 1304
1304 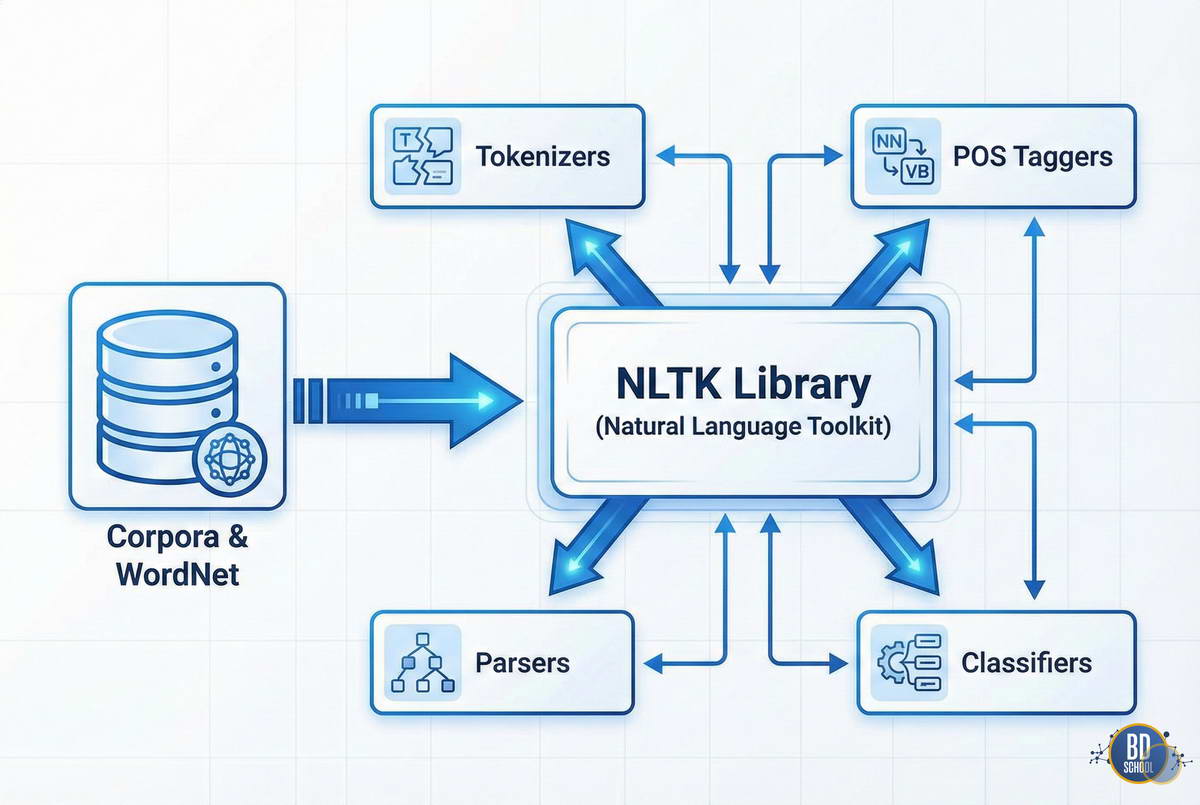
Содержание
- Архитектура и экосистема данных
- Ключевые этапы обработки текста в NLTK
- Лингвистический анализ и извлечение признаков
- Взаимодействие и код: Практика в WSL
- NLTK vs Modern NLP: SpaCy и Hugging Face
- Продвинутые фишки и работа с WordNet
- Обучение собственного классификатора текстов (nltk.classify)
- Пример реализации на Python
- Сценарии использования в реальных задачах
- Заключение
- Референсные ссылки:
NLTK — это ведущая платформа для создания программ на языке Python для работы с данными на естественном языке. Она предоставляет простые интерфейсы для более чем 50 корпусов и лексических ресурсов. Библиотека включает набор инструментов для обработки текста, таких как токенизация, классификация и тегирование. NLTK часто называют «учебной лабораторией» для лингвистов и разработчиков искусственного интеллекта. В этой статье мы разберем, как эффективно использовать этот мощный инструмент в 2025 году.
Архитектура и экосистема данных
Библиотека NLTK построена по модульному принципу, что обеспечивает гибкость в разработке. Она состоит из набора независимых модулей для конкретных задач лингвистического анализа.
Основу экосистемы составляют корпусы данных и лексические ресурсы. Корпуса представляют собой огромные коллекции текстов, размеченных вручную или автоматически.
