 411
411 
Содержание
- Проблема "Java Hell". Почему WebHDFS лучше нативного клиента?
- Обновляем инфраструктуру AirFlow - добавляем карманный Hadoop
- Настройка Connection Airflow + Hadoop
- Новая концепция: Сенсоры (Sensors)
- Практика: DAG "S3 to HDFS" пример интеграции AirFlow
- Разбор нюансов DAG-а
- Troubleshooting - когда WebHDFS капризничает?
- Помощь Cursor: Генерация кода для Хуков в Apache AirFlow DAG
- Использованные референсы и материалы
- Полный перечень статей Бесплатного курса "Apache Airflow для начинающих"
В мире Big Data технологии меняются с бешеной скоростью, но слон (Hadoop) все еще в комнате. Несмотря на популярность облачных S3-хранилищ, распределенная файловая система HDFS остается стандартом де-факто для многих корпоративных хранилищ Data Lake и on-premise кластеров. Даже если вы не пишете MapReduce-задачи на Java, ваш Airflow, скорее всего, должен будет уметь класть файлы в HDFS или забирать их оттуда для Spark-джоб.
В этой статье мы продолжим наш сквозной пример. В прошлый раз мы научились выгружать данные из Postgres и сохранять их в S3. Теперь представим, что аналитический отдел требует эти данные к себе в кластер Hadoop для построения витрин. Наша задача — автоматизировать этот переезд, используя новые инструменты Airflow, Сенсоры и WebHDFS.
Проблема «Java Hell». Почему WebHDFS лучше нативного клиента?
Когда новичок пытается подключиться к Hadoop из Python, он обычно ищет библиотеку, которая работает по нативному протоколу hdfs://. И тут начинается боль. Чтобы это заработало, на каждом воркере Airflow должны стоять бинарники Hadoop, правильно настроенные переменные окружения JAVA_HOME и HADOOP_CONF_DIR. Это превращает поддержку Docker-образов в ад.
Airflow предлагает более изящное решение — WebHDFS. Это REST API над файловой системой Hadoop. Вместо сложного бинарного протокола мы просто отправляем HTTP-запросы (PUT, GET, LIST).
- Плюсы: Не нужно ставить Java и Hadoop-клиент на воркеры Airflow. Работает через обычный Python requests.
- Минусы: Чуть медленнее при передаче терабайтов данных (но для оркестрации это редкость).
Для Airflow это идеальный выбор. Мы будем использовать WebHDFSHook.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Обновляем инфраструктуру AirFlow — добавляем карманный Hadoop
Чтобы наш пример был рабочим, нам нужно добавить HDFS в наш docker-compose.yaml. (скачайте чистый рабочий из 2 урока или почистите предыдущий от MinIO для практики) Полноценный кластер съест всю память, поэтому мы используем облегченную версию с одним узлом (Namenode + Datanode в одном флаконе).
При настройке подключения HDFS в Airflow на практике часто всплывает набор типичных проблем, которые не очевидны из документации:
- во-первых, Airflow не работает с HDFS по бинарному RPC-порту (8020) и требует WebHDFS по HTTP (обычно 9870), поэтому необходимо корректно пробросить именно HTTP-порт NameNode и убедиться, что WebHDFS реально доступен внутри docker-сети;
- во-вторых, для работы с HDFS в Airflow требуется отдельный provider apache-airflow-providers-apache-hdfs, который не входит в базовый образ Airflow и попытки установить его через _PIP_ADDITIONAL_REQUIREMENTS на старте контейнера часто приводят к падению airflow-init, конфликтам зависимостей и нестабильному поведению.
Правильная последовательность действий выглядит так — сначала на стороне Hadoop настраивается fs.defaultFS, включается WebHDFS и пробрасывается порт 9870.
