
Bloom filter ( Фильтр Блума) - это высокоэффективная вероятностная структура данных. Она позволяет очень быстро проверять, принадлежит ли элемент некоторому множеству. Представьте себе охранника на входе в эксклюзивный клуб. У него нет полного списка имен гостей, а есть только блокнот с отметками. Когда гость приходит, охранник быстро проверяет отметки....
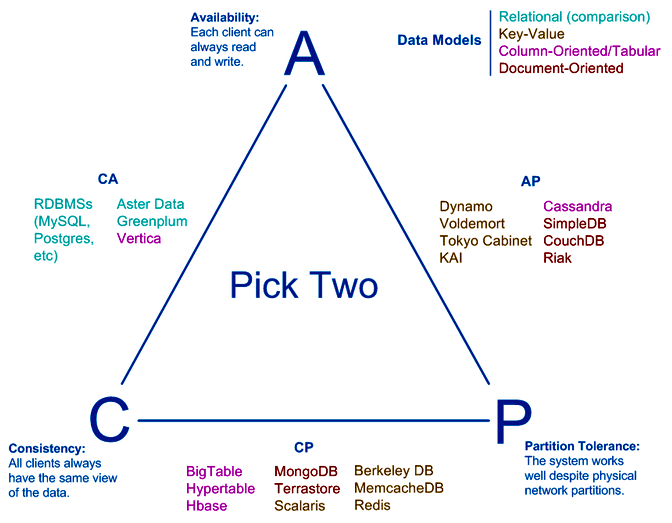
CAP – это акроним от англоязычных слов Consistency (Согласованность, Целостность), Availability (Доступность) и Partition tolerance (Устойчивость к разделению). Согласно утверждению профессора Калифорнийского университета в Беркли, Эрика Брюера, сделанному в 2000-м году, в распределенных системах осуществимы лишь 2 свойства из указанных 3-х. В частности, считается что нереляционные базы данных жертвуют согласованностью данных в...
Case Based Reasoning (CBR) - метод решения проблем рассуждением по аналогии, путем предположения на основе подобных случаев (прецедентов). Это способ решения проблем на основе уже известных решений, который широко применяется во всех областях деятельности. Например, в бизнес-анализе такое сопоставление с эталоном, целенаправленный поиск и внедрение лучших практик со стороны называется...

Apache Cassandra – это нереляционная отказоустойчивая распределенная СУБД, рассчитанная на создание высокомасштабируемых и надёжных хранилищ огромных массивов данных, представленных в виде хэша. Проект был разработан на языке Java в корпорации Facebook в 2008 году, и передан фонду Apache Software Foundation в 2009 [1]. Эта СУБД относится к гибридным NoSQL-решениям, поскольку она...

Chain-of-Thought (CoT), или "Цепочка Мыслей", — это не сложная архитектура или новая модель, а техника промптинга. Ее суть — заставить Большую Языковую Модель (LLM) генерировать пошаговую цепочку рассуждений до того, как она даст финальный ответ. Это похоже на то, как в школе учитель просит показать ход решения задачи,...
Churn Rate (уровень оттока клиентов) - индикатор, показывающий процент пользователей, которые перестали пользоваться приложением (сервисом) или перестали быть вашим клиентом в течение рассматриваемого периода. Для уменьшения оттока клиентов используют таргетированные маркетинговые кампании для удержания клиентов с помощью персональных бонусов, скидок и предложения. Для успешной компании уровень оттока клиентов (Churn Rate) должен...

Claude AI - передовая система искусственного интеллекта, разработанная компанией Anthropic. Claude AI-ассистент выделяется среди конкурентов благодаря своим уникальным возможностям в области обработки естественного языка, безопасности и этичности взаимодействий. Claude был создан с использованием инновационной методологии Constitutional AI, что делает его одним из самых надежных и безопасных ИИ-помощников на современном...

Claude Code - это специализированный интерфейс командной строки (CLI) для разработки программного обеспечения на базе моделей Claude от компании Anthropic, предназначенный для генерации, анализа, рефакторинга и объяснения кода, а также помощи в разработке и сопровождении проектов через естественный язык, превращающий языковую модель в автономного программного агента. Инструмент разработан компанией...

