 376
376 
Содержание
- Архитектура Jupyter Notebook - Как это работает под капотом
- Установка и настройка Jupyter notebook среды
- Anaconda vs Pip
- Управление ядрами (Kernels)
- Интерфейс и базовые концепции Jupyter Notebook
- Типы ячеек
- Горячие клавиши (Shortcuts)
- Магические команды (Magic Commands) Jupyter Notebook
- Jupyter Notebook в роли Data Engineering инструмента
- SQL-магия. Полный цикл (от создания до DataFrame)
- Apache Spark (PySpark) - локальная ETL-задача
- Apache Airflow и Papermill - параметризация
- Интерактивная визуализация и виджеты для Jupyter Notebook
- Экосистема и эволюция
- «Темная сторона» и Best Practices
- Заключение
- Референсные ссылки
Jupyter Notebook — это интерактивная веб-среда разработки, которая позволяет объединить исполняемый код, наглядные визуализации и форматированный текст в одном документе. Это стандарт де-факто для Data Science, машинного обучения и, с недавних пор, дата-инжиниринга.
Название проекта — это игра слов. С одной стороны, это отсылка к трем основным языкам программирования, которые поддерживались изначально: Julia, Python и R. С другой стороны, это дань уважения записям Галилео Галилея, открывшего луны Юпитера.
Главная фишка Jupyter — это концепция REPL (Read-Eval-Print Loop) на стероидах. Вы пишете кусочек кода, запускаете его и сразу видите результат. Вам не нужно компилировать весь проект, чтобы проверить гипотезу или посмотреть на график. Это делает его идеальным инструментом для исследований, прототипирования и обучения.
Архитектура Jupyter Notebook — Как это работает под капотом
Многие новички воспринимают Jupyter как просто «сайт, где можно писать код». На самом деле это сложное приложение с клиент-серверной архитектурой. Понимание этого устройства спасает от множества ошибок при настройке окружения.
Система состоит из трех ключевых компонентов:
- Frontend (Веб-интерфейс): То, что вы видите в браузере. Это JavaScript-приложение, которое отправляет ваш код на сервер и отрисовывает полученные результаты (текст, графики, ошибки).
- Notebook Server: Прослойка на вашем компьютере (или в облаке). Он отвечает за сохранение файлов .ipynb и маршрутизацию команд от браузера к ядру.
- Kernel (Ядро): «Мозг» системы. Это процесс, который реально выполняет ваш код. Для Python это обычно пакет ipykernel.
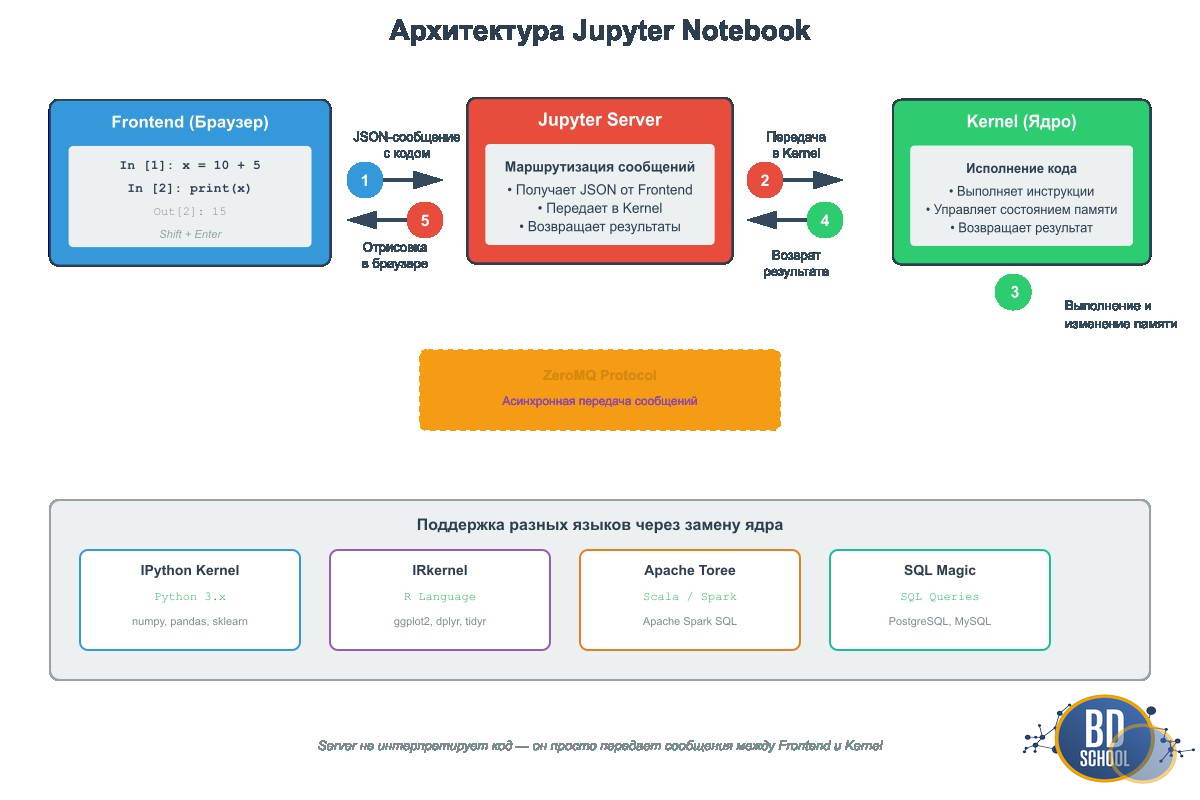
Связь между этими компонентами выглядит следующим образом:
- Вы нажимаете Shift + Enter в браузере.
