 780
780 
Содержание
- Что такое S3 и почему это не только Amazon
- Поднимаем свой S3 (MinIO) в Docker
- Настраиваем Connection в Airflow
- Практика: Пишем данные в S3
- Troubleshooting: Почему не летит?
- Помощь Cursor: Работа с boto3
- Использованные референсы и материалы
- Полный перечень статей Бесплатного курса "Apache Airflow для начинающих"
В прошлой статье мы научили Airflow работать со структурированными данными в Postgres. Но в мире Big Data базы данных — это лишь верхушка айсберга. Основная масса данных (логи, картинки, JSON-выгрузки, бэкапы) хранится в виде файлов.
Хранить эти файлы на локальном диске сервера, где крутится Airflow — плохая идея.
- Диск не резиновый.
- Воркеры эфемерны. Если вы используете Celery или Kubernetes, воркер может умереть и возродиться на другом сервере, и ваш локальный файл исчезнет.
Решение — вынести хранение данных во внешнее объектное хранилище, совместимое с протоколом S3. В этой статье мы превратим наш Airflow в полноценный ETL-инструмент: научим его забирать данные, сохранять их в локальный S3 (MinIO) и переключаться на облачный Yandex Object Storage одной строчкой конфига.
Что такое S3 и почему это не только Amazon
Изначально S3 (Simple Storage Service) придумали в Amazon. Но протокол оказался настолько удачным, что стал мировым стандартом. Сегодня, когда говорят «S3«, чаще имеют в виду не конкретный сервис Amazon, а протокол общения.
Если приложение умеет работать с S3, оно автоматически умеет работать с:
- MinIO (ваш личный S3 на сервере)
- Yandex Object Storage
- Google Cloud Storage
- Ceph и другими системами
Для Airflow нет разницы, куда писать. Ему нужны только три вещи: Endpoint (адрес), Access Key (логин) и Secret Key (пароль).
Поднимаем свой S3 (MinIO) в Docker
Чтобы тренироваться бесплатно и локально, добавим в наш docker-compose.yaml сервис MinIO. Это легкий и быстрый S3-сервер.
Добавьте этот блок в секцию services (рядом с postgres и redis):
minio:
image: minio/minio:latest
ports:
- "9000:9000" # API порт (для Airflow)
- "9001:9001" # Веб-консоль (для вас)
environment:
- MINIO_ROOT_USER=minioadmin
- MINIO_ROOT_PASSWORD=minioadmin
command: server /data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
volumes:
- minio_data:/data
volumes:
# Не забудьте объявить том в конце файла
minio_data:
Проверьте docker-compose.yaml файл на валидность с помощью docker compose config и перезапустите кластер:
docker compose config #-- так мы будем уверенны что не будет хвостов на нашем стенде docker-compose down --remove-orphans docker compose up -d --force-recreate
Теперь зайдите в браузере на localhost:9001. Логин/пароль: minioadmin / minioadmin.

Важно: Сразу создайте там бакет (аналог папки) с именем airflow-bucket.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
7 сентября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Настраиваем Connection в Airflow
Самый сложный момент для новичков — правильно настроить соединение. Airflow использует библиотеку boto3 для работы с S3, и она по умолчанию пытается стучаться в Amazon. Нам нужно переубедить её.
Вариант А: Как настроить Connection Apache Airflow для MinIO (Локально)
Зайдите в Airflow -> Admin -> Connections.
Создайте новое соединение:
| Conn Id | minio_s3 | Если такого типа нет, нужно установить провайдер: pip install apache-airflow-providers-amazon, но в стандартном образе он обычно есть |
| Conn Type | Amazon Web Services | |
| AWS Access Key ID | minioadmin | |
| AWS Secret Access Key | minioadmin | |
| Extra | {«endpoint_url»: «http://minio:9000»} | Это самое важное поле! Нам нужно указать, что адрес сервера — не амазон, а наш контейнер Слава богу это YAML -просто JSON можно писать в строчку |
ВАЖНО: двойные кавычки для поле extra
Обратите внимание: мы используем имя сервиса minio из docker-compose, так как Airflow будет стучаться к нему изнутри сети Docker.
