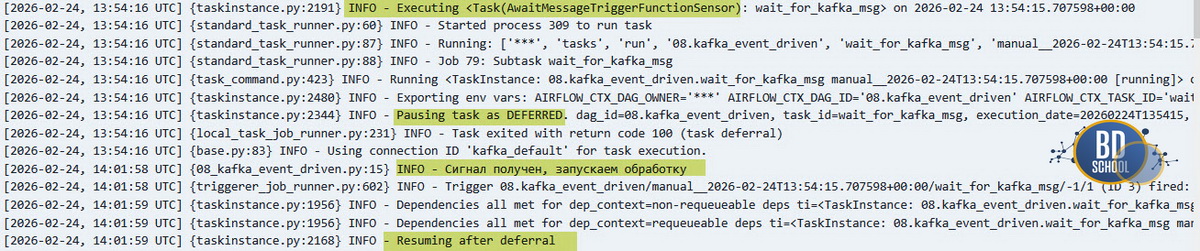
В логах это выглядит как постоянный уход в спячку. Задача ловит сообщение, рапортует об успехе, но затем выдает код возврата 100 (task deferral) и снова ставится на паузу.
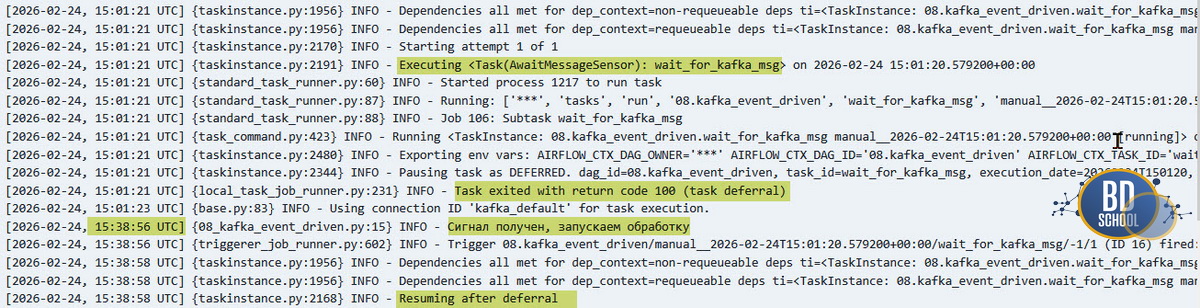
Для классического конвейера данных требуется другой подход. Нам нужно дождаться одного конкретного события, отметить шаг выполненным и передать эстафету следующей задаче графа. С этой задачей отлично справляется AwaitMessageSensor. Как только логика нашей проверки явно возвращает любые данные вместо пустоты, он понимает, что цель достигнута, прекращает прослушивание и закрывает задачу с зеленым статусом успеха.
Лог наглядно подтверждает разницу. Как только нужное сообщение найдено, процесс выходит из режима deferral, задача помечается успешной, и конвейер идет дальше без зацикливания.
Исправьте финальные варианты кода Dags, сенсора и конфигурационных файлов и при необходимости сравните с нашими на GitHub где лежит код к Уроку 8.
Troubleshooting: Когда тишина в эфире
Ошибка 1: cimpl.KafkaException: KafkaError{code=_TRANSPORT,val=-195,str=»Failed to get metadata: Local: Broker transport failure»}
- Причина: Airflow не может достучаться до Kafka.
- Лечение: Проверьте bootstrap.servers. Если вы внутри Docker, это должно быть имя сервиса (kafka:9092). Если снаружи — localhost:9092 (при условии правильной настройки ADVERTISED_LISTENERS).
Ошибка 2: Сенсор вечно висит, хотя сообщение отправлено
- Причина: Проблема с сериализацией или условием. Вы отправили строку «ready», а код ждет JSON {«status»: «ready»}.
- Лечение: Добавьте логирование self.log.info(f»Raw msg: {msg.value()}») до этапа парсинга JSON.
Помощь Cursor: Генерация продюсера Kafka для DAG Apache AirFlow
Вам нужно как-то тестировать сенсор, отправляя сообщения. Промпт для Cursor:
"Напиши простой Python-скрипт используя библиотеку confluent-kafka, который отправляет JSON сообщение {'status': 'ready', 'date': '2023-10-20'} в топик 'etl_start'. Настрой подключение на localhost:9092."
Итог: Мы сделали Airflow реактивным. Теперь он не просто молотит по расписанию, а ждет команды от внешнего мира через шину событий. Это и есть современная «Event-Driven» архитектура.
В следующей статье мы отойдем от технологий передачи данных и займемся аналитикой. Мы подключим Airflow к ClickHouse — самой быстрой базе данных для OLAP-запросов. Мы разберем, как вставлять миллионы строк за секунды, используя нативный протокол, и почему PostgresOperator здесь не подойдет.
Готовы к скорости ClickHouse?
Использованные референсы и материалы
- Confluent’s Python Client for Apache Kafka
https://docs.confluent.io/platform/current/clients/confluent-kafka-python/html/index.html
Документация библиотеки confluent-kafka, которую мы используем в сенсоре. - Deferrable Operators & Triggers
https://airflow.apache.org/docs/apache-airflow/stable/authoring-and-scheduling/deferring.html
Продвинутая тема: как ждать события из Kafka, не занимая слот воркера (асинхронность). - Apache Kafka Introduction
https://kafka.apache.org/intro
Базовые понятия: Topics, Partitions, Consumer Groups.
Полный перечень статей Бесплатного курса «Apache Airflow для начинающих»
Урок 1. Apache Airflow с нуля: Архитектура, отличие от Cron и запуск в Docker
Урок 2. Масштабирование Airflow: Настройка CeleryExecutor и Redis в Docker Compose
Урок 3. Работа с базами данных в Airflow: Connections, Hooks и PostgresOperator
Урок 4. Airflow и S3: Интеграция с MinIO и Yandex Object Storage
Урок 5. Airflow и Hadoop: Настройка WebHDFS и работа с сенсорами (Sensors)
Урок 6. Запуск Apache Spark из Airflow: Гайд по SparkSubmitOperator
Урок 7. Airflow и Dask: Масштабирование тяжелых Python-задач и Pandas
Урок 8. Event-Driven Airflow: Запуск DAG по событиям из Apache Kafka
Урок 9. Загрузка данных в ClickHouse через Airflow: Быстрый ETL и батчинг
Урок 10. Airflow Best Practices: Динамические DAGи, TaskFlow API и Алертинг