ClickHouse – колоночная реляционная СУБД с открытым исходным кодом от компании Яндекс для быстрой обработки аналитических SQL-запросов на структурированных больших данных (Big Data) в режиме реального времени.
ClickHouse Certified Developer — это официальная сертификация от разработчиков СУБД ClickHouse, подтверждающая практические навыки и знания специалистов в области работы с ClickHouse. Сертификат выдаётся после прохождения онлайн-экзамена, который включает реальные задания в среде clickhouse-client. Это единственная вендорская сертификация по ClickHouse, признанная в международном сообществе. Что такое ClickHouse Certified Developer...
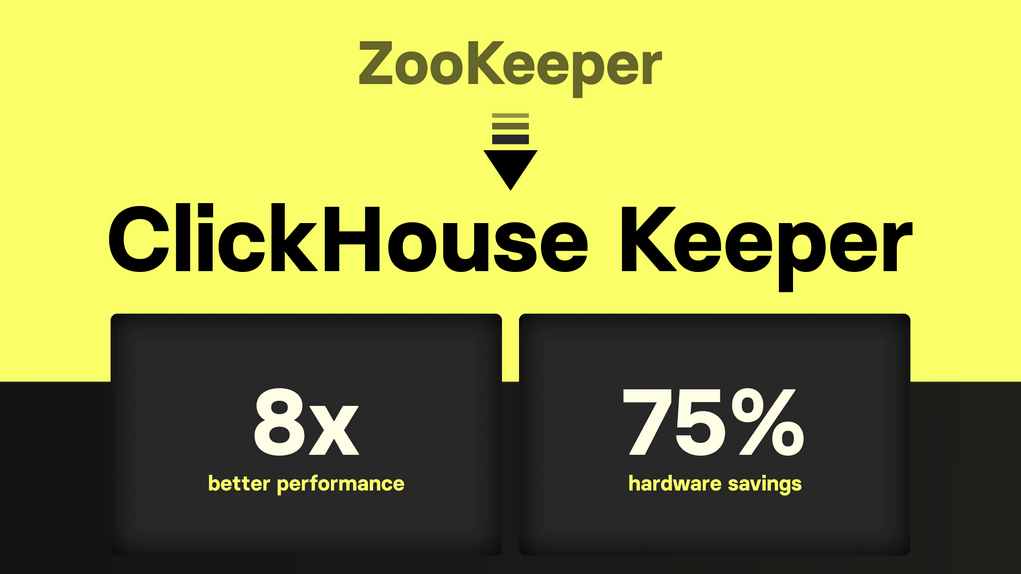
ClickHouse Keeper — это распределенная система координации. Она обеспечивает согласованность данных в кластере ClickHouse. Этот компонент был разработан как встроенная альтернатива Apache ZooKeeper. Таким образом, он устраняет внешние зависимости. ClickHouse Keeper играет ключевую роль в репликации и отказоустойчивости. Он управляет метаданными для реплицируемых таблиц. Кроме того, он координирует выполнение...
Облачные вычисления (Cloud Computing) - это модель предоставления вычислительных ресурсов (вычисления, хранение, сети и платформенные сервисы) по требованию через сеть с эластичным масштабированием, оплатой по факту использования и абстрагированием физической инфраструктуры от пользователя. Простыми словами, это переход от владения собственным "железом" к его аренде как коммунальной услуги. Вы...