Добавьте этот сервис в ваш файл конфигурации:
hadoop:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
environment:
- CLUSTER_NAME=test
- HDFS_CONF_dfs_permissions_enabled=false # Отключаем проверку прав для простоты
- CORE_CONF_fs_defaultFS=hdfs://namenode:8020
ports:
- "9870:9870" # Порт WebHDFS (важно!)/ NameNode UI
- "8020:8020" # Бинарный порт HDFS RPC (нужен Spark, не Airflow)
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9870"]
interval: 30s
timeout: 20s
retries: 3
datanode:
profiles:
- storage
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
environment:
- CORE_CONF_fs_defaultFS=hdfs://namenode:8020
- HDFS_CONF_dfs_permissions_enabled=false
- SERVICE_PRECONDITION=namenode:9870 namenode:8020
depends_on:
hadoop:
condition: service_healthy
ports:
- "9864:9864"
volumes:
- datanode:/hadoop/dfs/data
# Не забудьте объявить том в конце файла
volumes:
datanode:
Перезапустите кластер: docker compose up -d. Теперь по адресу localhost:9870 доступен веб-интерфейс Hadoop. Вы можете зайти туда и через меню Utilities -> Browse the file system посмотреть, какие файлы лежат на диске.
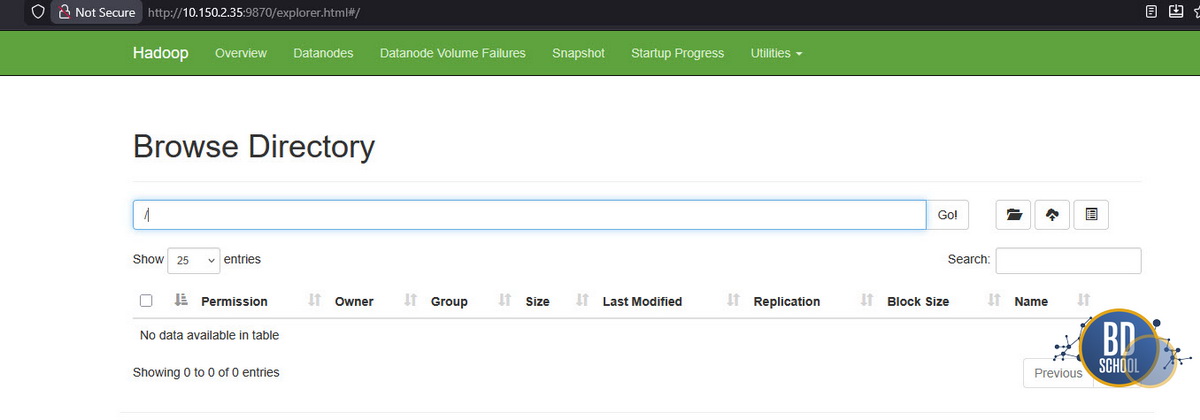
Можете также проверить его командой
#--- должен быть один живой datanode docker exec -it namenode hdfs dfsadmin -report #--- на крайний случай создайте все необходимые папки сразу docker exec -it namenode hdfs dfs -mkdir -p /user/airflow/backup/
Итак минипакетный Hadoop кластер с HDFS для наших опытов с интеграцией с Apache Airflow готов.
Настройка Connection Airflow + Hadoop
Настроим соединение, по аналогии с Postgres и S3.
- Перейдите в Admin -> Connections.