Вариант Б: Как настроить Connection Apache Airflow для Yandex Object Storage (Продакшен)
Если у вас есть облако в Яндексе, процесс почти идентичен.
- В консоли Y.Cloud создайте Сервисный аккаунт.
- Дайте ему роль storage.editor.
- Создайте для него Статический ключ доступа. Вы получите идентификатор ключа и секретный ключ.
- В Airflow создайте соединение yandex_s3
| Conn Type | Amazon Web Services |
| Login (Access Key) | Ваш ключ из Y.Cloud |
| Password (Secret Key) | Ваш секрет из Y.Cloud |
| Extra | {«endpoint_url»: «https://storage.yandexcloud.net»} |

Видите? Разница только в endpoint_url и ключах. Код DAG-а менять не придется!
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
7 сентября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Практика: Пишем данные в S3
Давайте решим классическую задачу. У нас есть данные в Postgres (из прошлой статьи), и нам нужно выгрузить их в CSV-файл и сохранить в «Озеро Данных» (S3) для дальнейшей аналитики. Мы будем использовать S3Hook. Это универсальный инструмент для работы с объектным хранилищем.
Создайте файл dags/postgres_to_s3.py:
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.postgres.hooks.postgres import PostgresHook
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from datetime import datetime
import csv
import os
# Название бакета (должен быть создан заранее!)
BUCKET_NAME = "airflow-bucket"
# Имя файла с датой запуска
KEY_NAME = "users_export_{{ ds }}.csv"
def export_postgres_to_s3(ds, **kwargs):
# 1. Забираем данные из Postgres
pg_hook = PostgresHook(postgres_conn_id="my_dwh")
connection = pg_hook.get_conn()
cursor = connection.cursor()
cursor.execute("SELECT * FROM users")
results = cursor.fetchall()
# 2. Сохраняем во временный локальный файл
# Важно: /tmp/ очищается, не засоряя диск
local_filename = f"/tmp/users_{ds}.csv"
with open(local_filename, 'w') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['id', 'name', 'date']) # Заголовки
csv_writer.writerows(results)
print(f"Данные выгружены локально: {local_filename}")
# 3. Загружаем в S3 (MinIO или Yandex)
# Используем conn_id, который мы настроили (minio_s3 или yandex_s3)
s3_hook = S3Hook(aws_conn_id="minio_s3")
s3_hook.load_file(
filename=local_filename,
key=KEY_NAME, # Имя файла в облаке
bucket_name=BUCKET_NAME,
replace=True # Перезаписывать, если файл уже есть (Идемпотентность!)
)
print(f"Файл успешно загружен в S3: {BUCKET_NAME}/{KEY_NAME}")
# 4. Убираем за собой (удаляем локальный файл)
os.remove(local_filename)
with DAG(
dag_id="export_to_datalake",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False
) as dag:
upload_task = PythonOperator(
task_id="upload_to_s3",
python_callable=export_postgres_to_s3
)
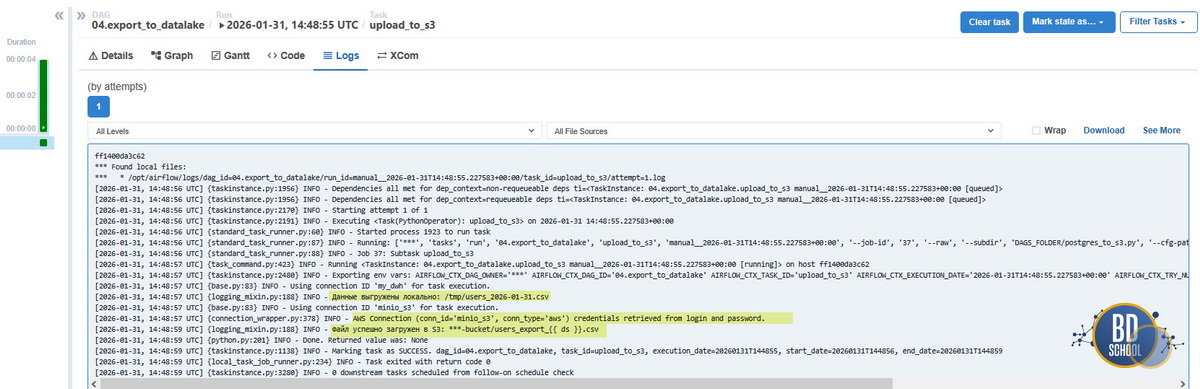
Разбор кода
- Локальный буфер: Мы сначала пишем файл на диск (/tmp), а потом грузим его. Почему не сразу потоком? Для новичка файл надежнее, его можно проверить, если загрузка упадет.