- Frontend упаковывает код в JSON-сообщение.
- Server пересылает это сообщение в активное Ядро через протокол ZeroMQ.
- Ядро исполняет код, меняет состояние памяти и возвращает результат.
- Server отдает результат браузеру для отрисовки.
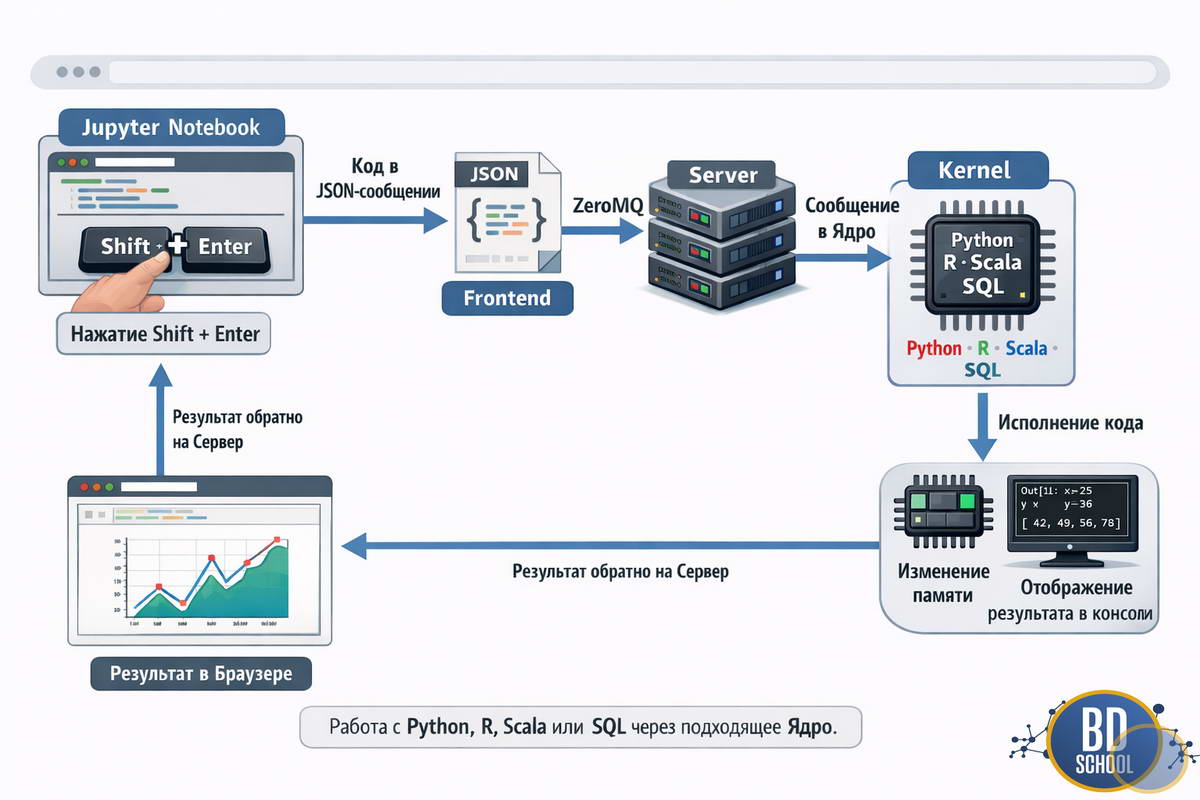
Эта схема объясняет, почему Jupyter может работать с Python, R, Scala или SQL. Серверу все равно, какой код передавать. Ему нужно лишь соответствующее ядро, умеющее этот код интерпретировать.
