 310
310 
Содержание
- Архитектура делегирования - Как Airflow использует Dask для масштабирования
- Настройка инфраструктуры для масштабирования выполнения задач Airflow
- Практика написания DAG - Паттерн "Remote Execution" для Yandex S3
- Главные ошибки при интеграции Dask (Airflow-Specific)
- Роль Cursor в написании "оберток" для масштабирование Airflow c Dask
- Использованные референсы и материалы
- Полный перечень статей Бесплатного курса "Apache Airflow для начинающих"
В прошлых статьях мы выяснили: если задача тяжелая и требует Java (Spark), мы используем SparkSubmitOperator. Но что делать, если у вас «тяжелый» Python? Типичная ситуация когда вы написали отличный код на Pandas внутри PythonOperator. На тестовом файле в 100 Мб все летало. В продакшене пришел файл на 10 Гб. Как результат OOM Kill (Out Of Memory). Воркер Airflow падает, задача фейлится, соседние легкие задачи тоже умирают, потому что процесс был убит операционной системой.
Проблема архитектуры Airflow: PythonOperator выполняет код локально на том воркере, где он запущен. Это значит, что вы ограничены ресурсами одной машины. Пытаться наращивать RAM на воркере Airflow — это тупиковый путь.
Решение: Нам нужно вынести исполнение кода за пределы Airflow, оставив за ним только функцию «кнопки пуск» и контроля статуса. Для Python-задач идеальным «внешним процессором» является Dask. В этой статье мы научим Airflow делегировать тяжелые вычисления удаленному кластеру, не меняя при этом привычный Python-стек.
Архитектура делегирования — Как Airflow использует Dask для масштабирования
В этой связке Airflow выступает в роли заказчика.
- Airflow Worker: Запускает задачу. Но вместо того чтобы грузить данные в свою память, он создает легкий объект-клиент.
- Сетевой вызов: Этот клиент стучится по TCP к планировщику Dask (Scheduler).
- Удаленное исполнение: Dask забирает инструкцию и данные (из S3), «перемалывает» их на своих мощностях.
- Ожидание: Airflow-задача висит в ожидании ответа (или мониторит статус), потребляя минимум ресурсов.
Для Airflow это выглядит как обычный Python-скрипт, но физически нагрузка уходит на другие серверы.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Настройка инфраструктуры для масштабирования выполнения задач Airflow
Чтобы Airflow мог управлять Dask-ом, внутри контейнера Airflow должна стоять библиотека dask[distributed], s3fs и pandas нужных версий. Убедитесь, что она есть в вашем Dockerfile или установите её.
обновляем dockerfile до:
FROM apache/airflow:2.8.1-python3.10
USER root
# 1. ОБЪЕДИНЕННАЯ УСТАНОВКА СИСТЕМНЫХ ПАКЕТОВ
# gcc, libkrb5-dev... — нужны для компиляции HDFS провайдера (Урок 5)
# default-jdk, procps, curl — нужны для работы Spark (Урок 6)
RUN apt-get update
&& apt-get install -y --no-install-recommends
gcc
libkrb5-dev
krb5-user
libffi-dev
default-jdk
procps
curl
&& apt-get autoremove -yqq --purge
&& apt-get clean
&& rm -rf /var/lib/apt/lists/*
# 2. НАСТРОЙКА JAVA (Урок 6)
ENV JAVA_HOME=/usr/lib/jvm/default-java
# 3. УСТАНОВКА SPARK-КЛИЕНТА (Урок 6)
ENV SPARK_VERSION=3.5.1
ENV HADOOP_VERSION=3
RUN curl -O https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
&& tar zxf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz -C /opt/
&& rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
&& ln -s /opt/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} /opt/spark
# 4. НАСТРОЙКА ПУТЕЙ SPARK
ENV SPARK_HOME=/opt/spark
ENV PATH=$PATH:$SPARK_HOME/bin:
USER airflow
#--- Добавляем ограничения на установку версий совместимых с Airflow и Python
ARG AIRFLOW_VERSION=2.8.1
ARG PYTHON_VERSION=3.10
