
Gemini – это семейство передовых мультимодальных моделей искусственного интеллекта (ИИ), разработанное Google DeepMind. Gemini создана с нуля для мультимодальности, что означает способность понимать, обрабатывать и комбинировать различные типы информации, такие как текст, код, изображения, аудио и видео. Модели Gemini предлагаются в различных размерах (Ultra, Pro, Nano) для эффективного применения в...

GIL (Global Interpreter Lock) - это механизм синхронизации в интерпретаторе Python, который обеспечивает выполнение байткода только одним потоком одновременно внутри одного процесса, упрощая управление памятью, но ограничивая параллельное выполнение CPU-интенсивных задач. Данное жесткое правило действует даже на современных мощных многоядерных процессорах. Новички часто сталкиваются с непониманием этого механизма при...
Glove (Global Vectors for Word Representation) - это алгоритм обучения для получения векторных представлений для слов. Обучение выполняется на агрегированной глобальной статистике совпадений слово-слово из корпуса. Полученные представления демонстрируют интересные линейные подструктуры векторного пространства слов, коррелирующие с их семантическим значением.
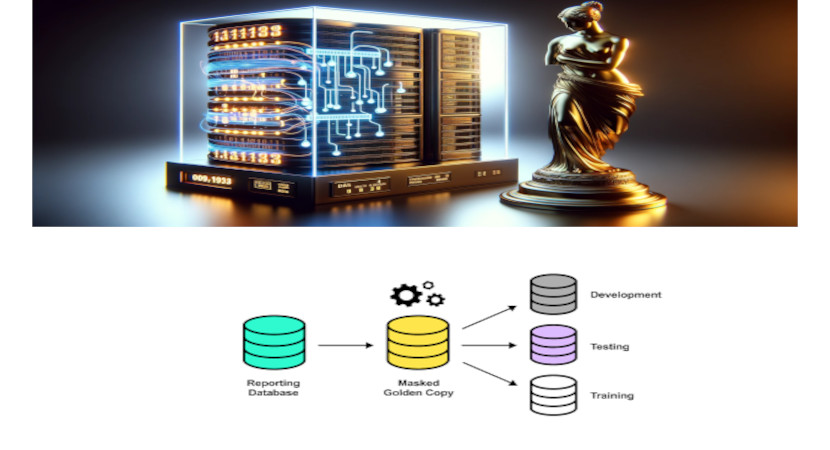
В мире разработки программного обеспечения и управления данными существует понятие "Golden Copy" или "Золотая Копия". Этот термин относится к единственной, авторитетной и доверенной версии данных, которая служит основой для всех других копий в системе. Золотая Копия представляет собой образец данных, который считается источником правды для всей системы. Это позволяет избежать...
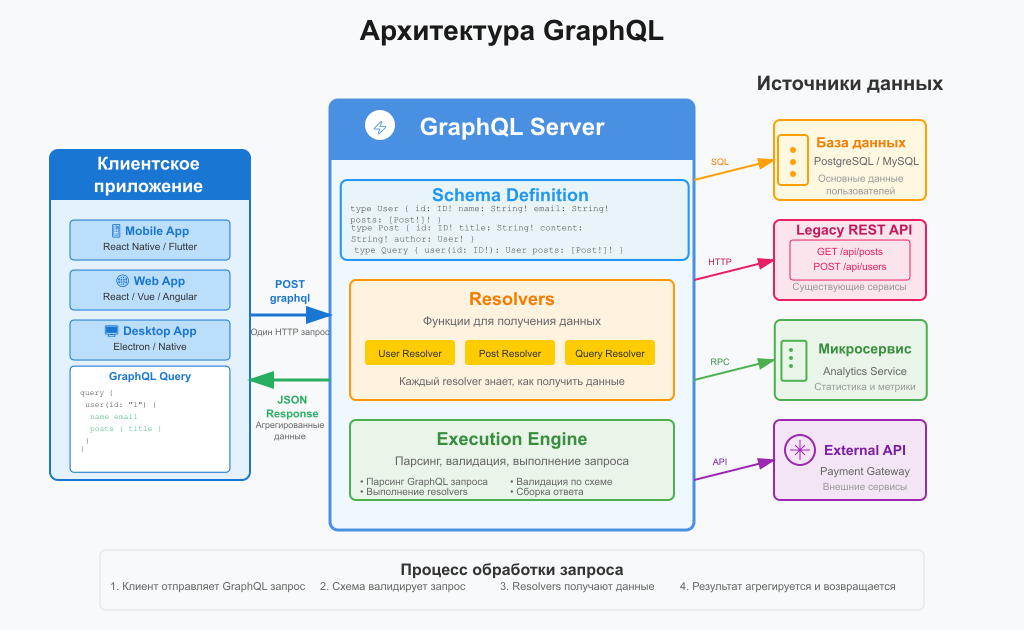
GraphQL — это язык запросов для API и среда выполнения на стороне сервера для обработки этих запросов. Он был разработан компанией Facebook в 2012 году и открыт для публичного использования в 2015 году. Основная цель GraphQL — предоставить клиентам возможность запрашивать только те данные, которые им действительно нужны, и...