- replace=True: Это обеспечивает идемпотентность. Если вы запустите DAG дважды за один день, старый файл просто перезапишется новым. Данные не задублируются.
- Универсальность: Если завтра вы решите переехать с MinIO на Yandex, вам нужно будет поменять только одну строчку: aws_conn_id=»minio_s3″ на aws_conn_id=»yandex_s3″.
Troubleshooting: Почему не летит?
Работа с S3 полна нюансов сетевого взаимодействия.
Ошибка 1 EndpointConnectionError: Could not connect to the endpoint URL
- Причина: Airflow не видит MinIO. ( Мы намерянно поправим порт для MinIO на 9009 — на котором глушняк 🙂

- Лечение: Проверьте поле Extra в Connection. Если вы написали localhost:9000, это ошибка (Airflow будет искать MinIO внутри своего контейнера). Должно быть http://minio:9000 (имя сервиса из docker-compose).
Ошибка 2: 403 Forbidden
- Причина: Неверные ключи доступа или (в случае Yandex) у сервисного аккаунта нет прав на запись в бакет.
- Лечение: Проверьте Access/Secret Key. В Yandex Cloud убедитесь, что роль storage.editor назначена именно на тот каталог (folder), где лежит бакет.
Ошибка 3: The specified bucket does not exist
- Причина: S3Hook (обычно) не создает бакеты сам. Мы переключили в dags/postgres_to_s3.py подключение с MinIO на Yandex Cloud, но забыли создать там bucket и вот результат вторая ошибка

- Лечение: Зайдите в консоль MinIO (localhost:9001) или Yandex Cloud и создайте бакет airflow-bucket вручную перед запуском DAG.
Исправьте финальные варианты и сравните с нашими на GitHub где лежит код наших уроков.
Помощь Cursor: Работа с boto3
S3 API огромен. Запоминать все методы S3Hook не нужно.
Сценарий 1: Проверка наличия файла. Попросите Cursor написать код и потом совместить его с кодом вашего дага:
"Напиши код для Airflow PythonOperator, который использует S3Hook для проверки: если файл 'flag.txt' существует в бакете, то мы идем дальше, иначе падаем с ошибкой. Используй conn_id='yandex_s3'."