Работа с NLTK обычно начинается с загрузки необходимых данных. В среде WSL (Windows Subsystem for Linux) это делается через встроенный загрузчик.
Для управления ресурсами в NLTK используются следующие компоненты:
- Корпуса. Сборники текстов, такие как Brown Corpus или Gutenberg.
- Лексические ресурсы. Словари и базы данных слов, например WordNet.
- Грамматики. Наборы правил для синтаксического анализа предложений.
- Обученные модели. Готовые файлы для классификации и распознавания сущностей.
Эти компоненты позволяют разработчикам не собирать данные вручную, а сразу переходить к анализу текстов на профессиональном уровне.
Ключевые этапы обработки текста в NLTK
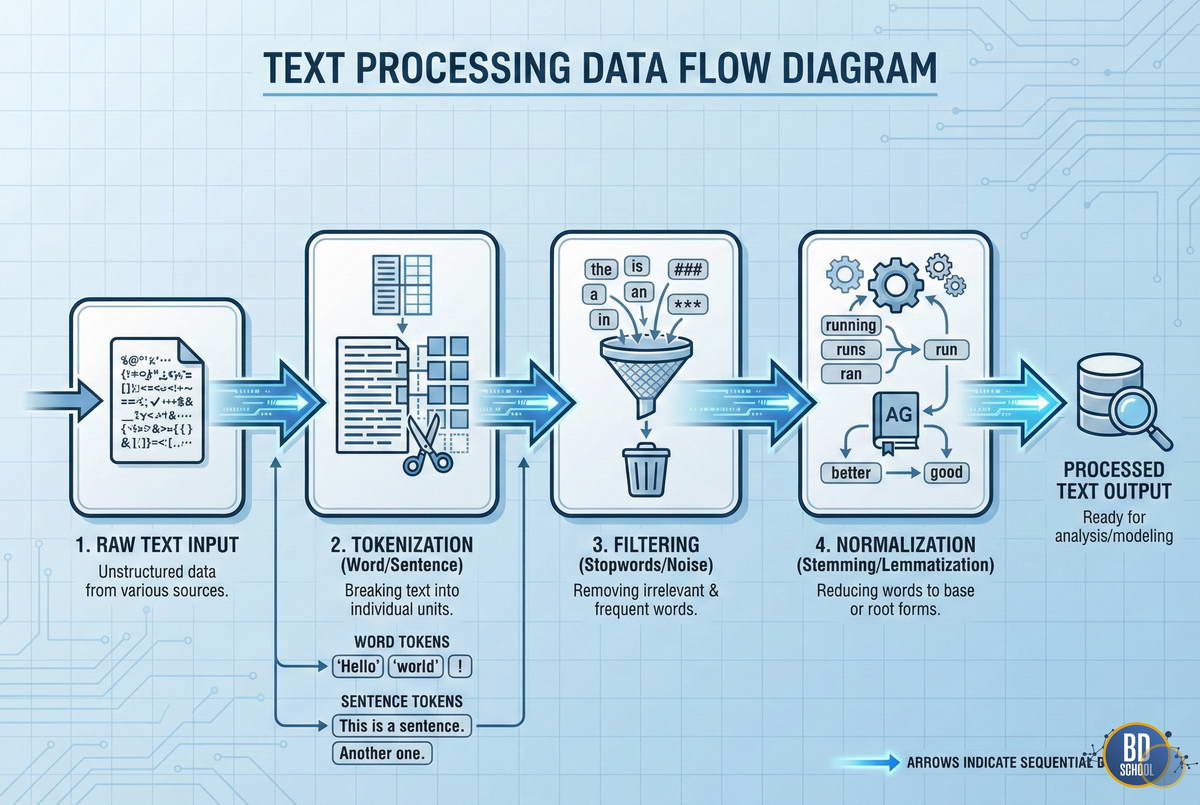
Механика работы с текстом в NLTK следует стандартному пайплайну NLP. Сначала сырые данные превращаются в структурированные токены. Затем происходит очистка от шума и приведение слов к нормальной форме.
Токенизация
Токенизация — это процесс разбиения текста на мелкие части. Это могут быть отдельные слова, символы или целые предложения. NLTK предлагает специализированные токенизаторы для разных задач.
