
Redis Persistence - это комплекс механизмов, отвечающих за сохранение данных из оперативной памяти на долговечный носитель (жесткий диск или SSD). Redis — это in-memory база данных. Это означает, что по умолчанию все данные живут исключительно в оперативной памяти. Это обеспечивает феноменальную скорость, но создает критический риск: при любом...
Requests - стандартная библиотека для составления HTTP-запросов в Python.
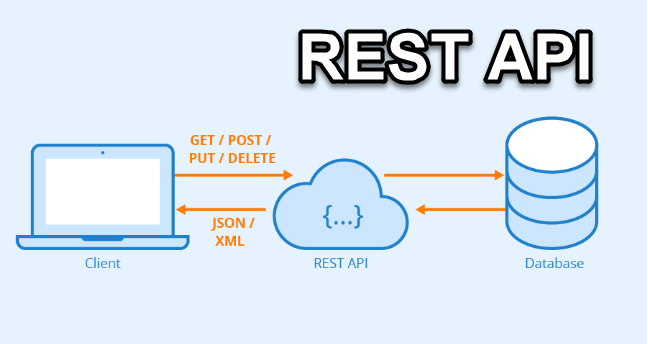
REST API — это интерфейс программирования приложений, который соответствует принципам архитектурного стиля REST (Representational State Transfer). Важно понимать, что REST не является протоколом или стандартом. Это набор архитектурных ограничений и принципов для построения распределенных систем. Когда веб-сервис разработан с соблюдением этих принципов, его называют RESTful. Главная цель REST...

RAG (Retrieval-Augmented Generation) — это архитектурный подход в области искусственного интеллекта, который объединяет мощь больших языковых моделей (LLM) с внешними, авторитетными базами знаний. Проще говоря, это технология, которая учит языковые модели не выдумывать ответы, а находить их в проверенных источниках и на их основе генерировать осмысленный текст. RAG был разработан...

RFID (от английского Radio Frequency IDentification, радиочастотная идентификация) — способ автоматической идентификации объектов, когда радиосигналы считывают или записывают данные, хранящиеся в RFID-метках (транспондерах) [1]. Как появилась технология RFID: немного истории Предшественники современных RFID-меток появились в середине XX века в рамках разработки технологий передачи и распознавания сигналов в военной сфере [1]:...

Apache Samza (Самза) – это асинхронная вычислительная Big Data среда с открытым исходным кодом для распределенных потоковых вычислений практически в реальном времени, разработанная в 2013 году в соцсети LinkedIn на языках Scala и Java. Проектом верхнего уровня Apache Software Foundation Самза стала в 2014 году [1]. Samza vs Apache Kafka...

Scikit-learn (sklearn) - это библиотека для языка Python, предназначенная для машинного обучения, предоставляющая единый интерфейс для алгоритмов классификации, регрессии, кластеризации, снижения размерности и оценки моделей на основе данных. Библиотека, которая превращает сложную математику машинного обучения в понятные Python-команды. Если NumPy и Pandas - это "кирпичи" и "цемент" для...