ARG CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
# 5. УСТАНОВКА ПРОВАЙДЕРОВ
# Ставим сразу оба: и для HDFS (чтобы работал DAG из 5 урока), и для Spark (Урок 6)
#--- ОБНОВЛЕНИЕ ЗДЕСЬ ---
RUN pip install --no-cache-dir "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"\
apache-airflow-providers-apache-hdfs \
apache-airflow-providers-apache-spark \
"dask==2023.12.1" \
"distributed==2023.12.1" \
s3fs \
pandas
# ПОСЛЕДНЯЯ СТРОКА Добавляем dask, distributed и s3fs (для работы с Yandex S3) только нужной версии
Build-им снова docker image airflow-hdfs:2.8.1
Но и это еще не все к сожалению многокомпонентные распределенные системы, часто конфликтуют из-за совместимости и на стороне выполнения задач ( Dask worker и scheduler). Dockerfile, который мы подготовили, настроен для сборки Airflow контейнеров, и если вы соберете сейчас имидж с помощью ниже описанного docker-compose.yaml файла, вылезут несовместимости по python библиотекам используемым на Dask узлах поэтому сделаем небольшую сборку для Dask:
#--- соберем кастомный имидж для установки Dask контейнеров с треьования по версионности компонент
FROM daskdev/dask:2023.12.1
COPY requirements-dask.txt /tmp/requirements-dask.txt
RUN pip install --no-cache-dir -r /tmp/requirements-dask.txt \
&& python -c "import s3fs,fsspec,pandas; print('OK', s3fs.__version__, fsspec.__version__, pandas.__version__)"
Создадим requirements-dask.txt для сборки нового имиджа под Dask
#-- версии подходящие для dask:2023.12.1 fsspec==2023.12.1 s3fs==2023.12.1 aiobotocore==2.7.0 botocore==1.31.64 boto3==1.28.64 pandas<3
Соберем все воедино: docker build -t dask-s3fs:2023.12.1 -f dockerfile.dask-s3fs .
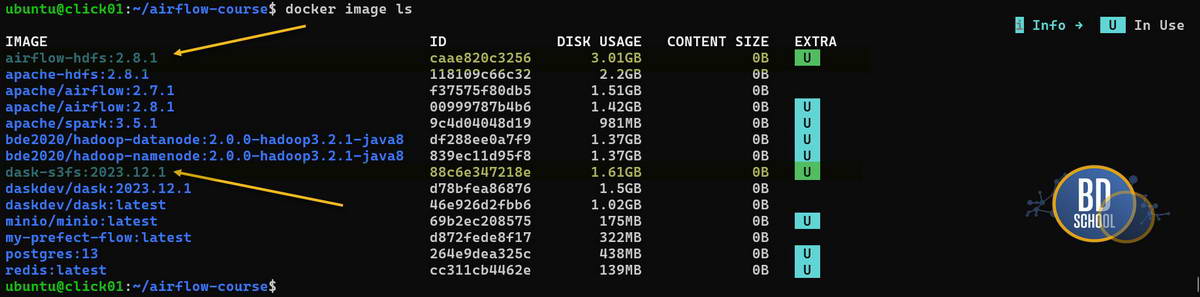
Вот два имиджа которые мы будем использовать для запуска непротиворечивого интегрированного кластера Airflow c Dask.
Теперь нам нужно добавить в наш docker-compose.yaml «исполнительный цех» — кластер Dask c custom dask-s3fs:2023.12.1 имиджем. Для Airflow это просто внешний сервис, как Postgres или SMTP-сервер.
Добавьте в docker-compose.yaml:
# --- СЕРВИСЫ УРОКА 7 (DASK) ---
# Планировщик Dask (раздает задачи)
dask-scheduler:
image: dask-s3fs:2023.12.1
container_name: dask-scheduler
hostname: dask-scheduler
ports:
- "8786:8786" # Порт для подключения Airflow (Client)
- "8787:8787" # Красивый дэшборд мониторинга
command: ["dask-scheduler"]
# Воркер Dask (выполняет Pandas-код)
dask-worker:
image: dask-s3fs:2023.12.1
container_name: dask-worker
depends_on:
- dask-scheduler
command: ["dask-worker", "tcp://dask-scheduler:8786"]
environment:
# Настройки для доступа к Yandex Object Storage
# Dask использует библиотеку s3fs, которая читает эти переменные
- AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} # Возьмет из вашего .env или окружения
- AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} # Возьмет из вашего .env или окружения
- AWS_ENDPOINT_URL=https://storage.yandexcloud.net
# Важно: чтобы s3fs не пытался стучаться в Amazon AWS
- AWS_DEFAULT_REGION=ru-central1
вариант подключения к Yandex_s3 почти такой же ( возьмите параметры из Yandex_s3 коннектора и добавьте AWS_DEFAULT_REGION=ru-central1 чтобы s3fs не стучался в Amazon AWS) только лучше поместить их в .env и скрыть

| AWS_ENDPOINT_URL | https://storage.yandexcloud.net |
| AWS_ACCESS_KEY_ID | ${AWS_ACCESS_KEY_ID} |
| AWS_SECRET_ACCESS_KEY | ${AWS_SECRET_ACCESS_KEY} |
| AWS_DEFAULT_REGION | ru-central1 |
Проверяем код на правильность docker compose config и запустите docker compose up -d. Чтобы почувствовать мощь, можно набрать docker compose scale dask-worker=3, добавив мощностей.

