 2323
2323 
Содержание
- Что такое Apache Kafka и почему это не RabbitMQ
- Ключевые аспекты и архитектура Apache Kafka
- Брокеры, Топики и Партиции
- Продюсеры и Консьюмеры
- Consumer Groups и Offset
- Как Kafka обеспечивает надежность и скорость
- Репликация и ISR (In-Sync Replicas)
- Zero-copy и Sequential I/O
- Паттерны проектирования топиков и ключей
- Admin API
- ZooKeeper и KRAFT
- Сценарии использования Apache Kafka в реальных проектах
- Развертывание Apache Kafka 4.2.0 в режиме KRaft на Ubuntu
- Подготовка системы и установка
- Конфигурация KRaft для Kafka кластера
- Базовые команды для работы с данными
- Создание топика
- Отправка сообщений (Продюсер)
- Чтение сообщений (Консьюмер)
- Экосистема за пределами ядра (Connect и Streams)
- Основные дистрибутивы и расширения Apache Kafka
- Основные конкуренты Apache Kafka
- Заключение
- Референсные ссылки:
Apache Kafka – это высокопроизводительная распределенная потоковая платформа с открытым исходным кодом, разработанная изначально в LinkedIn, которая позволяет приложениям публиковать, подписываться, хранить и обрабатывать потоки записей в реальном времени, обеспечивая при этом высокую пропускную способность, масштабируемость и отказоустойчивость для широкого круга сценариев использования, включая обработку больших данных и микросервисные архитектуры.
Эта платформа функционирует как распределенный журнал транзакций. Она способна обрабатывать триллионы событий в день. Таким образом, Kafka стала стандартом де-факто для построения потоковых конвейеров данных. Она используется многими крупными компаниями. Ее надежность и производительность делают ее идеальным решением для современных распределенных систем.
Что такое Apache Kafka и почему это не RabbitMQ
Многие новички часто путают Kafka с классическими очередями сообщений. Традиционные брокеры обычно удаляют сообщение сразу после его успешного прочтения клиентом. В Apache Kafka данные сохраняются на диске в течение заданного периода времени. Вы можете перечитывать одни и те же события многократно разными приложениями. Это делает платформу идеальным хранилищем для событийной архитектуры и аналитики.
Главное архитектурное различие кроется в способе доставки данных потребителям. В очередях брокер сам «толкает» сообщения в сторону подписчиков. Kafka использует модель вытягивания (pull), где потребители сами запрашивают нужные данные. Такой подход предотвращает перегрузку медленных клиентов при резких всплесках трафика. Система легко масштабируется горизонтально путем добавления новых серверов в кластер.
- Kafka хранит данные в виде упорядоченной последовательности записей.
- Сообщения в топиках не удаляются сразу после прочтения клиентом.
- Высокая производительность достигается за счет линейной записи на диск.
- Поддержка нескольких подписчиков на один и тот же поток данных.
Apache Kafka предоставляет разработчикам гарантии порядка сообщений внутри одной партиции. Это критически важно для финансовых систем и обработки транзакций в реальном времени.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
5 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Ключевые аспекты и архитектура Apache Kafka
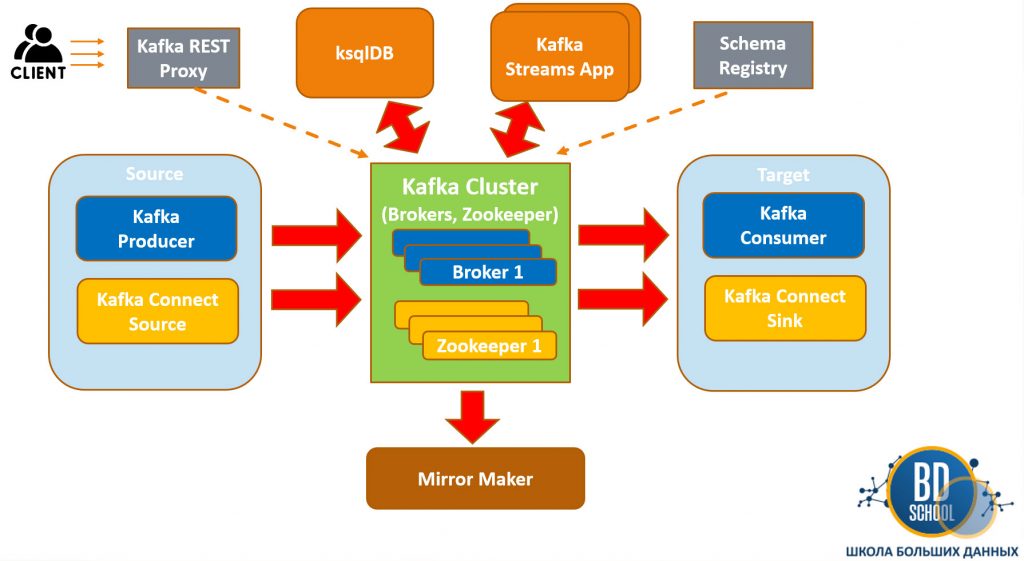
Архитектура системы строится вокруг концепции распределенного кластера из нескольких узлов. Каждый такой узел называется брокером и отвечает за хранение части данных. Клиентские приложения взаимодействуют с кластером через стандартизированный протокол обмена данными. Разделение ответственности позволяет системе работать без простоев даже при выходе серверов из строя. Архитектура Kafka включает несколько основных компонентов. Все они работают вместе для обеспечения её функциональности.