- Создайте новое соединение:
| Conn Id | my_hdfs_conn | |
| Conn Type | HDFS | Apache WebHDFS |
| Host | namenode | имя сервиса из docker-compose |
| Port | 9870 | стандартный порт WebHDFS для Hadoop 3.x. Для старых версий это 50070 |
| Login | root | или hadoop, зависит от образа, в нашем случае root работает, так как мы отключили проверку прав |
Но скорее всего у вас не будет возможности добавить WebHDFS, потому что — УПС, по умолчанию его нет. Поэтому правильная последовательность действий выглядит так:
- сначала на стороне Hadoop настраивается fs.defaultFS, включается WebHDFS и пробрасывается порт 9870(мы это уже сделали!);
- затем для Airflow собирается custom Docker image, в который провайдер HDFS устанавливается на этапе docker build (а не во время запуска);
Приступим к костылизации. Создаем dockerfile
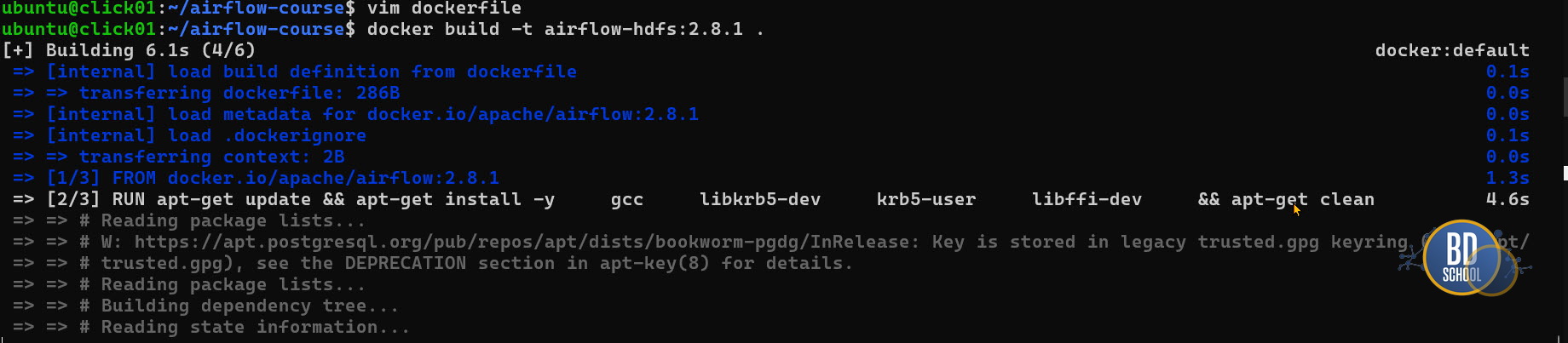
FROM apache/airflow:2.8.1 USER airflow RUN pip install --no-cache-dir apache-airflow-providers-apache-hdfs #--- и собираем его - процесс может занять 5-10 минут docker build -t airflow-hdfs:2.8.1 . #--- проверьте доступные теперь имиджи командой docker image ls

- после этого все сервисы Airflow (webserver, scheduler, worker, init) используют этот единый образ через x-airflow-common;
Меняем настройки в docker-compose.yaml файле, чтобы вместо чистого образа airflow_2.8.1 использовался ваш ‘костыль с Apache HDFS провайдером’
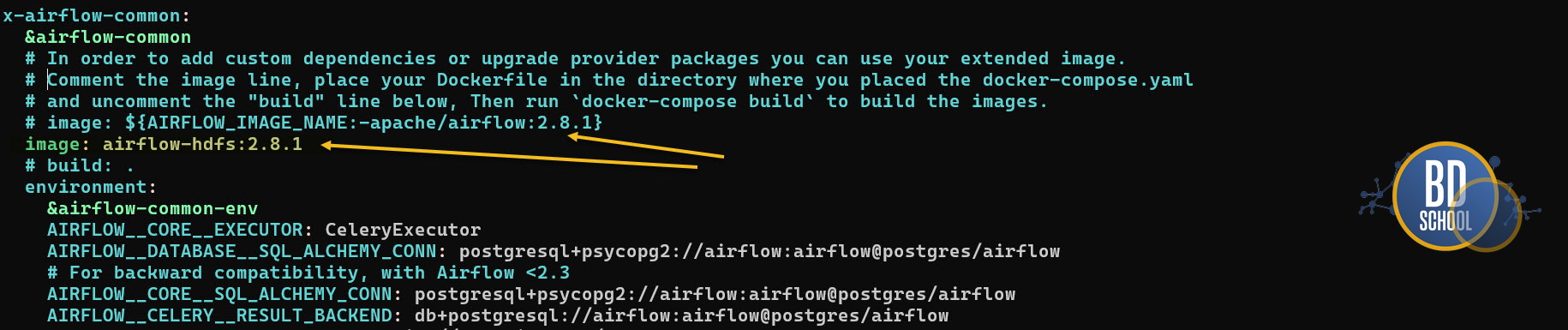
- и только в финале в UI Airflow создаётся connection типа WebHDFS с указанием host, порта и proxy_user.