SDLC (Software Development Life Cycle) - это структурированный процесс создания программного обеспечения, который описывает каждый этап разработки от идеи до вывода из эксплуатации. Понимание этого цикла позволяет командам выпускать качественный продукт в прогнозируемые сроки и в рамках бюджета. В сфере Big Data и ML этот процесс становится критически...
Segmentation image – технология, связанная с компьютерным зрением (computer vision) и обработкой изображений, заключающаяся в обнаружении объектов определенных классов на цифровых изображениях и видео. Причем, обнаружение объектов заключается в определении класса (раскраска) каждого пикселя на цифровом изображении или на каждом кадре видеопотока. Пример кода вы можете посмотреть на GitHub MachineLearningIsEasy...
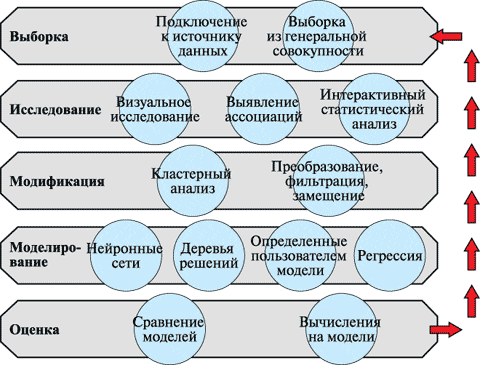
SEMMA (аббревиатура от английских слов Sample, Explore, Modify, Model и Assess) – общая методология и последовательность шагов интеллектуального анализа данных (Data Mining), предложенная американской компанией SAS, одним из крупнейших производителей программного обеспечения для статистики и бизнес-аналитики, для своих продуктов [1]. Зачем нужен стандарт SEMMA В отличие от другого широко используемого...
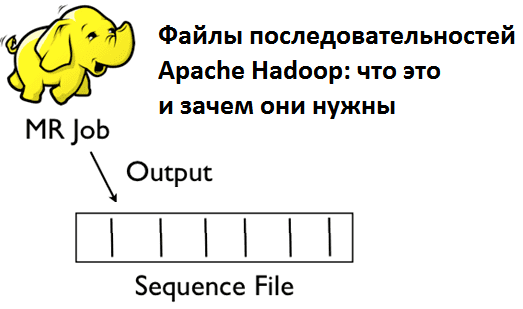
Sequence File (файл последовательностей) – это двоичный формат для хранения Big Data в виде сериализованных пар ключ/значение в экосистеме Apache Hadoop, позволяющий разбивать файл на участки (порции) при сжатии. Это обеспечивает параллелизм при выполнении задач MapReduce, т.к. разные порции одного файла могут быть распакованы и использованы независимо друг от друга...
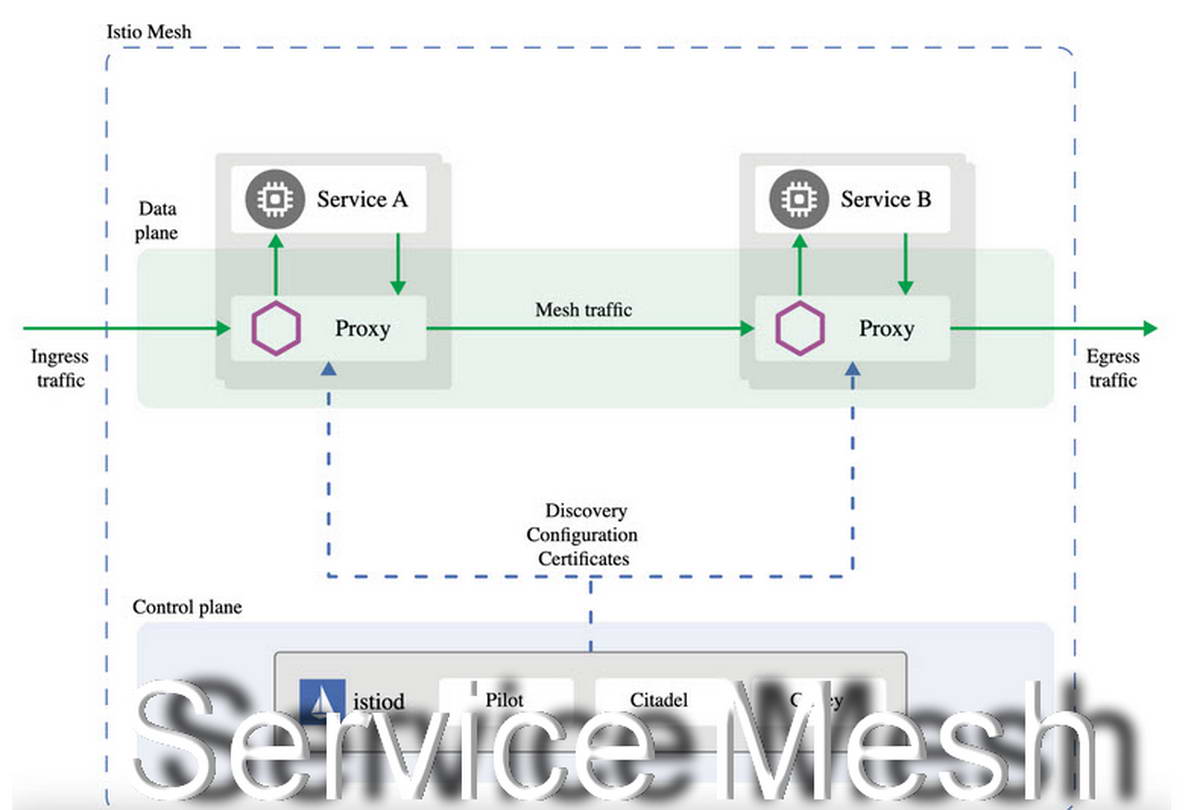
Service Mesh (сервисная сетка) - это инфраструктурный слой для управления сетевыми взаимодействиями между микросервисами, обеспечивающий наблюдаемость, маршрутизацию, безопасность и отказоустойчивость сервис-к-сервису без изменения прикладного кода. Если представить микросервисы как сотрудников большой корпорации, то Service Mesh - это не сами сотрудники, а корпоративная телефонная сеть, система пропусков, видеонаблюдение и отдел...