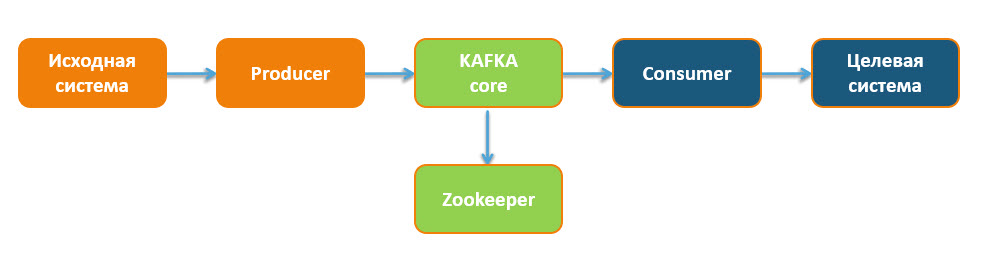
Брокеры, Топики и Партиции
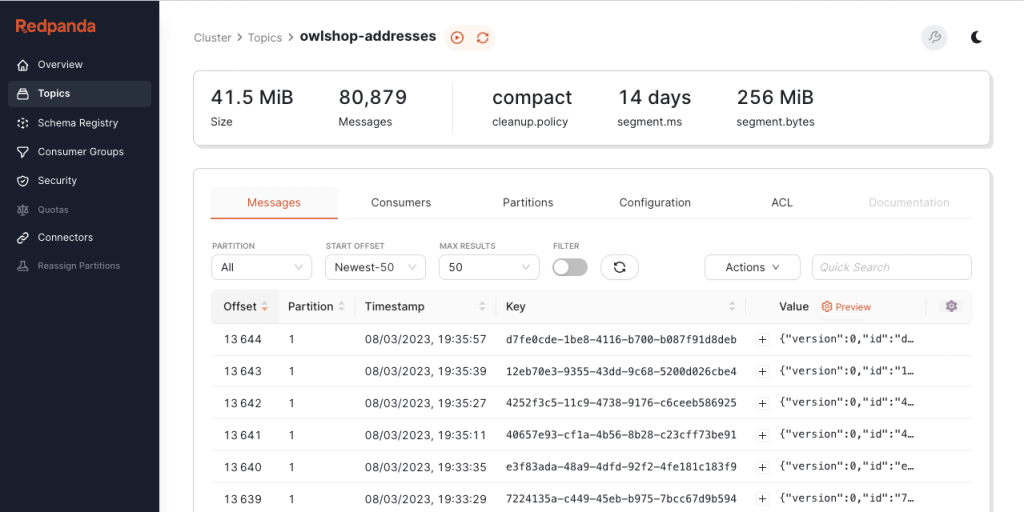
Данные в системе организуются в логические категории, которые называются топиками. Каждый топик физически разделяется на несколько более мелких частей — партиций. Партиция представляет собой упорядоченный лог, в который данные только дописываются в конец. Именно разбиение на партиции позволяет распределять нагрузку между разными брокерами кластера.
- Партиции позволяют параллельно считывать данные из одного большого топика.
- Каждая запись в партиции получает свой уникальный номер (offset).
- Количество партиций напрямую влияет на максимальную пропускную способность системы.
- Брокеры равномерно распределяют партиции по дисковым подсистемам серверов.