Файл .ipynb
Ваш ноутбук сохраняется в файл с расширением .ipynb. Это не скрипт, а обычный текстовый файл в формате JSON. Внутри него хранится не только код, но и метаданные, порядок ячеек и даже закодированные в base64 картинки графиков.
Важно: Никогда не пытайтесь редактировать .ipynb как обычный текст в блокноте. Вы сломаете структуру JSON, и ноутбук перестанет открываться.
Установка и настройка Jupyter notebook среды
Для начала работы у вас есть два основных пути. Выбор зависит от вашего опыта и задач.
Anaconda vs Pip
- Anaconda: Идеально для старта. Это дистрибутив, который включает Python, Jupyter и сотни популярных библиотек (Pandas, NumPy). Вы просто ставите одну программу и забываете о проблемах совместимости.
- Pip: Путь джедая. Вы ставите чистый Python и устанавливаете Jupyter командой pip3 install notebook. Это дает больше контроля и экономит место на диске.
Управление ядрами (Kernels)
Одна из самых частых болей — работа с виртуальными окружениями. Представьте ситуацию: вы создали новое окружение venv, установили туда библиотеку tensorflow, запускаете Jupyter, а он не видит эту библиотеку. Причина в том, что Jupyter по умолчанию использует системный Python. Чтобы научить его видеть ваше виртуальное окружение, нужно зарегистрировать его как новое ядро.
Алгоритм действий:
- Активируйте окружение.
- Установите пакет ядра: pip3 install ipykernel.
Зарегистрируйте его:
python -m ipykernel install --user --name=my_env_name
Теперь в меню «Kernel» -> «Change kernel» появится ваш my_env_name.
Важно для пользователей Docker и удаленных серверов: Команда регистрации ядра сохраняет конфигурацию локально. Если вы запускаете Jupyter внутри Docker-контейнера, он не увидит ядра, установленные на вашей основной машине, так как файловые системы изолированы. Для решения — Устанавливайте библиотеки и регистрируйте ядра (ipykernel) в той же среде, где запущен сам Jupyter Server (внутри контейнера).
Интерфейс и базовые концепции Jupyter Notebook
Интерфейс ноутбука минималистичен, но в нем есть неочевидная логика, которую нужно освоить сразу. Это модальная система редактирования, похожая на редактор Vim. Jupyter всегда находится в одном из двух режимов работы (состояний):
- Command Mode (Синяя рамка): Навигация. Вы не можете печатать код, но можете управлять ячейками. Вход по клавише Esc. В этом режиме работают горячие клавиши для удаления, копирования и перемещения ячеек.
- Edit Mode (Зеленая рамка): Редактирование. Вы печатаете код внутри ячейки. Вход по клавише Enter или клику мыши в поле ввода.
Типы ячеек
Документ состоит из блоков, называемых ячейками (Cells). Основных типов три:
- Code: Здесь живет Python (или SQL/Spark) код. Слева есть индикатор In [ ]. Если там звездочка In [*], значит ядро занято вычислениями.
- Markdown: Текст с форматированием. Поддерживает заголовки, списки, ссылки и даже формулы LaTeX. Это позволяет превратить сухой код в полноценный отчет или статью.
- Raw NBConvert: Сырой текст, который игнорируется при запуске, но используется при конвертации ноутбука в другие форматы (например, в PDF или HTML).
Горячие клавиши (Shortcuts)
Мышь в Jupyter — враг производительности. Запомните эти комбинации, и вы ускоритесь в разы:
- Shift + Enter: Запустить ячейку и перейти к следующей.
- Ctrl + Enter: Запустить ячейку и остаться в ней.
- A / B: Вставить новую ячейку выше (Above) или ниже (Below) текущей (работает в Command Mode).
- D, D (дважды): Удалить ячейку.
- M: Превратить ячейку в Markdown.
- Y: Превратить ячейку обратно в Code.
Магические команды (Magic Commands) Jupyter Notebook
Jupyter обладает встроенным языком команд, расширяющим возможности Python. Эти команды начинаются со знака процента %.
Существует два типа магии:
- Line magic (%): Действует только на одну строку.
- Cell magic (%%): Действует на все содержимое ячейки. Команда %% должна быть строго первой строкой в ячейке.
Вот самые полезные команды для повседневной работы:
- %timeit: Измеряет время выполнения кода. Она запускает код несколько раз (циклов) и выдает среднее время и стандартное отклонение. Незаменимо для оптимизации функций.
- %who: Показывает список всех переменных, созданных в памяти ноутбука.
- %history: Выводит историю всех введенных команд.
- %%writefile filename.py: Записывает содержимое ячейки в файл на диске. Удобно для создания модулей прямо из ноутбука.