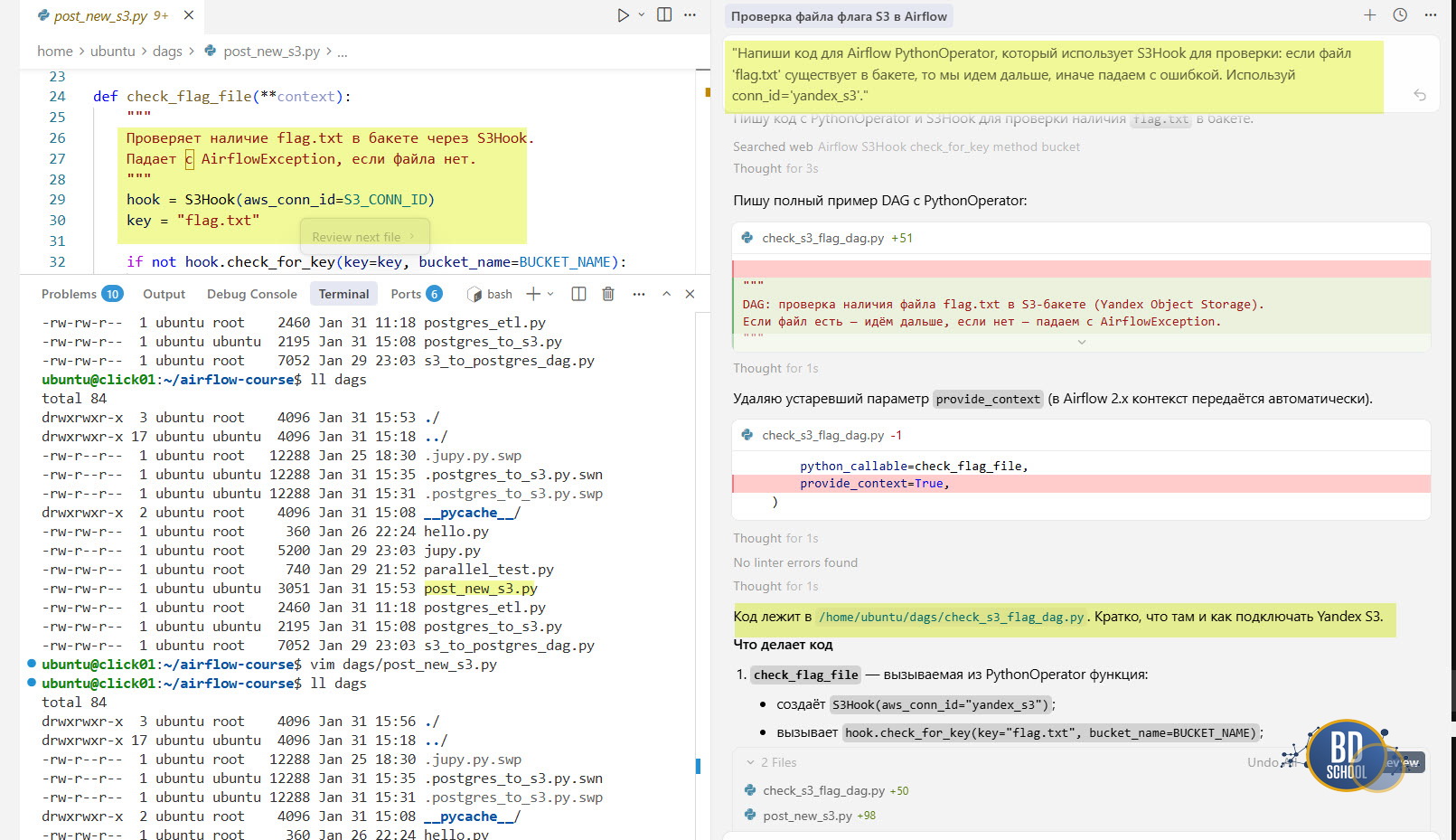
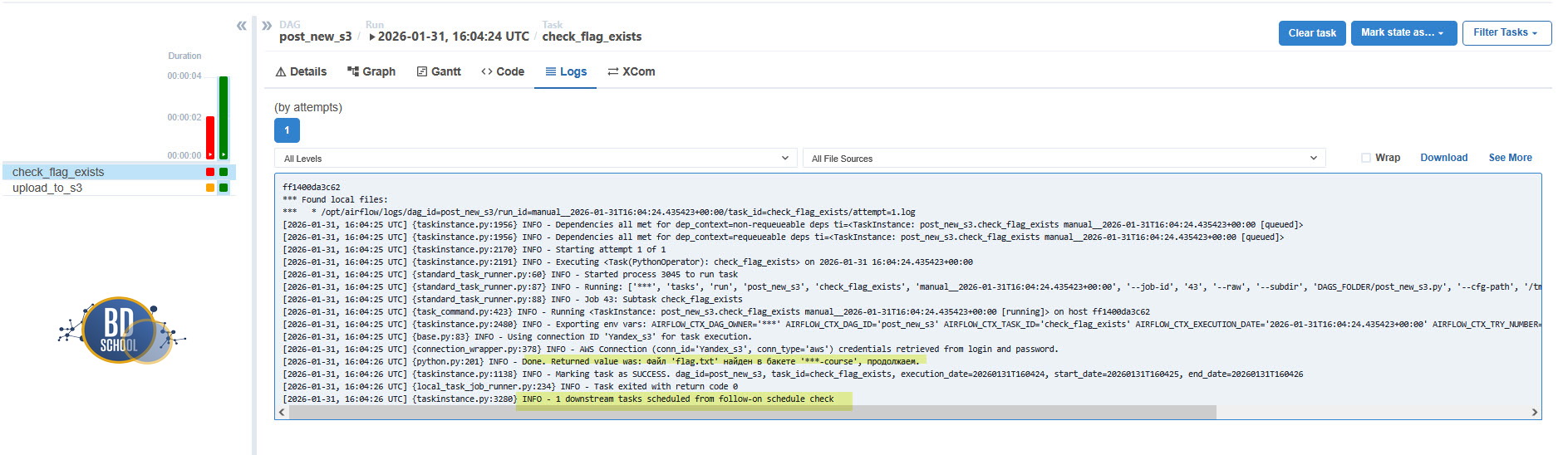
Созданный Cursor AI код check_s3_flag_dag.py и post_new_s3.py собранный из вашего и сгенерированного кода, с описанием вы можете посмотреть на github/article04
Сценарий 2: Генерация JSON-конфига Если вы путаетесь в JSON для поля Extra, напишите:
"Сгенерируй JSON для поля Extra в Airflow Connection, чтобы подключиться к Yandex Object Storage. Endpoint должен быть https://storage.yandexcloud.net."
Итог: Теперь наш Airflow — это не вещь в себе. Он умеет забирать данные из продуктовых баз и складывать их в надежное хранилище. Мы построили простейший Data Lake.
Но что делать с этими файлами дальше? Просто лежать они не приносят пользы. В мире Big Data для обработки огромных массивов файлов используют Hadoop и HDFS. В следующей статье мы коснемся «тяжелой артиллерии». Разберем, как Airflow управляет процессами в экосистеме Hadoop и зачем нам нужен WebHDFSSensor, даже если мы не пишем на Java. Готовы погрузиться в мир Hadoop?
Использованные референсы и материалы
- Amazon Web Services Connection Configuration
https://airflow.apache.org/docs/apache-airflow-providers-amazon/stable/connections/aws.html