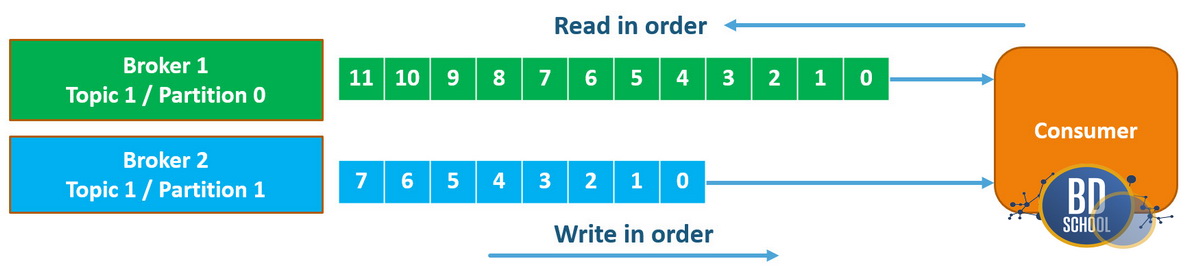
Разделение данных на партиции является ключом к горизонтальному масштабированию всей платформы.
Продюсеры и Консьюмеры
Продюсеры (Producers) — это приложения, которые отправляют данные в топики кластера. Они могут выбирать, в какую именно партицию направить конкретное сообщение. Обычно это делается на основе ключа сообщения с помощью специального алгоритма хеширования. Консьюмеры (Consumers) считывают данные и обрабатывают их согласно бизнес-логике приложения.
- Продюсеры могут работать в асинхронном режиме для повышения скорости.
- Консьюмеры объединяются в группы для совместной обработки одного топика.
- Система автоматически балансирует нагрузку между участниками одной группы потребителей.
Такое разделение позволяет независимо масштабировать генерацию и потребление потоков данных.
Consumer Groups и Offset
Механизм групп потребителей позволяет эффективно распределять чтение данных между несколькими экземплярами приложения. Каждая партиция внутри группы закрепляется только за одним конкретным потребителем. Это гарантирует, что одно сообщение не будет обработано дважды разными участниками группы. Offset (смещение) — это позиция последнего прочитанного сообщения в каждой отдельной партиции.
- Kafka хранит информацию о смещениях в специальном системном топике.
- При перезагрузке потребитель продолжает чтение с последнего зафиксированного места.
- Группы позволяют легко реализовать как модель очереди, так и модель публикации-подписки.
Правильное управление смещениями обеспечивает гарантию доставки сообщений «как минимум один раз».
Как Kafka обеспечивает надежность и скорость
Скорость работы платформы часто вызывает удивление у инженеров, привыкших к медленным БД. Секрет кроется в использовании последовательного ввода-вывода и системного кэша операционной системы. Вместо случайного доступа к данным, Kafka просто дописывает байты в конец файлов. Современные жесткие диски показывают отличные результаты при такой линейной нагрузке на шпиндель.
Репликация и ISR (In-Sync Replicas)
Надежность хранения данных достигается путем создания копий партиций на разных брокерах. Одна реплика назначается лидером, а остальные становятся ведомыми последователями (followers). Все операции записи и чтения проходят исключительно через лидера для обеспечения согласованности. Ведомые брокеры просто копируют данные к себе в фоновом режиме.
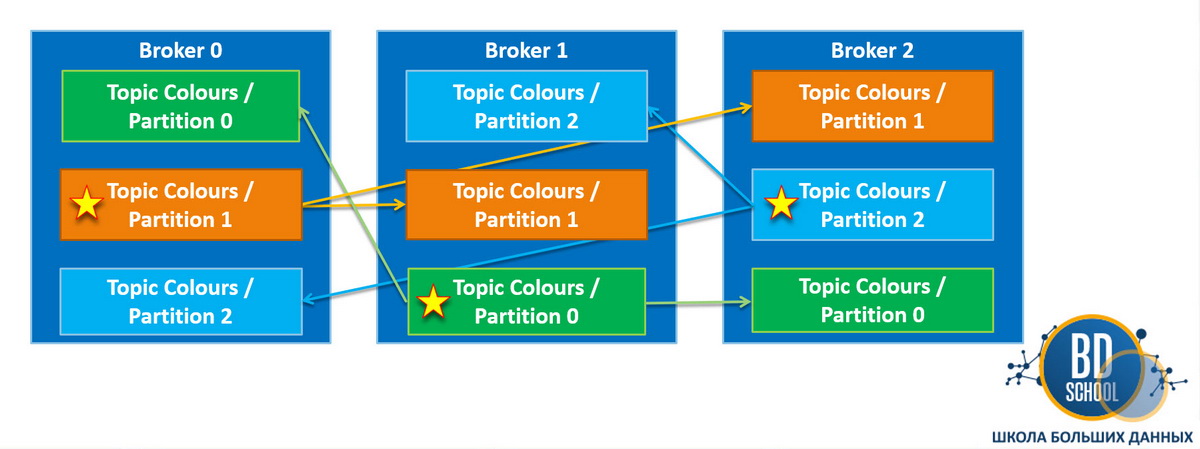
- Список синхронных реплик (ISR) содержит узлы, которые полностью догнали лидера.