Очистка и стоп-слова
Тексты часто содержат «мусорные» слова, которые не несут смысловой нагрузки. Это предлоги, союзы и частицы, называемые стоп-словами. В NLTK есть встроенные списки таких слов для многих языков мира.
Нормализация: Стемминг и Лемматизация
Нормализация помогает объединить разные формы одного слова. Это критически важно для поиска и анализа тональности. Существует два основных подхода к этой задаче.
Сравнение подходов к нормализации представлено в таблице ниже:
| Характеристика | Стемминг (Stemming) | Лемматизация (Lemmatization) |
| Метод | Отсечение окончаний по правилам | Использование словарей и морфологии |
| Результат | Может создать несуществующее слово | Всегда возвращает словарную форму |
| Скорость | Очень высокая | Ниже из-за поиска в базе |
| Точность | Средняя | Высокая |
Оба метода имеют свои плюсы в зависимости от вычислительных ресурсов проекта. Стемминг подходит для быстрых поисковых движков. Лемматизация идеальна для глубокого анализа смысла текста.
Лингвистический анализ и извлечение признаков
После базовой очистки данных наступает этап извлечения смысловых признаков. NLTK позволяет проводить глубокий анализ структуры языка.
POS-tagging (Part-of-Speech tagging) — это процесс определения части речи для каждого слова. Алгоритм учитывает контекст и соседние токены. Это необходимо для понимания синтаксической роли слова в предложении.
NER (Named Entity Recognition) — распознавание именованных сущностей. Инструмент находит в тексте имена людей, названия компаний и географические объекты. NLTK использует для этого предварительно обученные классификаторы.
Чанкинг (Chunking) или «неглубокий парсинг» помогает выделять целые фразы. Например, можно извлечь все группы существительных с их прилагательными. Это полезно для извлечения ключевых фактов из документов.
Взаимодействие и код: Практика в WSL
Для работы в WSL на Python сначала нужно настроить окружение. Рекомендуется использовать виртуальные среды для изоляции зависимостей.
Установите библиотеку с помощью менеджера пакетов:
#--- Предварительно установите библиотеки в venv среде python3 -m venv venv/ source venv/bin/activate pip3 install nltk
В WSL работа с загрузчиком ресурсов может потребовать явного указания директорий. Ниже приведен пример скрипта для базовой обработки текста.
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
# Загрузка необходимых ресурсов (нужно выполнить один раз)
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('omw-1.4')
nltk.download('punkt_tab')
text = "The quick brown foxes are jumping over the lazy dogs."
# 1. Токенизация
tokens = word_tokenize(text.lower())
# 2. Удаление стоп-слов
stop_words = set(stopwords.words('english'))
filtered_tokens = [w for w in tokens if w.isalpha() and w not in stop_words]
# 3. Лемматизация
lemmatizer = WordNetLemmatizer()
lemmas = [lemmatizer.lemmatize(w) for w in filtered_tokens]
print(f"Original: {text}")
print(f"Processed: {lemmas}")
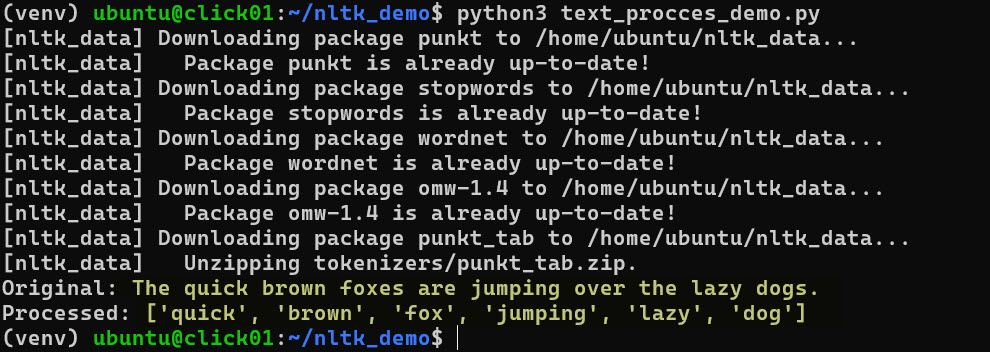
Этот код демонстрирует полный цикл подготовки данных для моделей машинного обучения. Он работает стабильно в любой Linux-подобной среде, включая WSL. Важно следить за актуальностью версий загружаемых пакетов через менеджер ресурсов.