Такой подход убирает скрытые ошибки, делает окружение воспроизводимым и избавляет от «магии» установки зависимостей при старте контейнеров.
Примечание: Если вы скачали наш финальный файл для запуска Airflow c Hadoop и HDFS провайдером заодно обратите внимание на опцию profiles в docker-compose секции уроков 4 MinIO и 5 Hadoop — мы решили не удалять дельты конфигов наших предыдущих уроков из файла а просто запускать их под разными профилями
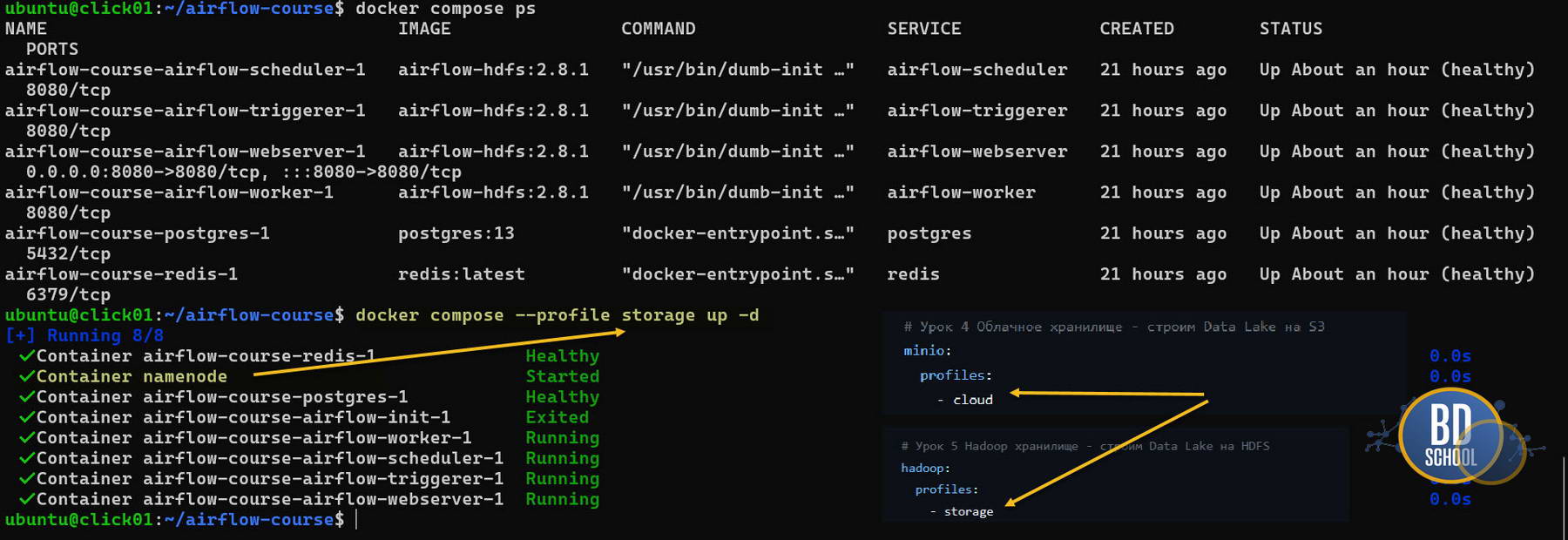
Ниже полезные команды
#---- запуск кластера Apache Airflow в CeleryExecutor mode docker compose up -d #--- запуск дополнительно S3 MinIO кластера profile cloud docker compose --profile cloud up -d #--- запуск дополнительно Hadoop HDFS кластера profile storage docker compose --profile storage up -d #--- выключить все docker compose --profile '*' down
Новая концепция: Сенсоры (Sensors)
Прежде чем перекладывать файл, нам нужно убедиться, что он вообще появился в S3. В прошлых статьях мы запускали задачи по цепочке: Сделай А -> Сделай Б. Но что, если файл в S3 кладет не Airflow, а какая-то внешняя система? Или предыдущий DAG задержался? Если мы просто попытаемся скачать несуществующий файл, задача упадет с ошибкой. Можно написать цикл с time.sleep(), но это костыль. В Airflow для этого есть Сенсоры.