- При падении лидера новым главным узлом становится один из участников ISR.
- Параметр acks в настройках продюсера определяет степень подтверждения записи.
Репликация позволяет системе выживать даже при потере нескольких физических серверов одновременно.
Zero-copy и Sequential I/O
Для передачи данных по сети Kafka использует технологию zero-copy. Это позволяет передавать данные из дискового кэша напрямую в сетевой сокет. Процессор при этом не тратит циклы на копирование байтов в пользовательское пространство. Данная оптимизация радикально снижает нагрузку на CPU и увеличивает общую пропускную способность.
- Данные передаются в том же формате, в котором лежат на диске.
- Отсутствие десериализации на стороне брокера экономит ценные ресурсы системы.
- Операционная система эффективно кэширует горячие данные в оперативной памяти.
Благодаря этим техникам Kafka способна обрабатывать миллионы сообщений в секунду
Паттерны проектирования топиков и ключей
Выбор ключа сообщения определяет, в какую партицию попадут ваши данные. Если вы используете null в качестве ключа, сообщения распределяются по кругу (Round Robin). Однако для многих задач критически важно сохранять порядок связанных событий. Например, все транзакции одного пользователя должны обрабатываться в строгой последовательности.
- Сообщения с одинаковым ключом всегда попадают в одну и ту же партицию.
- Плохой выбор ключа может привести к перекосу данных (Data Skew).
- Некоторые партиции могут стать слишком тяжелыми и замедлить работу кластера.
Проектирование схемы данных требует понимания того, как консьюмеры будут группировать информацию.
Admin API
Для управления объектами кластера, такими как топики, брокеры и конфигурации, используется Admin API. Этот API предоставляет программный доступ к административным функциям. Он позволяет автоматизировать операции развертывания и мониторинга. Это делает управление кластером более эффективным.
ZooKeeper и KRAFT
Традиционно, Apache ZooKeeper использовался для хранения метаданных кластера Kafka. Он отвечал за управление брокерами, топиками и группами потребителей. Однако, начиная с версии Kafka 2.8, и особенно с полной реализацией в версии 4.0, платформа переходит на новый режим консенсуса — KRAFT (Kafka Raft Metadata). KRAFT полностью устраняет зависимость от ZooKeeper. Это упрощает архитектуру и развертывание кластера. Такая миграция делает управление более простым и производительным. Режим KRAFT встроен непосредственно в брокеры Kafka.
Apache Kafka: администрирование кластера
Код курса
KAFKA
Ближайшая дата курса
5 октября, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Сценарии использования Apache Kafka в реальных проектах
Одним из самых популярных сценариев является агрегация технических логов из тысяч сервисов. Вместо записи в локальные файлы, приложения отправляют события напрямую в централизованный кластер. Это позволяет анализировать ошибки и производительность системы в режиме реального времени. Команда эксплуатации может быстро реагировать на инциденты еще до жалоб пользователей.
Другой важный кейс — архитектура Event Sourcing. Здесь Kafka выступает в роли единственного источника истины для всех микросервисов. Каждое изменение состояния системы записывается как событие в неизменяемый лог. Любой сервис может воссоздать свою базу данных, просто перечитав историю событий с самого начала.
Развертывание Apache Kafka 4.2.0 в режиме KRaft на Ubuntu
Для работы Kafka требуется среда исполнения Java. Мы будем использовать OpenJDK 17 или 21, которые обеспечивают отличную стабильность и производительность. Все действия выполняются в консоли сервера.
Подготовка системы и установка
Первым делом обновите индексы пакетов и установите Java. После этого скачайте дистрибутив с официального зеркала Apache мы будем использовать последнюю доступную нам сейчас версию Kafka KRAFT 4.2.0 .