- %%bash: Позволяет писать скрипты на Bash (Linux) внутри ячейки. Работает с git, установкой пакетов и файловой системой.
Пример использования магии для замера производительности списка:
%%timeit my_list = [x**2 for x in range(1000)]

Результат покажет точное время выполнения операции в микросекундах. Это позволяет сравнивать разные подходы к решению задачи объективно, а не «на глаз».
Jupyter Notebook в роли Data Engineering инструмента
Изначально созданный для аналитиков, Jupyter плотно вошел в арсенал дата-инженеров. Он служит точкой входа для работы с базами данных, кластерами Big Data и оркестраторами.
SQL-магия. Полный цикл (от создания до DataFrame)
Вам не нужно переключаться в DBeaver или pgAdmin, чтобы проверить данные. С помощью расширения ipython-sql вы можете писать SQL-запросы прямо в ячейках. Для этого примера мы не будем требовать наличие PostgreSQL, хотя можно подключиться к любой внешней базе допустим postgres:
#-- подключение к внешней postgresql БД пример %load_ext sql %sql postgresql://user:password@localhost/my_db
Мы используем встроенную базу данных SQLite, которая создается прямо в оперативной памяти.
#--- устанавливаем необходимые библиотеки !pip3 install ipython-sql sqlalchemy psycopg2 pandas
Сценарий: Создаем временную таблицу продаж, наполняем её данными и выгружаем аналитику сразу в Pandas.
# Ячейка 1: Загрузка расширения
%load_ext sql
# Ячейка 2: Подключение к базе данных в памяти (SQLite)
# Это создаст временную БД прямо внутри ноутбука
%sql sqlite://
# Ячейка 3: DDL - Создание таблицы и наполнение демо-данными
%%sql
DROP TABLE IF EXISTS sales;
CREATE TABLE sales (
id INTEGER PRIMARY KEY,
category VARCHAR(50),
amount DECIMAL(10, 2),
sale_date DATE
);
INSERT INTO sales (category, amount, sale_date) VALUES
('Electronics', 1200.50, '2023-10-01'),
('Books', 45.00, '2023-10-02'),
('Electronics', 800.00, '2023-10-02'),
('Clothing', 150.00, '2023-10-03'),
('Books', 20.00, '2023-10-03');
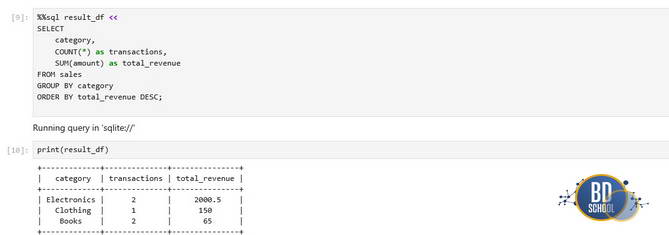
# Ячейка 4: Аналитический запрос с сохранением в Python-переменную
# Обратите внимание на 'result_df <<' — это оператор присваивания
%%sql result_df <<
SELECT
category,
COUNT(*) as transactions,
SUM(amount) as total_revenue
FROM sales
GROUP BY category
ORDER BY total_revenue DESC;
Теперь можно писать нативные SQL-запросы. Главная сила в том, что результат запроса можно сразу сохранить в переменную Python или DataFrame библиотеки Pandas:
# Ячейка 5: Работа с результатом как с обычным Pandas DataFrame
import matplotlib.pyplot as plt
print(f"Тип объекта: {type(result_df)}")
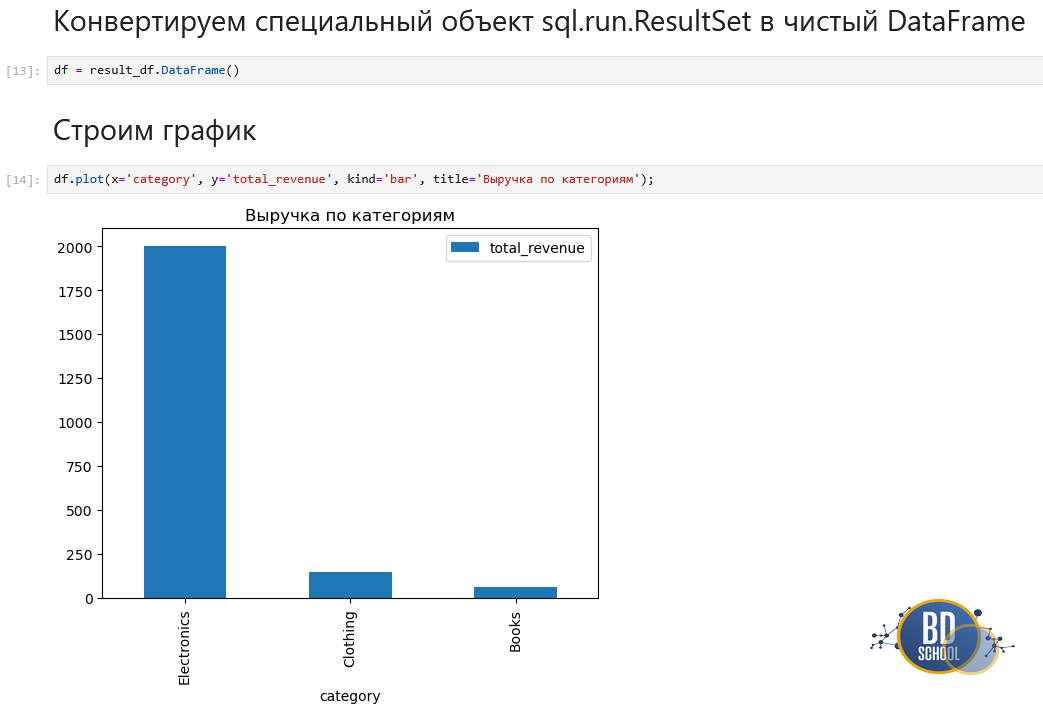
# Конвертируем специальный объект sql.run.ResultSet в чистый DataFrame
df = result_df.DataFrame()
# Строим график
df.plot(x='category', y='total_revenue', kind='bar', title='Выручка по категориям');
Переменная result_df теперь доступна для анализа методами Python. Это создает бесшовный поток данных: забрали SQL-ем -> обработали Pandas -> обучили модель Scikit-learn.
Apache Spark (PySpark) — локальная ETL-задача
Вместо подключения к удаленному кластеру (что сложно для демо), мы поднимем локальную сессию Spark. Это стандартная практика для отладки кода перед деплоем.
Предварительные требования:
#---Java должна быть установлена в системе pip3 install pyspark findspark
Для работы с Big Data Jupyter выступает как интерфейс драйвера Spark. Код пишется в ноутбуке, но выполняется на мощном кластере. Обычно используется библиотека findspark для инициализации:

# Ячейка 1: Инициализация
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, avg, desc
# Создаем "карманный" Spark кластер
spark = SparkSession.builder \
.appName("Jupyter_Local_ETL") \
.master("local[*]") \
.getOrCreate()
print("Spark UI доступен (обычно на localhost:4040)")
# Ячейка 2: Генерация демо-данных
# В реальности здесь был бы spark.read.parquet("s3://bucket/...")
data = [
("Alice", "Engineering", 85000),
("Bob", "Marketing", 60000),
("Charlie", "Engineering", 90000),
("David", "Marketing", 65000),
("Eve", "HR", 50000)
]
columns = ["Name", "Department", "Salary"]
# Создание Spark DataFrame
df_spark = spark.createDataFrame(data, columns)
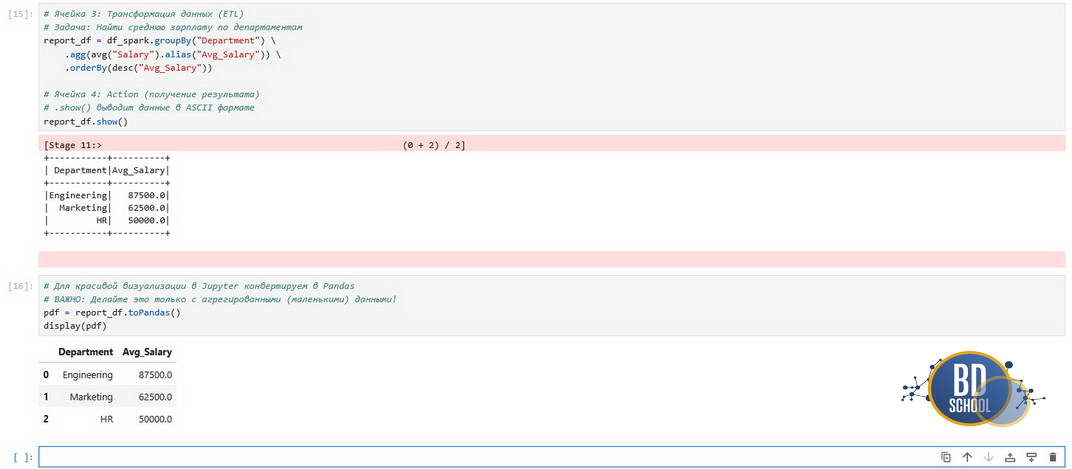
# Ячейка 3: Трансформация данных (ETL)
# Задача: Найти среднюю зарплату по департаментам
report_df = df_spark.groupBy("Department") \
.agg(avg("Salary").alias("Avg_Salary")) \
.orderBy(desc("Avg_Salary"))
# Ячейка 4: Action (получение результата)
# .show() выводит данные в ASCII формате
report_df.show()
# Для красивой визуализации в Jupyter конвертируем в Pandas
# ВАЖНО: Делайте это только с агрегированными (маленькими) данными!
pdf = report_df.toPandas()
display(pdf)
В ноутбуке удобно работать с Spark DataFrames. Из-за ленивой природы Spark (Lazy Evaluation) вычисления не запускаются, пока вы не вызовете действие (Action), например .show() или .count().