Sensor — это специальный тип оператора, задача которого — ждать. Он запускается, проверяет условие (есть ли файл? наступило ли время? появилась ли запись в базе?), и если нет — засыпает (переходит в статус up_for_reschedule), освобождая слот воркера. В нашем сквозном примере мы будем использовать S3KeySensor.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Практика: DAG «S3 to HDFS» пример интеграции AirFlow
Напишем DAG, который будет мониторить появление файла в каталоге HDFS или в S3 бакете и перекладывает его в другую папку:
- Ждет появления файла users_export_{ds}.csv в S3 (который мы создали в прошлой статье).
- Скачивает его во временную папку.
- Загружает его в HDFS по пути /user/airflow/backup/.
Создайте файл dags/s3_to_hdfs_migration.py:
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.providers.amazon.aws.sensors.s3 import S3KeySensor
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.providers.apache.hdfs.hooks.webhdfs import WebHDFSHook
from datetime import datetime
import os
BUCKET_NAME = "airflow-course"
# Шаблоны оставляем здесь, но использовать их будем через параметры оператора
S3_KEY_TEMPLATE = "users_export_{{ ds }}.csv"
HDFS_PATH_TEMPLATE = "/user/airflow/backup/users_{{ ds }}.csv"
# 1. Добавляем аргументы s3_key и hdfs_dest в функцию
def transfer_s3_to_hdfs(s3_key, hdfs_dest, **kwargs):
print(f"Обрабатываем файлы. Источник: {s3_key}, Назначение: {hdfs_dest}")
# 1. Скачиваем файл из S3
s3_hook = S3Hook(aws_conn_id="Yandex_s3")
local_filename = s3_hook.download_file(
key=s3_key, # <--- ИСПОЛЬЗУЕМ АРГУМЕНТ, А НЕ ГЛОБАЛЬНУЮ ПЕРЕМЕННУЮ
bucket_name=BUCKET_NAME,
local_path="/tmp"
)
print(f"Файл скачан из S3: {local_filename}")
# 2. Загружаем в HDFS
hdfs_hook = WebHDFSHook(webhdfs_conn_id="my_hdfs_conn")
hdfs_hook.load_file(
source=local_filename,
destination=hdfs_dest, # <--- И ЗДЕСЬ ТОЖЕ АРГУМЕНТ
overwrite=True
)
print(f"Файл загружен в HDFS: {hdfs_dest}")
# 3. Уборка
# local_filename уже содержит полный путь, созданный хуком, удаляем его
if os.path.exists(local_filename):
os.remove(local_filename)
with DAG(
dag_id="05.s3_to_hdfs_loader",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False
) as dag:
wait_for_file = S3KeySensor(
task_id="wait_for_s3_file",
bucket_name=BUCKET_NAME,
bucket_key=S3_KEY_TEMPLATE, # Здесь шаблонизация работает сама (поле templated)
aws_conn_id="Yandex_s3",
poke_interval=30,
timeout=600,
mode="reschedule"
)
move_data = PythonOperator(
task_id="move_to_hdfs",
python_callable=transfer_s3_to_hdfs,
# Airflow "прожует" эти строки, подставит дату и передаст в функцию готовые значения
op_kwargs={
"s3_key": S3_KEY_TEMPLATE,
"hdfs_dest": HDFS_PATH_TEMPLATE,
},
)
wait_for_file >> move_data
Разбор нюансов DAG-а
Перед запуском обратите внимание на инфраструктуру: так как мы скачиваем данные из S3 (Yandex), убедитесь, что у вас запущен соответствующий профиль: docker compose —profile cloud up -d.