#--- Установите Java sudo apt install default-jdk -y #--- Скачайте архив wget https://dlcdn.apache.org/kafka/4.2.0/kafka_2.13-4.2.0.tgz #--- Распакуйте его tar -xzf kafka_2.13-4.2.0.tgz #--- Перейдите в рабочую директорию cd kafka_2.13-4.2.0
Установка в домашнюю директорию удобна для тестов. Для продакшн-среды рекомендуется перенести файлы в /opt/kafka.
Конфигурация KRaft для Kafka кластера
В режиме KRaft один из брокеров берет на себя роль контроллера. В одноюнитовой (single-node) конфигурации наш сервер будет совмещать роли брокера и контроллера. Нам нужно сгенерировать уникальный идентификатор кластера и отформатировать хранилище.
#--- Генерация UUID - Скопируйте полученную строку. bin/kafka-storage.sh random-uuid #--- Форматирование логов bin/kafka-storage.sh format -t xIX_NIddScSTq7AjG3mmVQ -c config/server.properties --standalone #--- Запуск сервера в режиме Демона ( страшно ) bin/kafka-server-start.sh -daemon config/server.properties #--- Создаем свой первый Топик на кластере Apache Kafka в KRAFT режиме bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic BigDataSchool #--- Подключаемся к топику Продюсером и продюсируем в него то есть пишем в него сообщения bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic BigDataSchool #--- Выичтываем данные из топика Консьюмером ( не забудьте ключ --from-beginning) bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic BigDataSchool --from-beginning
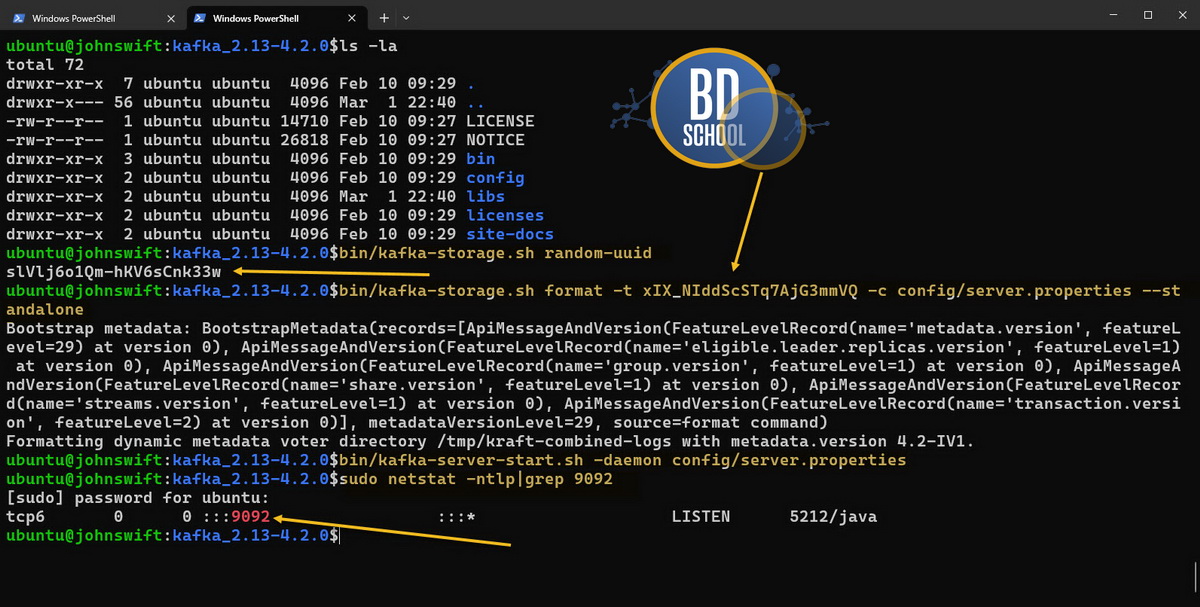
Флаг — daemon запустит процесс в фоновом режиме. Теперь ваша Kafka готова к приему сообщений.
Базовые команды для работы с данными
Все стандартные утилиты Kafka находятся в директории bin. Для локальной работы мы будем использовать адрес брокера localhost:9092.
Создание топика
Топик — это логическое хранилище ваших сообщений. При создании важно указать количество партиций и фактор репликации. Для одного узла репликация всегда равна единице.

Отправка сообщений (Продюсер)
Консольный продюсер позволяет отправлять текстовые строки в топик в интерактивном режиме. Каждая новая строка после нажатия Enter станет отдельным сообщением.