Jupyter позволяет итеративно строить сложные пайплайны обработки данных. Вы пишете трансформацию, делаете .limit(5).toPandas(), смотрите на образец данных, и если все ок — запускаете расчет на всем петабайте данных.
Apache Airflow и Papermill — параметризация
Классическая проблема — аналитик написал ноутбук с отличной моделью, а инженеру нужно запускать этот код каждую ночь по расписанию. Копировать код в Python-скрипты долго и чревато ошибками. Здесь на помощь приходит библиотека Papermill и оркестратор Apache Airflow.
Суть подхода:
- В ноутбуке одна из ячеек помечается тегом parameters.
- В Airflow используется PapermillOperator.
- Airflow берет ноутбук-шаблон, подставляет нужные параметры (например, date=’2023-10-25‘) и запускает его.
- Результат сохраняется как новый ноутбук-отчет.
Это позволяет использовать .ipynb файлы как полноценные задачи (Tasks) в ETL-процессах, сохраняя при этом красивые графики и отчеты о выполнении для истории.
Здесь демо состоит из двух частей: подготовки ноутбука и кода DAG’а для Airflow.
Часть А: Подготовка Ноутбука (daily_report.ipynb)
- Создайте ноутбук.
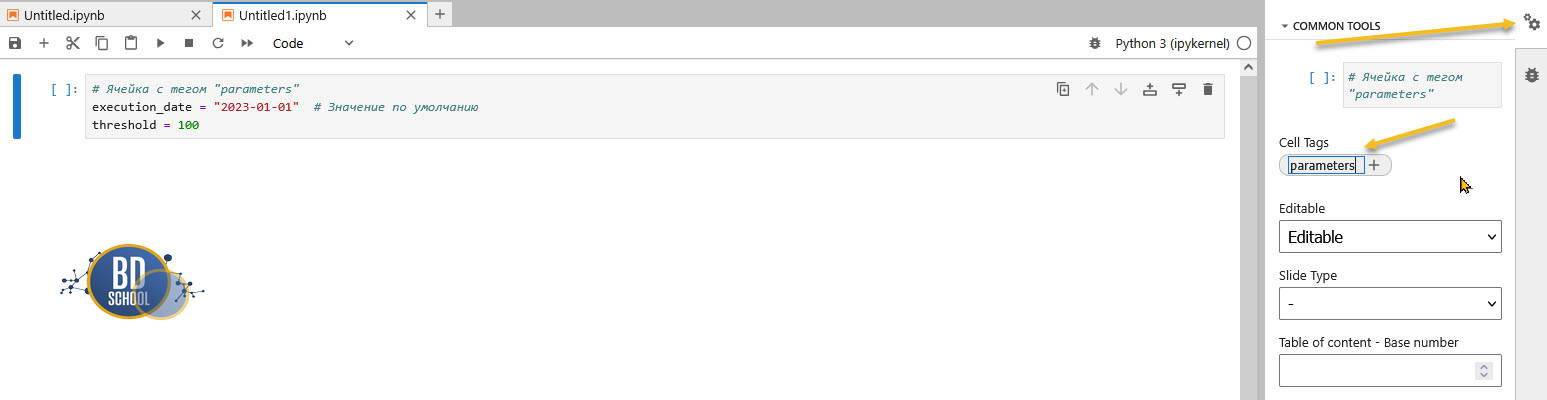
- В первой ячейке напишите параметры по умолчанию.