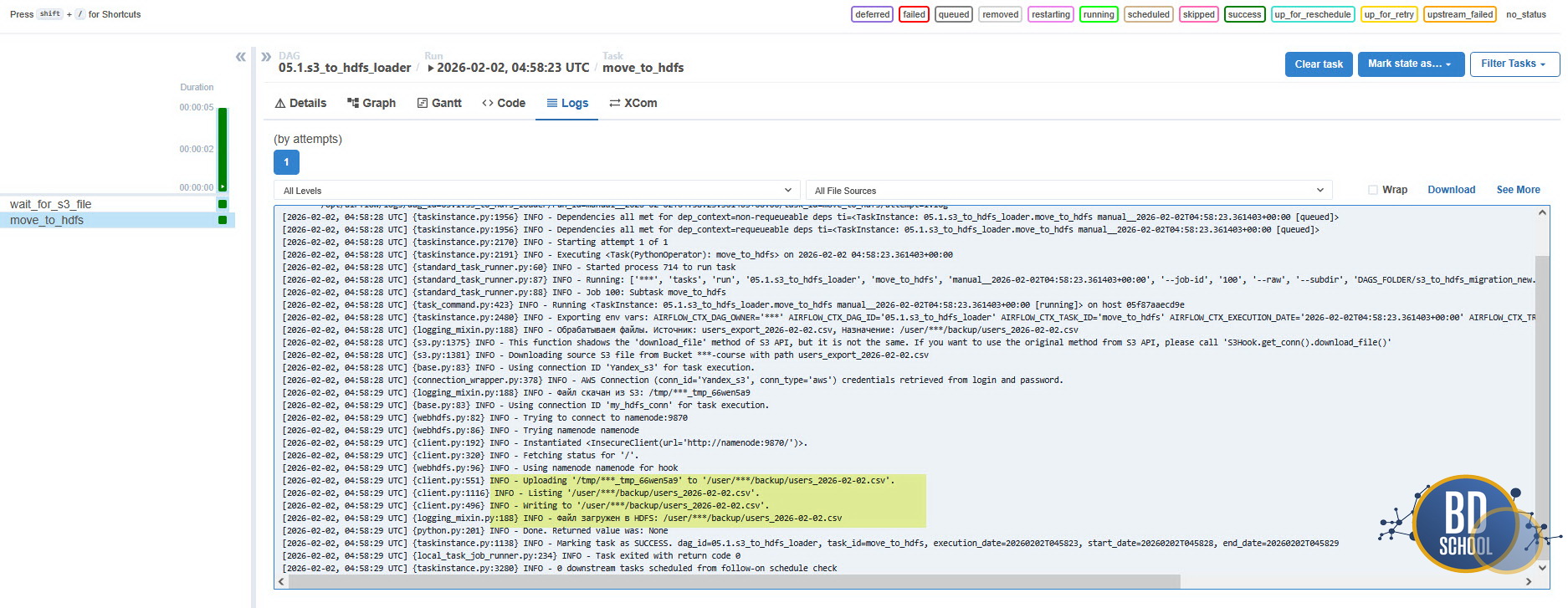
Экономия ресурсов с mode=»reschedule» Это критически важный параметр для сенсоров.
-
mode=»poke» (по умолчанию): Сенсор занимает целый слот воркера и просто «спит» внутри процесса. Если у вас 10 сенсоров и 10 слотов — весь кластер встанет в пробку, ожидая файлов.
-
mode=»reschedule»: Сенсор проверяет условие, и если файла нет — задача завершается, полностью освобождая слот и оперативную память. Планировщик снова поставит её в очередь через poke_interval.
Шаблонизация (Jinja Templating) и op_kwargs В S3KeySensor поле bucket_key поддерживает шаблонизацию «из коробки» — Airflow сам подставляет дату вместо {{ ds }}. Но с Python-функцией сложнее. Если мы просто прочитаем глобальную переменную S3_KEY_TEMPLATE внутри функции, мы получим «сырую» строку с фигурными скобками. Именно поэтому мы используем словарь op_kwargs в определении оператора. Airflow сначала «прогоняет» значения этого словаря через движок шаблонов (превращая {{ ds }} в 2023-01-01), и только потом передает их в функцию как готовые аргументы s3_key и hdfs_dest. Это позволяет не возиться с ручным форматированием дат внутри кода.
Исправьте финальные варианты кода Dags и конфигурационных файлов и при необходимости сравните с нашими на GitHub где лежит код к Уроку 5.
Troubleshooting — когда WebHDFS капризничает?