После запуска введите текст, например: Привет ты молодец!!! . Для выхода используйте Ctrl+C.
Чтение сообщений (Консьюмер)
Чтобы увидеть данные, которые вы только что отправили, нужно запустить консольный потребитель. Флаг —from-beginning заставит Kafka отдать все сообщения с самого начала истории топика.

Эти команды являются фундаментом для любого администратора или разработчика Big Data. Они позволяют быстро проверить доступность кластера и корректность прохождения данных.
Не отчаивайся если получилось не все — в Школе Больших Данных у нас есть для тебя целый курс по KAFKA:»Администрированию Apache Kafka кластера» — приходи не пожалеешь! А если ты разработчик то еще DEVKI:»Apache Kafka для develeopers»
Apache Kafka для инженеров данных
Код курса
DEVKI
Ближайшая дата курса
24 августа, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Экосистема за пределами ядра (Connect и Streams)
Сегодня Apache Kafka — это не просто брокер, а полноценная экосистема инструментов. Фреймворк Kafka Connect позволяет подключать внешние базы данных без написания кода. Вы можете настроить автоматическую выгрузку данных из PostgreSQL прямо в топики Kafka. Существуют сотни готовых коннекторов для облачных хранилищ и поисковых движков вроде Elasticsearch.
Kafka Streams — это библиотека для построения приложений потоковой обработки данных на Java. Она позволяет выполнять агрегацию, фильтрацию и объединение потоков внутри вашего приложения. Для тех, кто предпочитает декларативный подход, существует ksqlDB. Этот инструмент дает возможность писать SQL-запросы прямо к потокам событий в реальном времени.
- Connect упрощает интеграцию с Legacy-системами и внешними API.
- Streams обеспечивает отказоустойчивую обработку состояний (stateful processing).
- ksqlDB превращает поток событий в динамически обновляемые таблицы.
Использование этих инструментов сокращает время вывода новых аналитических продуктов на рынок.
Основные дистрибутивы и расширения Apache Kafka
Хотя Kafka является проектом с открытым исходным кодом, существует несколько коммерческих дистрибутивов и платформ, которые добавляют дополнительные функции, инструменты управления и поддержку. Эти дистрибутивы значительно упрощают развертывание и эксплуатацию Kafka в производственной среде.
- Confluent Platform: Это одна из самых популярных коммерческих платформ. Confluent Platform предоставляет расширенные возможности. Среди них — Confluent Schema Registry, Confluent Control Center. Она также включает ksqlDB и дополнительные коннекторы. Confluent предлагает полную экосистему вокруг Kafka.
- Arenadata Streaming (ADS): Российский дистрибутив Kafka. Arenadata Streaming предоставляет корпоративную поддержку. Он включает дополнительные инструменты для управления и мониторинга. ADS ориентирован на использование в российских IT-инфраструктурах.
Основные конкуренты Apache Kafka
На рынке потоковой обработки данных у Kafka есть несколько ключевых конкурентов. Каждый из них имеет свои сильные стороны. Выбор зависит от конкретных требований проекта.
- RabbitMQ: Это популярный брокер сообщений. RabbitMQ использует протокол AMQP. Он часто применяется для обмена сообщениями между микросервисами. Однако RabbitMQ лучше подходит для очередей сообщений. Он менее масштабируем для потоковой передачи больших объемов данных.
- Apache Pulsar: Еще одна распределенная потоковая платформа. Apache Pulsar поддерживает как очереди, так и потоки. Он имеет многоуровневую архитектуру хранения. Pulsar предлагает гибкую масштабируемость. Он является серьезным конкурентом в области потоковых данных.
- Amazon Kinesis: Управляемый сервис потоковой передачи данных от AWS. Amazon Kinesis предоставляет возможности для сбора, обработки и анализа потоковых данных. Он полностью интегрирован с другими сервисами AWS. Однако Kinesis является проприетарным решением.
Заключение
Apache Kafka коренным образом изменила подход к проектированию распределенных систем. Она объединяет в себе надежность дискового хранилища и скорость обмена сообщениями. Понимание принципов работы партиций и групп потребителей открывает двери к созданию высоконагруженных приложений. Начните внедрение с простых задач по сбору метрик, и вы быстро оцените мощь этой платформы.
Референсные ссылки:
- Official Apache Kafka Documentation (2025)
- Confluent Blog: Kafka Architecture Fundamentals (2025)
- Apache Kafka KRaft Mode Guide (2025)