Greenplum – open-source продукт, массивно-параллельная реляционная СУБД для хранилищ данных с гибкой горизонтальной масштабируемостью и столбцовым хранением данных на основе PostgreSQL. Благодаря своим архитектурным особенностям и мощному оптимизатору запросов, Гринплам отличается особой надежностью и высокой скоростью обработки SQL-запросов над большими объемами данных, поэтому эта MPP-СУБД широко применяется для аналитики Big...

Hadoop – это свободно распространяемый набор утилит, библиотек и фреймворк для разработки и выполнения распределённых программ, работающих на кластерах из сотен и тысяч узлов. Эта основополагающая технология хранения и обработки больших данных (Big Data) является проектом верхнего уровня фонда Apache Software Foundation. Из чего состоит Hadoop: концептуальная архитектура Изначально проект...

Apache HBase – это нереляционная, распределенная база данных с открытым исходным кодом, написанная на языке Java по аналогии BigTable от Google. Изначально эта СУБД класса NoSQL создавалась компанией Powerset в 2007 году для обработки больших объёмов данных в рамках поисковой системы на естественном языке. Проектом верхнего уровня Apache Software Foundation HBase стала...
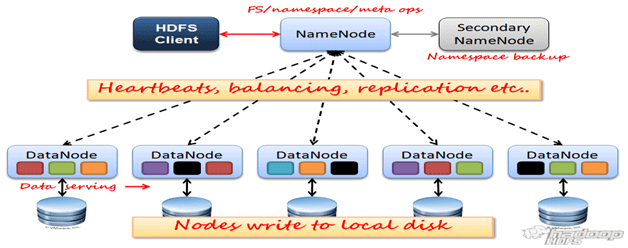
HDFS (Hadoop Distributed File System) — распределенная файловая система Hadoop для хранения файлов больших размеров с возможностью потокового доступа к информации, поблочно распределённой по узлам вычислительного кластера [1], который может состоять из произвольного аппаратного обеспечения [2]. Hadoop Distributed File System, как и любая файловая система – это иерархия каталогов с...

HDInsight - это корпоративный сервис с открытым кодом от Microsoft для облачной платформы Azure, позволяющий работать с кластером Apache Hadoop в облаке в рамках управления и аналитической работы с большими данными (Big Data). Экосистема HDInsight Azure HDInsight – это облачная экосистема компонентов Apache Hadoop на основе платформы данных Hortonworks Data Platform...
Apache Hive - это SQL интерфейс доступа к данным для платформы Apache Hadoop. Hive позволяет выполнять запросы, агрегировать и анализировать данные используя SQL синтаксис. Для данных в файловой системе HDFS используется схема доступа на чтение, позволяющая обращаться с данными, как с обыкновенной таблицей или реляционной СУБД. Запросы HiveQL транслируются в Java-код...

Hortonworks Data Platform (HDP) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит Apache Software Foundation, адаптированных компанией Hortonworks для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый [1]. Помимо HDP, компания Hortonworks предлагает еще другие продукты для Big Data и Machine Learning,...

Impala – это массив-параллельный механизм интерактивного выполнения SQL-запросов к данным, хранящимся в Apache Hadoop (HDFS и HBase), написанный на языке С++ и распространяющийся по лицензии Apache 2.0. Также Импала называют MPP-движком (Massively Parallel Processing), распределенной СУБД и даже базой данных стека SQL-on-Hadoop. Как появился Apache Impala и чем это связано...
Internet of Things (Интернет вещей) означает сеть физических или виртуальных предметов (вещей) подключенных напрямую или опосредованно к интернету и взаимодействующие между собой и/или с внешней средой посредством сбора данных и обмена данных поступающих со встроенных сервисов. Интернет вещей (IoT) дает компаниям и организациям возможность контролировать удаленно расположенные «дешевые» вещи /объекты ...