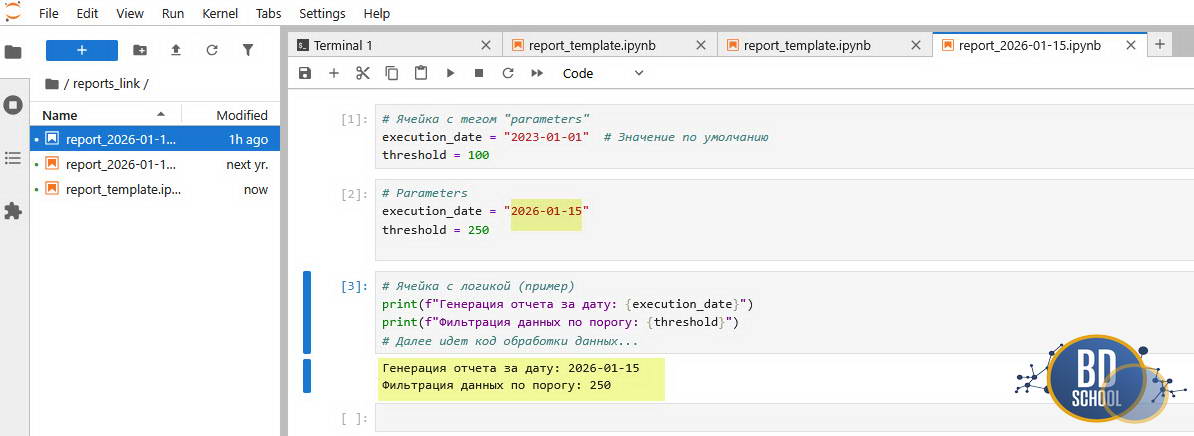
- Критически важно: В меню Jupyter Notebook выберите Common Tools -> Cell tags -> Add Tags. Добавьте тег parameters к этой ячейке. Papermill ищет именно этот тег, чтобы заменить значения.
# Ячейка с тегом "parameters" execution_date = "2023-01-01" # Значение по умолчанию threshold = 100
# Ячейка с логикой (пример)
print(f"Генерация отчета за дату: {execution_date}")
print(f"Фильтрация данных по порогу: {threshold}")
# Далее идет код обработки данных...
Часть Б: Код DAG для Airflow (файл .py)
Мы подробно и просто описали процесс запуска docker контайнера с Apache Airflow под WSL здесь
Этот код помещается в папку dags вашего Airflow сервера. Он берет ноутбук-шаблон, подставляет дату запуска (из Airflow) и сохраняет результат в новый файл.
from airflow import DAG
from airflow.providers.papermill.operators.papermill import PapermillOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'data_engineer',
'start_date': days_ago(1),
}
with DAG(
dag_id='jupyter_automated_report',
default_args=default_args,
schedule_interval='@daily',
catchup=False
) as dag:
run_notebook_task = PapermillOperator(
task_id='run_daily_report',
# Исходный шаблон ноутбука
input_nb='/opt/airflow/dags/notebooks/daily_report.ipynb',
# Куда сохранить исполненный ноутбук (с графиками и логами)
output_nb='/opt/airflow/output/report_{{ ds }}.ipynb',
# Параметры для инъекции (словарь)
# {{ ds }} — это макрос Airflow (дата запуска YYYY-MM-DD)
parameters={
'execution_date': '{{ ds }}',
'threshold': 250
}
)
Что происходит в итоге?
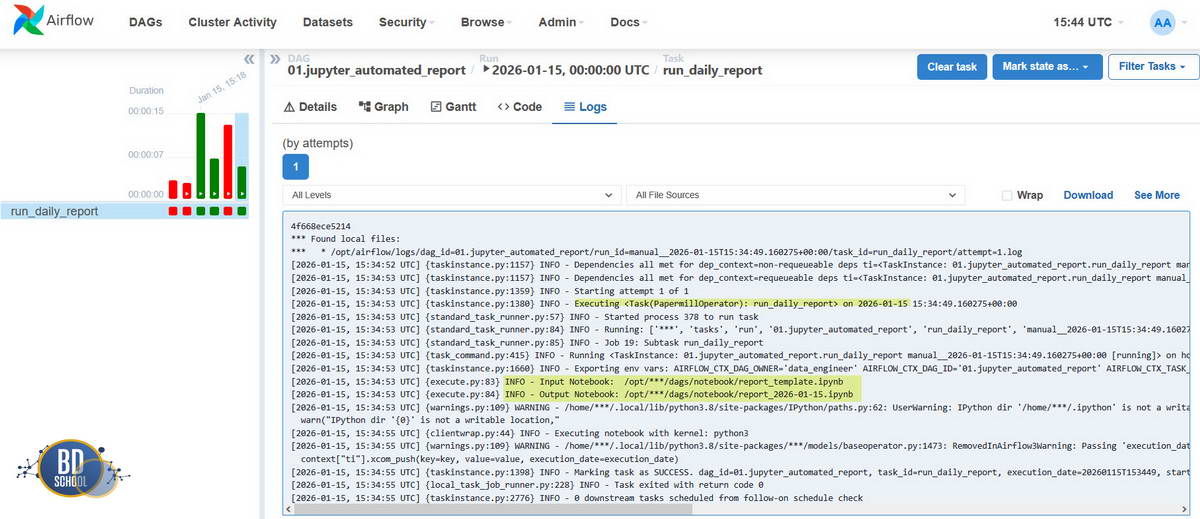
Каждый день Airflow создает файл вида report_2023-10-25.ipynb.