Cloudera CDH (Cloudera’s Distribution including Apache Hadoop) — дистрибутив Apache Hadoop с набором программ, библиотек и утилит, разработанных компанией Cloudera для больших данных (Big Data) и машинного обучения (Machine Learning), бесплатно распространяемый и коммерчески поддерживаемый для некоторых Linux-систем (Red Hat, CentOS, Ubuntu, SuSE SLES, Debian) [1]. Состав и архитектура Клаудера...
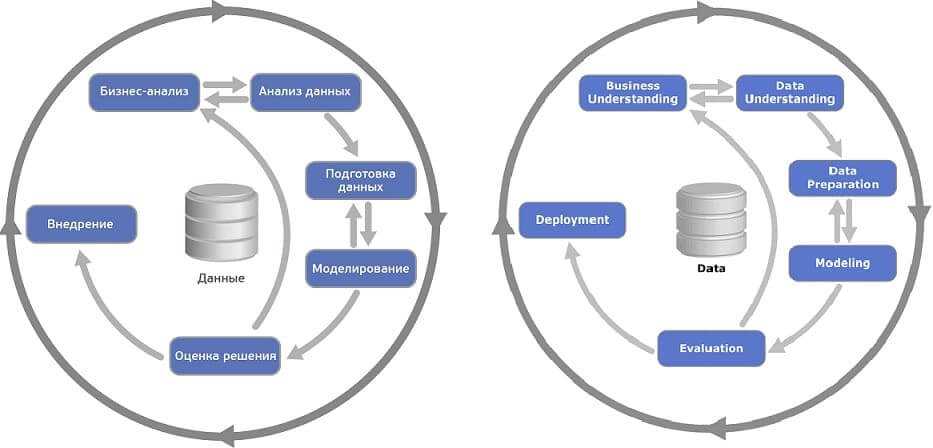
CRISP-DM (от английского Cross-Industry Standard Process for Data Mining) — межотраслевой стандартный процесс исследования данных. Это проверенная в промышленности и наиболее распространённая методология, первая версия которой была представлена в Брюсселе в марте 1999 года, а пошаговая инструкция опубликована в 2000 году [1]. CRISP-DM описывает жизненный цикл исследования данных, состоящий из...

Cursor — это интеллектуальная интегрированная среда разработки (IDE), созданная на основе VS Code, которая использует передовые большие языковые модели (LLM) для глубокого анализа, написания и отладки программного кода. Cursor позиционируется не как дополнение, а как самостоятельный инструмент с нативной поддержкой ИИ1. Главная особенность редактора заключается в его способности...
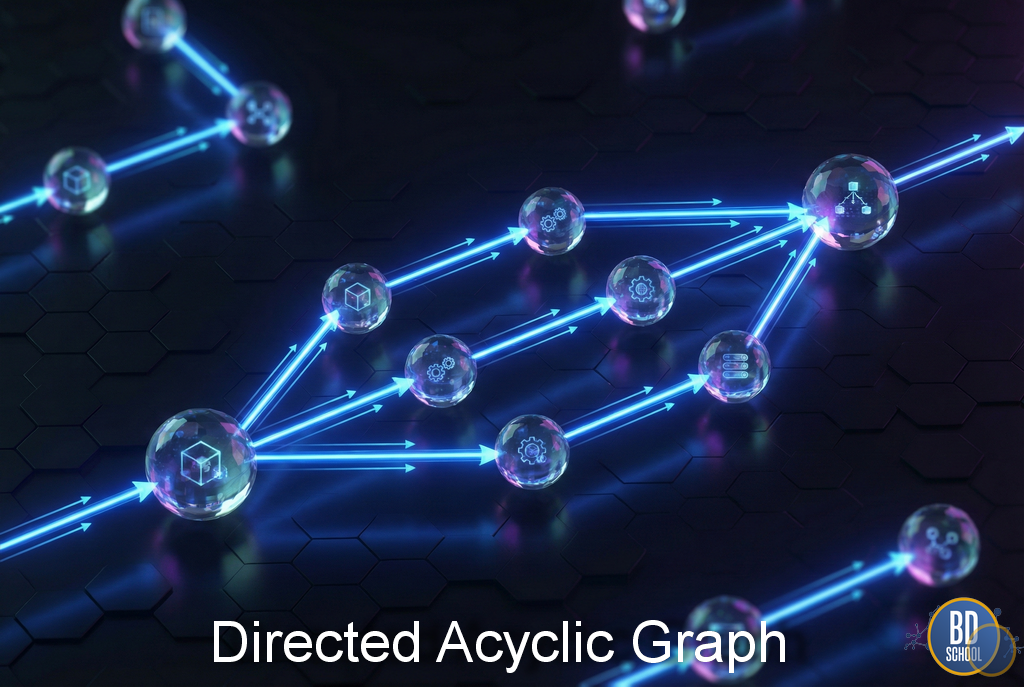
DAG (Directed Acyclic Graph) - это ориентированная ацикличная структура, используемая для формального описания зависимостей и упорядочивания вычислительных процессов таким образом, чтобы исключить циклы и обеспечить строго определённую последовательность выполнения. В отличие от простых списков дел, DAG позволяет моделировать сложные нелинейные процессы, где одни задачи могут выполняться параллельно, а...