Нейронные сети на Python
Код курса
PYNN
Ближайшая дата курса
20 июля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
NLTK vs Modern NLP: SpaCy и Hugging Face
В 2025 году NLTK часто сравнивают с современными библиотеками. Каждая из них занимает свою нишу в разработке AI-решений.
NLTK остается непревзойденным инструментом для исследователей и студентов. Он позволяет вручную настраивать каждый шаг обработки. Современные библиотеки, такие как SpaCy, больше ориентированы на промышленное использование.
Ключевые отличия NLTK от конкурентов:
- Прозрачность. Вы точно знаете, какой алгоритм используется для каждого этапа.
- Гибкость. Легко заменить стандартный токенизатор на собственную реализацию.
- Ресурсы. Прямой доступ к WordNet и огромному количеству редких лингвистических корпусов.
- Обучение. Лучшая документация для понимания теоретических основ NLP.
Для задач продакшена с высокой нагрузкой часто выбирают SpaCy. Однако для прототипирования новых методов NLTK остается приоритетным выбором. В сложных проектах эти инструменты часто комбинируют между собой.
Продвинутые фишки и работа с WordNet
WordNet — это одна из самых ценных частей экосистемы NLTK. Это лексическая база данных английского языка, организованная в виде графа. Слова в WordNet сгруппированы в наборы синонимов, называемые синсетами (synsets). Это позволяет вычислять семантическое расстояние между понятиями. Вы можете программно определить, насколько слово «собака» близко к слову «животное».
Использование WordNet в Python расширяет возможности анализа:
- Поиск гиперонимов. Определение более общих понятий для конкретного слова.
- Поиск антонимов. Автоматический подбор противоположных по смыслу слов.
- Сходство смыслов. Оценка близости текстов на уровне идей, а не букв.
Такой подход позволяет создавать более умные системы поиска и классификации. Традиционные методы часто не видят связи между синонимами, но NLTK успешно решает эту задачу.
Обучение собственного классификатора текстов (nltk.classify)
Классификация текстов — это задача автоматического присвоения категорий документам на основе их содержания. В NLTK для этих целей чаще всего используется классификатор Naive Bayes (Наивный Байес). Этот алгоритм основан на применении теоремы Байеса со строгими допущениями о независимости признаков.
Математически вероятность принадлежности текста к классу выражается формулой:
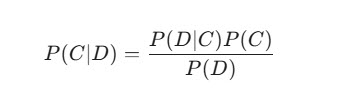
Где $C$ — класс, а $D$ — документ (набор слов). Несмотря на простоту, этот метод показывает отличные результаты на небольших наборах данных.
Процесс подготовки признаков
Для обучения модели текст нельзя использовать в «сыром» виде. Его нужно преобразовать в набор числовых или логических признаков. В NLTK это обычно делается через формирование словаря, где ключом выступает слово, а значением — его наличие в тексте.
Процесс обучения в среде WSL включает следующие логические этапы.
Сбор данных. Мы используем готовый корпус отзывов к фильмам.
- Загрузка пакета movie_reviews через nltk.download.
- Разметка данных на «положительные» и «отрицательные».
Извлечение признаков. Мы выбираем наиболее частотные слова во всем корпусе.
- Создание списка из 2000 самых популярных слов.
- Проверка наличия этих слов в каждом конкретном отзыве.
Разделение выборки. Данные делятся на обучающую и тестовую части.
- Обучающая выборка нужна для «тренировки» алгоритма.
- Тестовая выборка используется для проверки точности на новых данных.
Такой подход позволяет избежать переобучения, когда модель просто заучивает примеры, но не может анализировать новый текст.
Пример реализации на Python
Ниже приведен готовый код для запуска в консоли WSL. Он демонстрирует создание простого детектора тональности.
import nltk
import random
from nltk.corpus import movie_reviews
# 1. Загрузка данных
nltk.download('movie_reviews')
# Подготовка списка документов (текст, категория)
documents = [(list(movie_reviews.words(fileid)), category)
for category in movie_reviews.categories()
for fileid in movie_reviews.fileids(category)]
# Перемешиваем данные для объективности
random.shuffle(documents)
# 2. Определение признаков
all_words = nltk.FreqDist(w.lower() for w in movie_reviews.words())
word_features = list(all_words)[:2000]
def document_features(document):
document_words = set(document)
features = {}
for word in word_features:
features[f'contains({word})'] = (word in document_words)
return features
# 3. Обучение
featuresets = [(document_features(d), c) for (d, c) in documents]
train_set, test_set = featuresets[100:], featuresets[:100]
classifier = nltk.NaiveBayesClassifier.train(train_set)
# 4. Результаты
print(f"Точность модели: {nltk.classify.accuracy(classifier, test_set):.2%}")
classifier.show_most_informative_features(10)
В результате работы скрипта вы увидите точность классификации и список слов, которые сильнее всего влияют на вердикт. Например, слово «outstanding» (выдающийся) может в разы повышать вероятность того, что отзыв будет помечен как положительный.