Если job упал, инженер не лезет в логи сервера, а просто открывает этот ноутбук и видит, на какой ячейке произошла ошибка и как выглядели данные в тот момент. Это радикально ускоряет отладку.
Это позволяет использовать .ipynb файлы как полноценные задачи (Tasks) в ETL-процессах, сохраняя при этом красивые графики и отчеты о выполнении для истории.
Интерактивная визуализация и виджеты для Jupyter Notebook
Одна из суперсил Jupyter — возможность видеть данные. Стандартная команда %matplotlib inline позволяет отрисовывать статические графики прямо под ячейкой с кодом. Но можно пойти дальше и превратить ноутбук в интерактивное приложение с помощью библиотеки ipywidgets. Вы можете добавить слайдеры, выпадающие списки и кнопки, которые меняют параметры кода без его переписывания.
Пример простой интерактивности:
from ipywidgets import interact
def square(x):
return x * x
interact(square, x=(0, 100));
Этот код создаст ползунок от 0 до 100. При перетаскивании ползунка функция square будет автоматически пересчитываться, и вы увидите новый результат мгновенно. Это незаменимо при подборе гиперпараметров модели или исследовании чувствительности алгоритма.

Экосистема и эволюция
Jupyter Notebook — это «классика», но экосистема продолжает развиваться. Важно знать о современных альтернативах и расширениях.
JupyterLab
Это следующее поколение интерфейса. Если Notebook — это страница с кодом, то JupyterLab — это полноценная IDE в браузере. Она поддерживает вкладки, позволяет открывать несколько ноутбуков рядом, имеет встроенный файловый менеджер, просмотрщик CSV и терминал. Переход на Lab практически безболезненный, так как формат файлов остается тем же.
Облачные решения
Не у всех есть мощные видеокарты для обучения нейросетей. Облачные сервисы решили эту проблему:
- Google Colab: Бесплатный Jupyter в облаке от Google с доступом к GPU (Tesla T4) и TPU. Интегрирован с Google Drive.
- Kaggle Kernels: Среда для соревнований по Data Science с огромным набором предустановленных датасетов.
JupyterHub
Когда в компании работает команда дата-сайентистов, устанавливать Jupyter каждому на ноутбук неудобно и небезопасно. JupyterHub — это многопользовательский сервер. Он позволяет запускать экземпляры Jupyter для каждого сотрудника на едином мощном сервере компании, управляя авторизацией и ресурсами централизованно.
«Темная сторона» и Best Practices
При всей любви к Jupyter notebook, у него есть недостатки, которые могут превратить разработку в хаос. Опытного специалиста отличает знание того, как эти риски минимизировать.
Проблема скрытого состояния (Hidden State)
В Jupyter вы можете запускать ячейки в любом порядке: сначала первую, потом десятую, потом снова вторую. Это создает состояние памяти, которое невозможно воспроизвести, если просто запустить ноутбук сверху вниз.
Решение: Перед отправкой работы коллегам или сохранением финальной версии всегда делайте: Kernel -> Restart & Run All. Если код упал с ошибкой — значит, ваш результат был случайностью, а не закономерностью.
Ад контроля версий (Git)
Так как .ipynb — это JSON с кучей метаданных и бинарными кодами картинок, Git очень плохо отслеживает изменения. Изменение одной строки кода может вызвать 500 строк изменений в файле из-за сдвига метаданных или перерисовки графика.
Решение: Используйте инструмент Jupytext. Он позволяет автоматически сохранять ноутбук как пару: .ipynb (для работы) и .py (чистый код для Git). Это позволяет использовать всю мощь контроля версий, делая код-ревью понятным и чистым.
Заключение
Jupyter Notebook прошел путь от нишевого инструмента для научных вычислений до главного пульта управления в мире больших данных и искусственного интеллекта. Он снижает порог входа в сложные технологии, позволяя фокусироваться на сути задачи, а не на настройке компиляторов.
Будь вы новичок, изучающий Python, аналитик, пишущий SQL-запросы, или дата-инженер, настраивающий Spark-джобы через Airflow — Jupyter Notebook станет вашим надежным проводником. Главное — помнить про гигиену кода и регулярно нажимать «Restart & Run All». Напоследок предлагаем посмотреть видео про основы работы с Jupyter Notebook которое является частью бесплатного видео курса записанного преподавателями «Школы больших данных» и доступного на сайте нашего проекта «Школы Питон»