IPython (Interactive Python) - это продвинутая интерактивная командная оболочка для языка Python, которая превращает процесс кодинга из монотонного ввода текста в динамическое исследование данных. В мире Big Data и Data Science стандартного интерпретатора Python (python.exe или просто python в терминале) часто недостаточно. Он аскетичен, не запоминает контекст и...
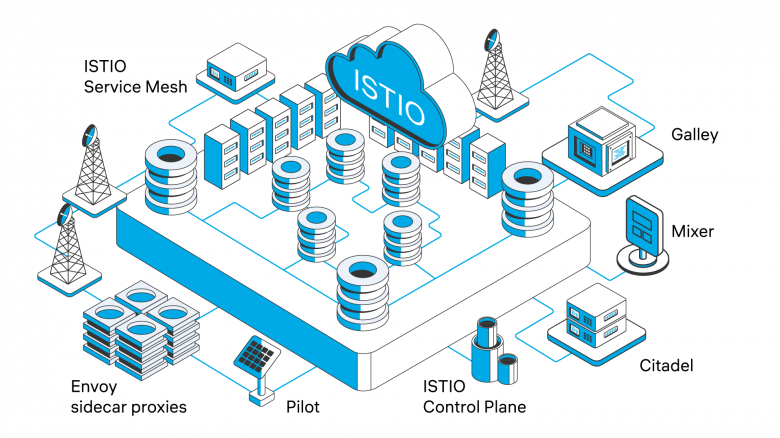
Istio — это платформа с открытым исходным кодом для реализации концепции Service Mesh (сервисная сетка). Она представляет собой выделенный инфраструктурный слой, который прозрачно интегрируется в существующую распределенную систему, чаще всего на базе Kubernetes. Основная задача Istio — взять на себя всю сложность межсетевого взаимодействия микросервисов, позволяя централизованно управлять...

Jupyter Notebook - это интерактивная веб-среда разработки, которая позволяет объединить исполняемый код, наглядные визуализации и форматированный текст в одном документе. Это стандарт де-факто для Data Science, машинного обучения и, с недавних пор, дата-инжиниринга. Название проекта - это игра слов. С одной стороны, это отсылка к трем основным языкам программирования,...

Kafka Consumer – это программный компонент (или программный код / библиотека), который интегрируется в клиентское приложение и предназначен для надежного и эффективного чтения данных (сообщений) из одного или нескольких топиков Apache Kafka, обычно работающий в составе группы потребителей для обеспечения масштабируемой и отказоустойчивой обработки потоков информации, активно взаимодействуя с...

Kafka Producer – это программный компонент (или программный код / библиотека), интегрируемый в клиентское приложение, предназначенный для отправки данных (сообщений) в один или несколько топиков Apache Kafka, который эффективно взаимодействует с брокерами для надежной и высокопроизводительной записи информации, обеспечивая при этом различные гарантии доставки сообщений. Производители создают записи, содержащие...
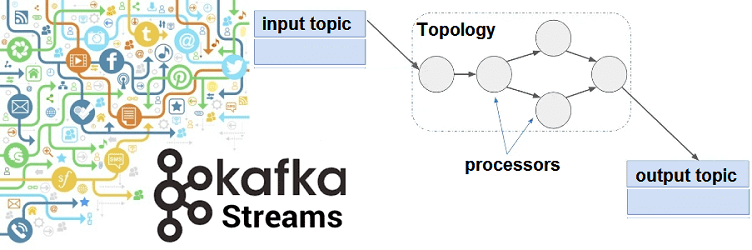
Kafka Streams – это клиентская библиотека для разработки потоковых приложений Big Data, которые работают с данными, хранящимися в топиках Apache Kafka. Она предоставляет мощный и гибкий API-интерфейс со всеми преимуществами Кафка-платформы (масштабируемость, надежность, минимальную задержку, механизмы аналитических запросов), позволяя разработчику писать код в локальном режиме (вне кластера). Kafka Streams API,...