Практика написания DAG — Паттерн «Remote Execution» для Yandex S3
Давайте напишем DAG. Наша цель — показать, как PythonOperator превращается в пульт управления удаленным кластером. В отличие от MinIO, где мы использовали http, здесь мы идем по https. Также Dask-воркеру нужно явно передать storage_options для подключения к Яндекс Облаку.
Задача:
- Соединиться с Dask.
- Отправить туда задачу на обработку файла из S3.
- Дождаться завершения и подтвердить успех в Airflow.
Сохраните этот код как dags/07_dask_yandex.py:
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.models import Variable
from datetime import datetime
from dask.distributed import Client, wait
import logging
# Настройки бакета
BUCKET_NAME = "airflow-course" # Ваш бакет
S3_FILE_PATTERN = "users_export_*.csv" # Маска файлов, которые загружали ранее
def offload_to_dask():
logging.info("Инициализация подключения к Dask Cluster...")
# 1. Подключаемся к планировщику (имя сервиса из docker-compose)
client = Client("tcp://dask-scheduler:8786")
logging.info(f"Подключение успешно: {client}")
# 2. Функция обработки, которая полетит на кластер
# ВАЖНО: Внутри функции нужно импортировать библиотеки заново,
# так как она выполняется в другом процессе/контейнере
def heavy_processing_task(bucket, pattern, aws_key, aws_secret):
import dask.dataframe as dd
# Настройки для Yandex Object Storage (передаем в s3fs)
storage_opts = {
"key": aws_key,
"secret": aws_secret,
"client_kwargs": {
"endpoint_url": "https://storage.yandexcloud.net",
"region_name": "ru-central1",
},
"config_kwargs": {
"s3": {"addressing_style": "path"}
},
}
# Читаем CSV прямо из S3 (ленивое чтение)
s3_path = f"s3://{bucket}/{pattern}"
ddf = dd.read_csv(s3_path, storage_options=storage_opts)
# Пример тяжелой операции: группировка и подсчет
# .compute() запускает реальные вычисления на воркере
# result = ddf.groupby('date').size().compute()
expr = ddf.groupby("date").size()
future = client.compute(expr)
result = future.result()
# Сохраняем результат обратно в S3 (в формате CSV для наглядности)
#output_path = f"s3://{bucket}/dask_results/report.csv"
fs = s3fs.S3FileSystem(
key=aws_key,
secret=aws_secret,
client_kwargs={"endpoint_url": endpoint, "region_name": region},
config_kwargs={"s3": {"addressing_style": "path"}},
)
out_key = f"{BUCKET_NAME}/dask_results/report.csv"
result = result.rename("count")
with fs.open(out_key, "w") as f:
result.to_csv(f)
client.close()
return result.to_dict()
# Превращаем результат (Pandas Series) обратно в Dask DataFrame для записи
dd.from_pandas(result, npartitions=1).to_csv(
output_path,
storage_options=storage_opts,
single_file=True
)
return output_path
# 3. Получаем креды Яндекса (лучше брать из Airflow Connections, но для простоты - Variables или хардкод)
# Предполагаем, что вы создали Variable в Admin -> Variables c именем 'yandex_creds'
# В формате JSON: {"key": "...", "secret": "..."}
# ИЛИ (для теста) впишите свои ключи ниже, если не хотите возиться с Variables
# aws_key = "ВАШ_ACCESS_KEY"
# aws_secret = "ВАШ_SECRET_KEY"
# Чтобы не светить ключи в коде, попробуем достать из Environment (если прокинули в docker-compose)
import os
aws_key = os.getenv("AWS_ACCESS_KEY_ID", "ЗАМЕНИТЕ_НА_КЛЮЧ_ЕСЛИ_НЕТ_ENV")
aws_secret = os.getenv("AWS_SECRET_ACCESS_KEY", "ЗАМЕНИТЕ_НА_СЕКРЕТ_ЕСЛИ_НЕТ_ENV")
# 4. Отправляем задачу на кластер
future = client.submit(heavy_processing_task, BUCKET_NAME, S3_FILE_PATTERN, aws_key, aws_secret)
logging.info("Задача отправлена в Dask. Ждем...")