Shadow Deployment (теневое развертывание) - это методика выпуска программного обеспечения, при которой входящий продуктовый трафик дублируется и отправляется на новую версию приложения. Эта версия работает параллельно с текущей ("боевой") версией. Она обрабатывает запросы, но не возвращает ответы пользователю. Этот подход позволяет инженерам проверить поведение новой системы на реальных данных....

SIMD (Single Instruction, Multiple Data или "Одиночный поток команд, множественный поток данных") — это класс процессорных инструкций, позволяющий выполнить одну операцию одновременно над несколькими элементами данных. Это фундаментальная технология, которая обеспечивает параллелизм вычислений на уровне одного ядра процессора. Вместо того чтобы обрабатывать данные по одному, SIMD позволяет процессору...
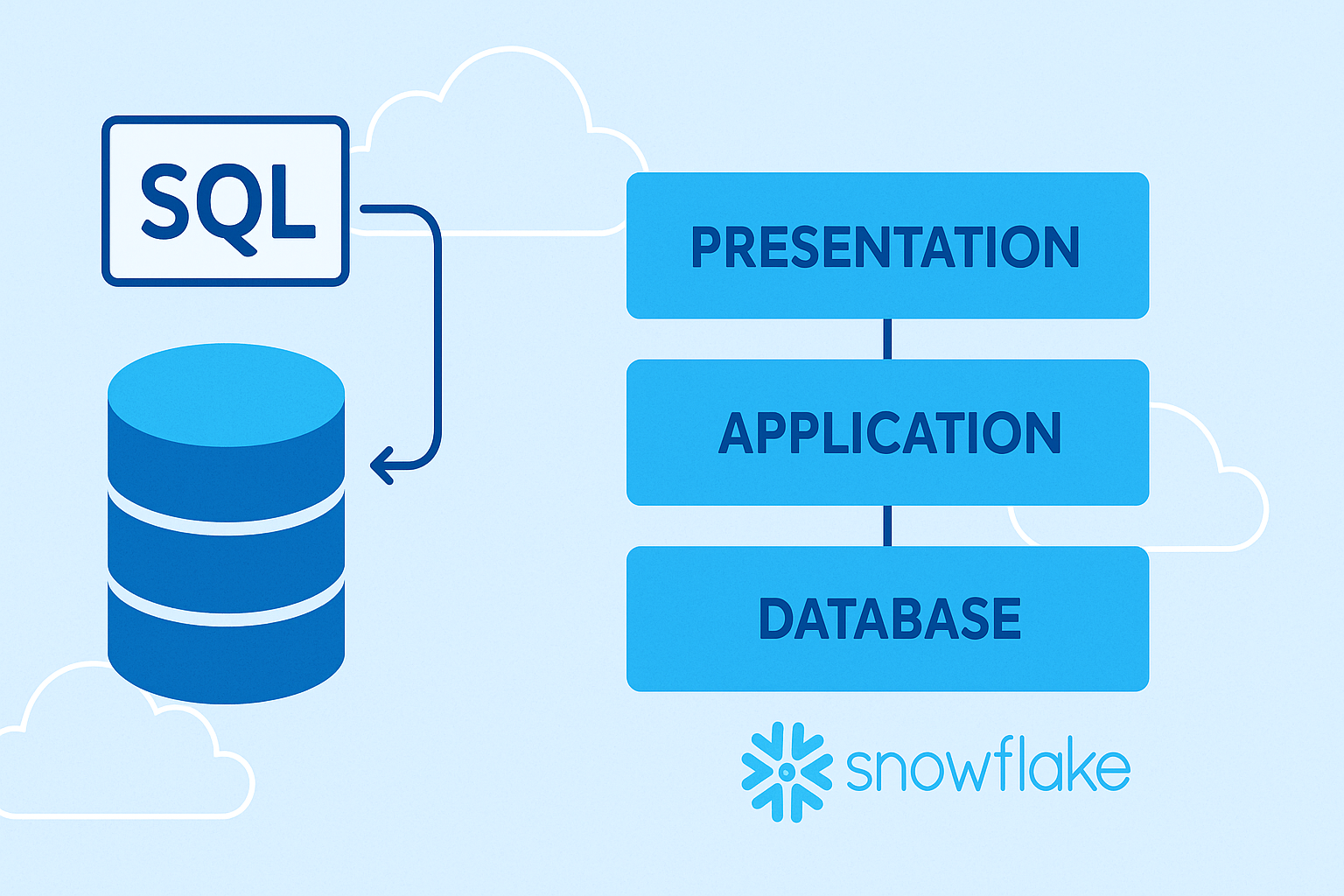
Snowflake — это комплексная облачная платформа данных, предоставляемая по модели «программное обеспечение как услуга» (SaaS), которая в единой среде объединяет функциональность хранилища данных (Data Warehouse), озера данных (Data Lake) и аналитических систем, полностью абстрагируя пользователей от управления базовой инфраструктурой и предоставляя для работы с данными интерфейс на основе стандартного...
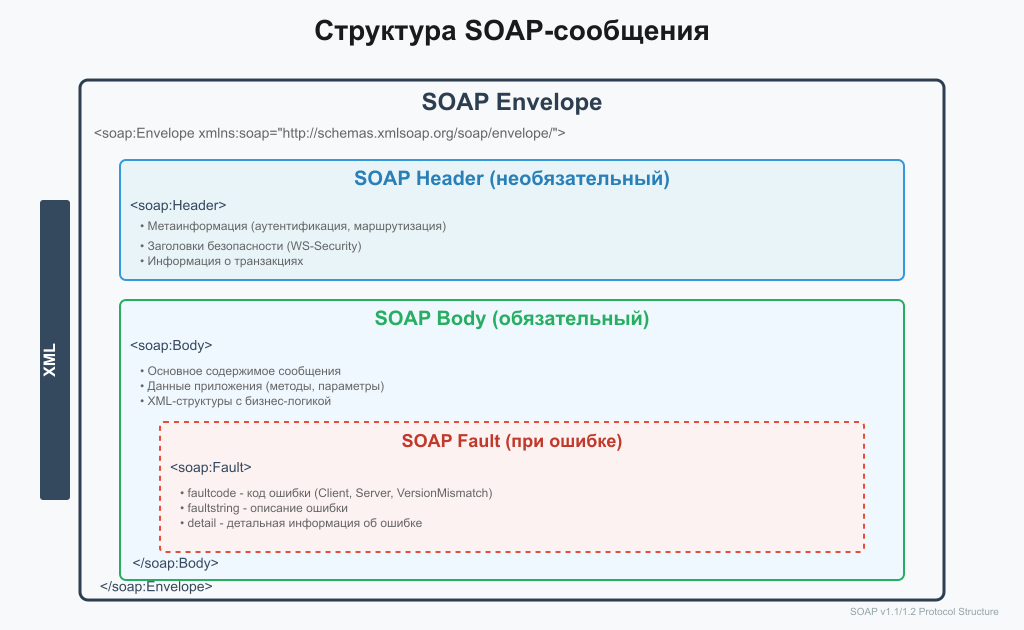
SOAP (изначально Simple Object Access Protocol) — это протокол обмена структурированными сообщениями в распределенной вычислительной среде. В отличие от REST, который является архитектурным стилем, SOAP представляет собой строгий и стандартизированный протокол, регламентированный консорциумом W3C. Его основная задача — обеспечить надежное и безопасное взаимодействие между приложениями, независимо от их...