Критически важный раздел о том, как правильно прописать endpoint_url для совместимых с S3 хранилищ (MinIO/Yandex). - MinIO Docker Quickstart Guide
https://min.io/docs/minio/container/index.html
Как поднять свой S3 локально (то, что мы делаем в уроке). - Boto3 Documentation
https://boto3.amazonaws.com/v1/documentation/api/latest/index.html
Библиотека, через которую Airflow (и любой Python-скрипт) общается с облаками.
Полный перечень статей Бесплатного курса «Apache Airflow для начинающих»
Урок 1. Apache Airflow с нуля: Архитектура, отличие от Cron и запуск в Docker
Урок 2. Масштабирование Airflow: Настройка CeleryExecutor и Redis в Docker Compose
Урок 3. Работа с базами данных в Airflow: Connections, Hooks и PostgresOperator
Урок 4. Airflow и S3: Интеграция с MinIO и Yandex Object Storage
Урок 5. Airflow и Hadoop: Настройка WebHDFS и работа с сенсорами (Sensors)
Урок 6. Запуск Apache Spark из Airflow: Гайд по SparkSubmitOperator
Урок 7. Airflow и Dask: Масштабирование тяжелых Python-задач и Pandas
Урок 8. Event-Driven Airflow: Запуск DAG по событиям из Apache Kafka
Урок 9. Загрузка данных в ClickHouse через Airflow: Быстрый ETL и батчинг
Урок 10. Airflow Best Practices: Динамические DAGи, TaskFlow API и Алертинг