# Ждем завершения
wait(future)
# Получаем результат (путь к файлу)
try:
result_path = future.result()
logging.info(f"Успех! Данные сохранены в: {result_path}")
except Exception as e:
logging.error(f"Ошибка вычислений в Dask: {e}")
raise e
client.close()
with DAG(
dag_id="07.dask_yandex_processing",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False,
tags=['dask', 'yandex']
) as dag:
run_on_dask = PythonOperator(
task_id="run_on_dask_cluster",
python_callable=offload_to_dask
)
Не забудьте прописать свои ключи в DAG файл ( конечно с точки зрения это не правильно, но наверняка вы не столкнетесь с кучей ошибок при попытке сохранить результаты из dask worker ов, а это уже совсем другая история которую мы расскажем вам на курсе ниже по ссылке
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
А вот и наш результат
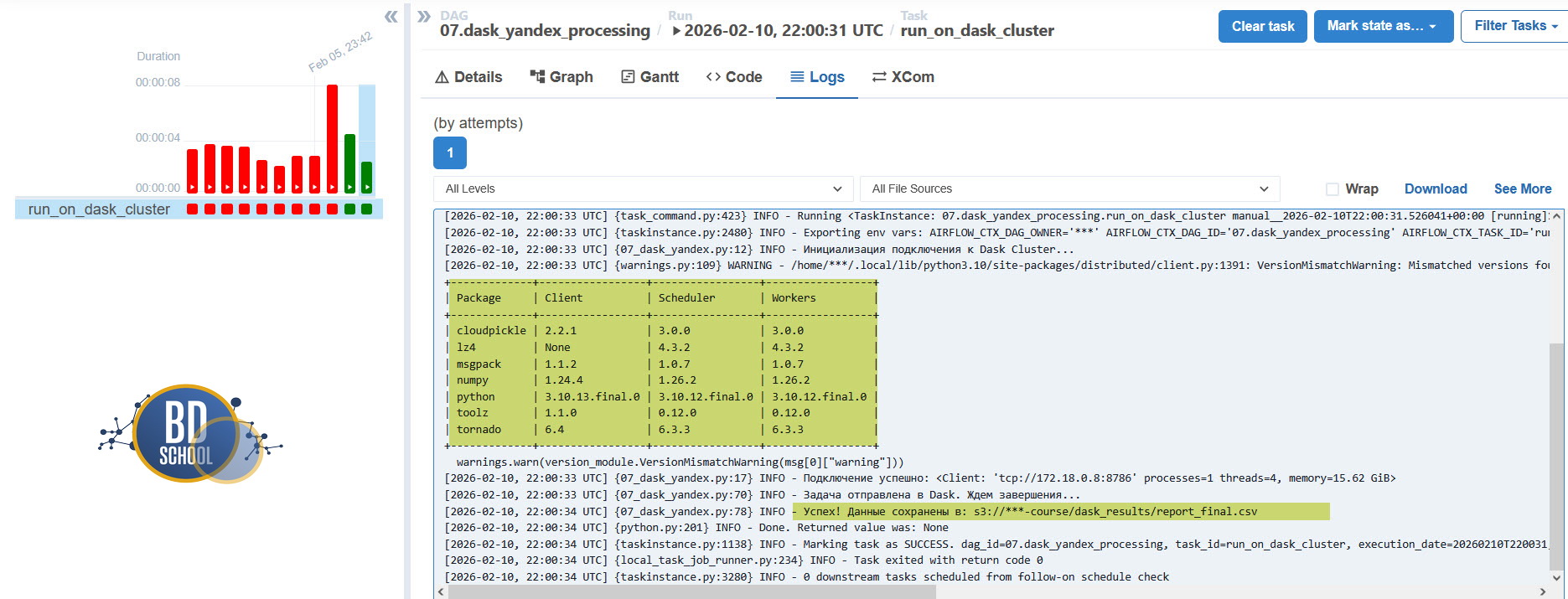
Хотя конечно мы все равно получили предупреждения о ращличиях в версиях компонент на Dask кластере, но не критичных для нашего DAG кода.