Spark SQL - это часть Spark Structured API, с помощью этого API Вы можете работать с данными так, как будто Вы работаете с SQL сервером. API работает в обе стороны: результат выполнения SQL запроса - dataframe, в обратном направлении - регистрация существующего dataframe, как таблицы (к которой можно выполнить SQL...

Spark Streaming – это библиотека фреймворка Apache Spark для обработки непрерывных потоковых данных, которая оперирует с дискретизированным потоком DStream, чей API базируется на отказоустойчивой структуре RDD (Resilient Distributed Dataset, надежная распределенная коллекция типа таблицы). Несмотря на позиционирование Spark Streaming в качестве средства потоковой обработки, на самом деле эта библиотека реализует микропакетный подход (micro-batch), интерпретируя поток...

StarRocks — это аналитическая СУБД с MPP-архитектурой, которая умеет напрямую работать с данными в озерах (Hive, Iceberg, Delta Lake) без импорта и поддерживает обновления записей, что редкость для OLAP-систем.Ее главное назначение — это питание интерактивных BI-дэшбордов, аналитика, доступная конечным пользователям, и другие сценарии, где скорость ответа критически важна. Чтобы...
Apache Storm (Сторм, Шторм) – это Big Data фреймворк с открытым исходным кодом для распределенных потоковых вычислений в реальном времени, разработанный на языке программирования Clojure. Изначально созданный Натаном Марцем и командой из BackType, этот проект был открыт с помощью исходного кода, приобретенного Twitter. Первый релиз состоялся 17 сентября 2011 года,...