Работа с Hadoop полна сюрпризов, особенно сетевых.
Ошибка 1: requests.exceptions.ConnectionError
- Диагноз: Airflow не видит Namenode.
- Лечение: Проверьте docker-compose ps. Сервис hadoop должен быть Up. Проверьте, что в Connection Host указан как namenode (имя контейнера), а не localhost.
Ошибка 2: HDFS DataNode is not reachable при загрузке файла WebHDFS работает хитро: сначала вы стучитесь в Namenode («Я хочу загрузить файл»), она говорит «Ок, пиши на Datanode по адресу 172.18.0.5«. И вот тут проблема: этот внутренний IP-адрес Docker-контейнера должен быть доступен вашему воркеру.
- Лечение: В рамках одной Docker-сети (как у нас) это работает само. Если же Airflow снаружи, а Hadoop внутри Docker, начинаются танцы с пробросом портов и подменой хостов. Именно поэтому мы держим всё в одном docker-compose.
Ошибка 3: Permission denied
- Лечение: HDFS имеет свою систему прав (похожую на Linux). Если вы подключаетесь под пользователем airflow, а папка /user/airflow не создана, будет ошибка. В нашем примере мы отключили проверку прав (dfs_permissions_enabled=false в docker-compose), чтобы не усложнять жизнь на старте.
Помощь Cursor: Генерация кода для Хуков в Apache AirFlow DAG
Вам не нужно помнить наизусть методы всех хуков. Используйте Cursor для написания шаблонного кода.
Сценарий: Вы хотите не просто загрузить файл, а проверить, не является ли он пустым, перед загрузкой. Промпт для Cursor:
"Доработай Python-функцию для Airflow. Перед загрузкой файла в HDFS через WebHDFSHook, проверь размер локального файла. Если он меньше 10 байт, пропусти загрузку и выведи предупреждение. Код должен быть снабжен комментариями."
Итог: Мы замкнули цепочку. Данные рождаются в Postgres, экспортируются в S3 и архивируются в HDFS. Попутно мы освоили мощнейший инструмент — Сенсоры, которые позволяют строить событийно-ориентированные (event-driven) пайплайны.
Теперь, когда данные лежат в HDFS, настало время их обработать по-взрослому. В следующей статье мы подключим «тяжелую артиллерию» — Apache Spark. Мы разберем SparkSubmitOperator, научимся запускать задачи как на локальном Spark в Docker, так и (в теории) на внешнем кластере.
Готовы зажигать со Spark?
Использованные референсы и материалы
- Sensors and Smart Sensors
https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/sensors.html
Разница между режимами poke и reschedule — обязательно к прочтению для экономии ресурсов. - WebHDFS REST API Specification
https://hadoop.apache.org/docs/r3.3.6/hadoop-project-dist/hadoop-hdfs/WebHDFS.html
Описание протокола, по которому мы передаем файлы в Hadoop через HTTP. - Apache Airflow Provider for Apache Hadoop
https://airflow.apache.org/docs/apache-airflow-providers-apache-hdfs/stable/index.html
Спецификация хуков для HDFS.
Полный перечень статей Бесплатного курса «Apache Airflow для начинающих»
Урок 1. Apache Airflow с нуля: Архитектура, отличие от Cron и запуск в Docker
Урок 2. Масштабирование Airflow: Настройка CeleryExecutor и Redis в Docker Compose
Урок 3. Работа с базами данных в Airflow: Connections, Hooks и PostgresOperator
Урок 4. Airflow и S3: Интеграция с MinIO и Yandex Object Storage
Урок 5. Airflow и Hadoop: Настройка WebHDFS и работа с сенсорами (Sensors)
Урок 6. Запуск Apache Spark из Airflow: Гайд по SparkSubmitOperator
Урок 7. Airflow и Dask: Масштабирование тяжелых Python-задач и Pandas
Урок 8. Event-Driven Airflow: Запуск DAG по событиям из Apache Kafka
Урок 9. Загрузка данных в ClickHouse через Airflow: Быстрый ETL и батчинг
Урок 10. Airflow Best Practices: Динамические DAGи, TaskFlow API и Алертинг