Главные ошибки при интеграции Dask (Airflow-Specific)
При такой схеме работы инженеры часто наступают на специфические грабли синхронизации.
Проблема синхронизации окружений (Dependency Hell) Airflow «сериализует» (упаковывает) вашу функцию и отправляет её в Dask.
- Сценарий: Вы используете в функции библиотеку Dask версии 2023.5.0, которая стоит на Airflow. А на Dask-воркере стоит Dask 2026.1.2(latest).
- Результат: Задача упадет с ошибкой десериализации.
- Правило Airflow: Образы Docker для Airflow Worker и Dask Worker должны иметь идентичный набор Python-библиотек. Если обновляете requirements.txt в Airflow — обновляйте и в Dask.
Давайте поразмышляем немного над этим. В нашем случае при старте нашего DAG мы сразу получаем ошибку и пытаемся разобраться в причинах

Присмотритесь над выделенным фрагментом — мы увидим разные версии на клиенте и на сервере ( worker+scheduler) для dask[distributed] и Python. вспоминаем опции которые мы прописали в dockerfile, когда создавали имидж для поднятия Airflow с библиотеками Dask и имиджа «FROM apache/airflow:2.8.1», но версии утилит Dask и Python, да и других утилит мы не выбирали. Без споров на будущее и с уверенностью что изменение конфигурации имиджа не разрушит совместимость с нашими прошлыми уроками (1-6) и установленными компонентами (Hadoop,Spark) выбираем фиксированную версию исходного имиджа Airflow c Python 3.10
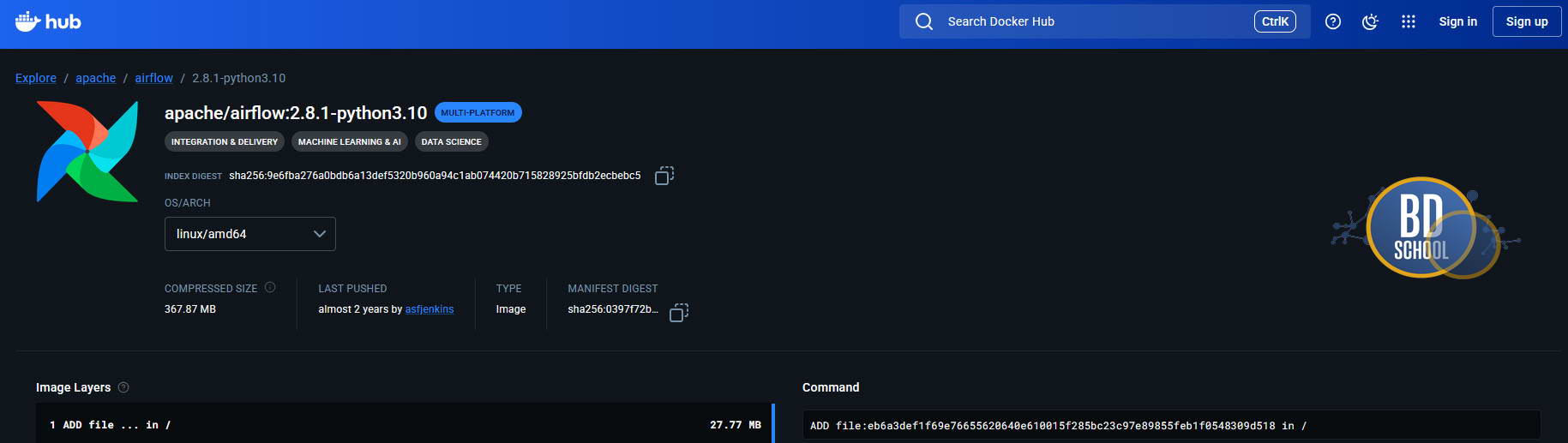
В dockerfile вносим изменения вместо «FROM apache/airflow:2.8.1″ ->»FROM apache/airflow:2.8.1-python3.10″ и для установки пакетов Dask, Distributed тоже жестко фиксируем номера версий («dask==2023.12.1» «distributed==2023.12.1» «dask[distributed]==2023.12.1» s3fs pandas), чтобы и в docker-compose.yaml при конфигурации dask workers и schedulers использовал не «image: daskdev/dask:latest«, а версию максимально близкую и совместимую с клиентом допустим «image: daskdev/dask:2023.12.1«.