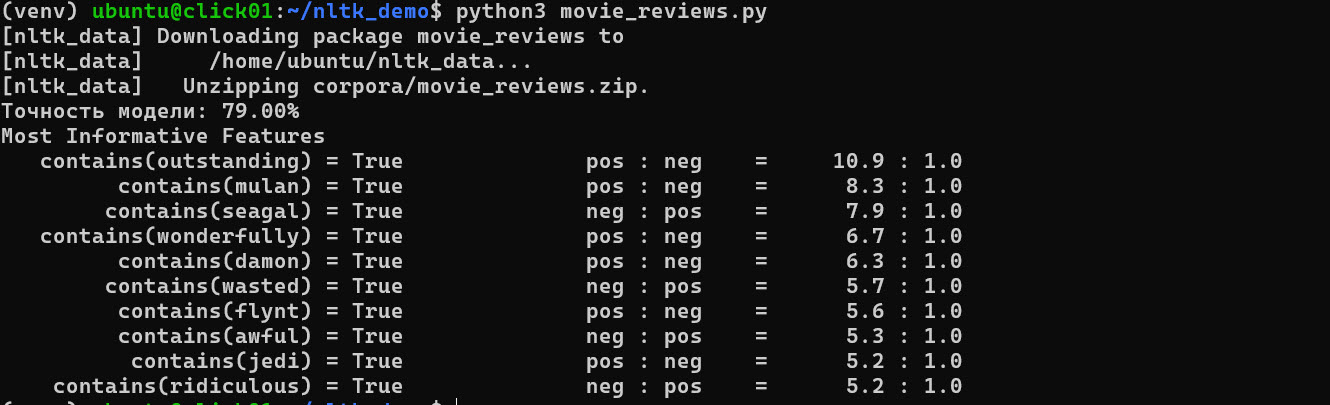
Метод show_most_informative_features является мощным инструментом интерпретации. Он помогает понять, на чем именно основывается «мнение» вашей модели. Это критически важно для отладки и улучшения пайплайна обработки естественного языка в коммерческих проектах.
Сценарии использования в реальных задачах
NLTK находит применение во многих сферах, где требуется обработка текстовой информации. Несмотря на возраст, библиотека успешно справляется с современными вызовами.
Одним из популярных сценариев является анализ тональности. С помощью NLTK можно быстро построить классификатор для отзывов клиентов. Библиотека содержит готовый модуль VADER, оптимизированный для текстов из социальных сетей.
Другие важные сферы применения включают в себя:
- Автоматическое реферирование. Извлечение наиболее важных предложений из длинных статей.
- Детекция спама. Фильтрация сообщений на основе частотного анализа слов.
- Исправление опечаток. Создание систем проверки правописания на основе языковых моделей.
Эти задачи решаются путем комбинации методов статистического анализа и лингвистических правил. NLTK предоставляет для этого все необходимые строительные блоки в одном пакете.
ML Практикум: от теории к промышленному использованию
Код курса
PYML
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Заключение
NLTK остается незаменимым инструментом в арсенале любого специалиста по данным. Библиотека гармонично сочетает в себе научную строгость и простоту использования. Даже в эпоху больших языковых моделей (LLM) навыки работы с NLTK крайне полезны. Они позволяют эффективно подготавливать данные и выполнять пост-обработку результатов работы нейросетей. Понимание классических методов NLP дает разработчику преимущество при создании сложных и надежных систем.
Референсные ссылки:
- [NLTK Official Documentation 2024] (https://www.nltk.org/)
- [Python for Natural Language Processing (PyPI)] (https://pypi.org/project/nltk/)
- [Natural Language Processing with Python (Book update 2024)] (https://www.nltk.org/book/)
- [Modern NLP Pipelines: From NLTK to Transformers] (https://towardsdatascience.com/)
- [WSL 2 Guide for Data Science] (https://learn.microsoft.com/en-us/windows/wsl/setup/environment)