Dagster — это оркестратор данных, предназначенный для разработки, выполнения и мониторинга пайплайнов обработки данных на основе DAG, с акцентом на типизацию данных, тестируемость и прозрачность выполнения. Главная цель этого инструмента состоит в управлении активами данных. Активы включают таблицы, файлы и модели машинного обучения. Традиционные оркестраторы фокусируются исключительно на порядке...
Dask — это гибкая библиотека для параллельных вычислений на Python, которая позволяет масштабировать привычные инструменты, такие как NumPy, Pandas и Scikit-learn, для работы с большими данными. Dask: Что это такое Привет! Сегодня поговорим о Dask. Если ты хоть раз сталкивался с ситуацией, когда твой любимый Pandas падал с...
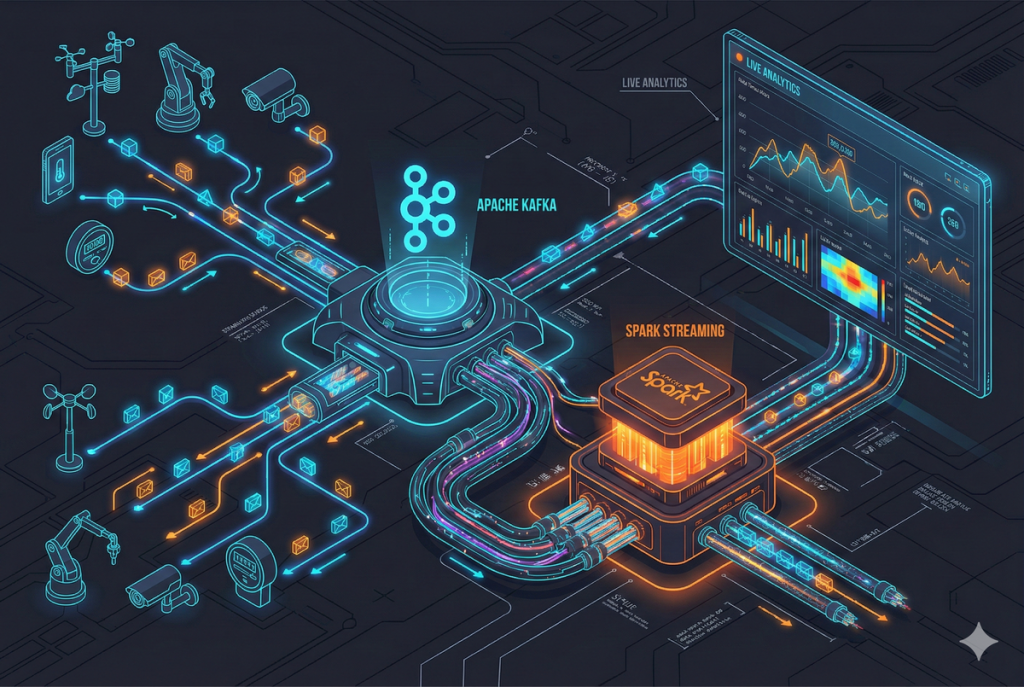
Dataflow, или поток данных, представляет собой концепцию, важную для понимания того, как данные перемещаются и обрабатываются в программном коде. Эта концепция играет ключевую роль в различных областях программирования, включая параллельное программирование, асинхронное выполнение и обработку событий. В программировании поток данных представляет собой направление перемещения данных от одного участка кода к...

Data Governance (DG) — это организация стратегического управления данными в компании. На практике она реализуется через фреймворк, который включает в себя систему правил, процессов, политик и зон ответственности. Этот фреймворк определяет, как организация управляет своими данными на протяжении всего их жизненного цикла — от создания до архивации или удаления...