Пересобираем docker image и проверяем работу DAGа ( займет чуть больше времени)
docker compose down docker build --no-cache -t airflow-hdfs:2.8.1 . docker compose up -d
Ошибка «Вернуть данные в return» Новички часто пишут: return heavy_dataframe.
- Что происходит: Dask возвращает гигабайты данных по сети обратно в Airflow Client. Airflow пытается записать это в XCom (мета-базу Postgres).
- Результат: База зависает, Airflow падает.
- Правило: Задачи на Dask должны читать из S3 и писать в S3. В Airflow возвращаем только пути к файлам или статус (True/False).
Сетевая доступность Если Airflow запущен локально, а Dask в Docker (или наоборот), Client(…) не сможет подключиться. В нашем примере все работает, потому что оба сервиса живут в одной сети docker-compose. В реальном проде Airflow и Dask могут быть в разных подсетях Kubernetes, и вам придется настраивать доступы.
Исправьте финальные варианты кода Dags и конфигурационных файлов и при необходимости сравните с нашими на GitHub где лежит код к Уроку 7.
Роль Cursor в написании «оберток» для масштабирование Airflow c Dask
Код делегирования часто шаблонный. Cursor может сэкономить время.
Промпт:
Напиши функцию-обертку для PythonOperator Airflow. Функция должна принимать адрес Dask-планировщика и словарь с параметрами. Внутри она должна подключаться к кластеру, запускать переданную функцию processing_logic, ждать результата и логировать прогресс. Обработай возможные ошибки подключения (TimeOut).
Итог: Мы научились использовать PythonOperator не как исполнителя, а как контроллер. Теперь Airflow может запускать задачи любой тяжести, делегируя их Dask-кластеру. Мы решили проблему нехватки памяти (OOM) архитектурным способом, не меняя язык программирования.
Теперь, когда мы умеем работать с тяжелыми файлами, пришло время поговорить о скорости реакции. В следующей статье мы разберем Event-Driven архитектуру. Мы узнаем, как заставить Airflow запускать DAG не по расписанию, а мгновенно — как только в Kafka прилетело сообщение о событии.
Переходим к Kafka и событийной модели?
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Использованные референсы и материалы
- Dask Distributed Documentation
https://distributed.dask.org/en/stable/
Архитектура планировщика и воркеров Dask. - Comparison with Spark
https://docs.dask.org/en/stable/spark.html
Честное сравнение от создателей Dask: когда брать его, а когда Spark. - Dask Docker Images
https://github.com/dask/dask-docker
Официальные образы для развертывания, которые мы применяем в уроке.
Полный перечень статей Бесплатного курса «Apache Airflow для начинающих»
Урок 1. Apache Airflow с нуля: Архитектура, отличие от Cron и запуск в Docker
Урок 2. Масштабирование Airflow: Настройка CeleryExecutor и Redis в Docker Compose
Урок 3. Работа с базами данных в Airflow: Connections, Hooks и PostgresOperator
Урок 4. Airflow и S3: Интеграция с MinIO и Yandex Object Storage
Урок 5. Airflow и Hadoop: Настройка WebHDFS и работа с сенсорами (Sensors)
Урок 6. Запуск Apache Spark из Airflow: Гайд по SparkSubmitOperator
Урок 7. Airflow и Dask: Масштабирование тяжелых Python-задач и Pandas
Урок 8. Event-Driven Airflow: Запуск DAG по событиям из Apache Kafka
Урок 9. Загрузка данных в ClickHouse через Airflow: Быстрый ETL и батчинг
Урок 10. Airflow Best Practices: Динамические DAGи, TaskFlow API и Алертинг

