 1234
1234 
Содержание
- Модель данных — язык, на котором бизнес говорит с технологиями
- Три уровня погружения: от идеи до таблицы в базе
- Концептуальная модель: взгляд с высоты птичьего полета
- Логическая модель: детализированный чертеж
- Физическая модель: проект для строителей
- Классика жанра: нормализация и денормализация
- Моделирование для аналитики: строим хранилище данных
- Два титана: Инмон vs. Кимбалл
- Data Vault 2.0: гибкость и масштабируемость
- Anchor Modeling: для самых дотошных
- Моделирование в мире NoSQL и Big Data
- Заключение и анонс
Модель данных — язык, на котором бизнес говорит с технологиями
Есть старая айтишная мудрость: «Написать код легко. Гораздо сложнее написать правильный код для правильной модели данных». И это абсолютная правда. Любую ошибку в коде можно исправить относительно безболезненно. А вот ошибка, заложенная в саму структуру данных, в модель, обходится на порядок дороже. Это как ошибка в проекте фундамента здания: когда стены уже возведены, а крыша построена, исправить ее можно только путем полного сноса и перестройки.
Именно поэтому моделирование и дизайн данных (Data Modeling and Design) — это не скучная техническая рутина, а одна из самых ответственных и творческих задач в мире данных. Это процесс, в ходе которого мы переводим хаотичные, часто противоречивые требования бизнеса на строгий и однозначный язык данных.
Последствия плохого моделирования катастрофичны:
- Системы-тупики: Приложение, построенное на кривой модели, невозможно развивать. Каждая новая «фича» превращается в месяцы страданий для команды разработки.
- Отчеты-вруны: Отчеты из разных отделов показывают разные цифры, потому что у каждого свое, «кустарное» представление о том, что такое «Клиент» или «Продажа».
- Пропасть непонимания: Бизнес-заказчик просил одно, аналитик понял другое, разработчик реализовал третье. Все потому, что не было единого, формализованного «контракта», которым и является модель данных.
В этой статье мы разберемся, что такое моделирование на самом деле, пройдем путь от высокоуровневой концепции до конкретной таблицы в базе данных, изучим классические и современные подходы к моделированию и посмотрим, как эти принципы адаптируются к миру Big Data и NoSQL.
Три уровня погружения: от идеи до таблицы в базе
Процесс моделирования похож на работу архитектора, который постепенно детализирует свой проект. DAMA-DMBOK выделяет три основных уровня моделей, каждый из которых решает свою задачу и предназначен для своей аудитории.
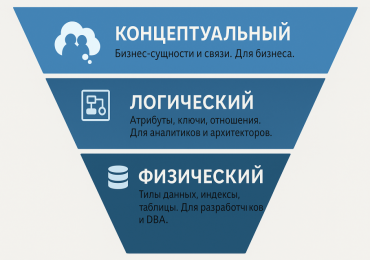
Концептуальная модель: взгляд с высоты птичьего полета
Это самый высокий уровень абстракции, «карта мира» для бизнеса. Концептуальная модель создается в первую очередь для того, чтобы договориться с бизнес-заказчиками и стейкхолдерами. Она фиксирует только самые важные вещи:
- Ключевые бизнес-сущности: Что в принципе существует в нашем бизнесе?
- Связи между ними: Как эти сущности друг с другом взаимодействуют?
На этом уровне нет никаких технических деталей: ни типов данных, ни первичных ключей, ни индексов. Только бизнес и ничего лишнего.
Пример для интернет-магазина:
На концептуальной модели мы бы изобразили три-четыре прямоугольника: «Клиент», «Заказ», «Товар», «Поставщик». И соединили бы их линиями, которые подписываются глаголами: «Клиент делает Заказ», «Заказ содержит Товар», «Поставщик поставляет Товар». Все. Этого достаточно, чтобы убедиться, что мы с бизнесом одинаково понимаем основные сущности.
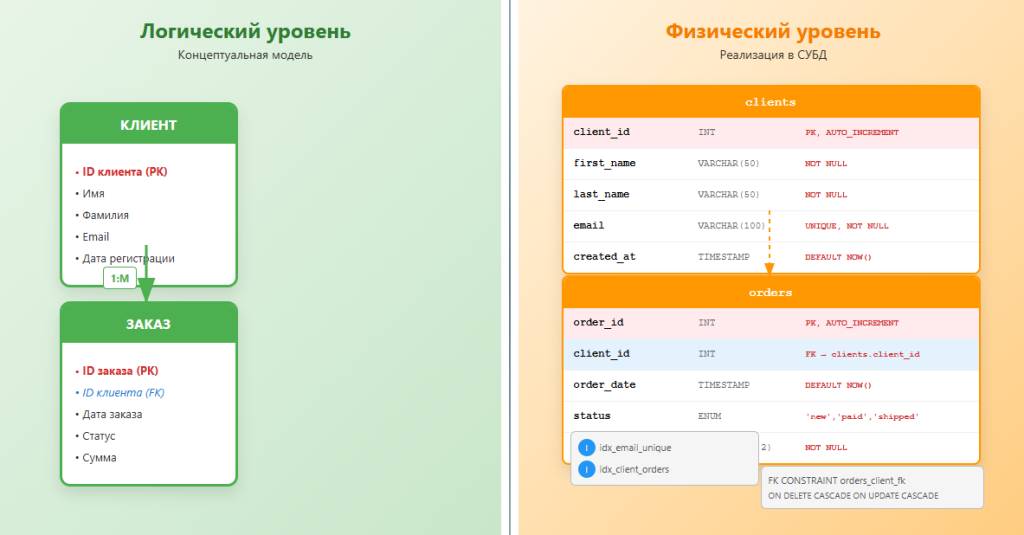
Логическая модель: детализированный чертеж
Если концептуальная модель — это эскиз, то логическая — это уже полноценный рабочий чертеж. Она все еще технологически-независима (то есть, нам не важно, будет это PostgreSQL или Oracle), но уже содержит всю необходимую для разработчиков информацию:
- Все атрибуты каждой сущности.
- Первичные и внешние ключи, которые определяют уникальность записей и связи между ними.
- Типы связей (один-к-одному, один-ко-многим, многие-ко-многим).
- Ограничения и правила (например, «поле Email не может быть пустым»).
Пример для интернет-магазина:
Сущность «Клиент» превращается в таблицу Clients с атрибутами ClientID (PK), FirstName, LastName, Email. Сущность «Заказ» — в таблицу Orders с атрибутами OrderID (PK), OrderDate, Status, ClientID (FK). Появление внешнего ключа ClientID (FK) в таблице Orders как раз и реализует связь «один-ко-многим»: у одного клиента может быть много заказов.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Физическая модель: проект для строителей
Это финальный этап, на котором логический «чертеж» адаптируется под конкретную технологию — выбранную СУБД. Физическая модель учитывает все особенности и ограничения конкретной «стройплощадки».
Здесь определяются:
- Точные типы данных: Не просто «строка», а VARCHAR(255) или NVARCHAR(MAX). Не просто «дата», а TIMESTAMP WITH TIME ZONE.
- Индексы: Для ускорения поиска по часто используемым полям.
- Секционирование (партиционирование): Разделение больших таблиц на части для повышения производительности.
- Имена таблиц и полей: С учетом соглашений об именовании, принятых в компании.
По сути, физическая модель — это уже почти готовый SQL-скрипт для создания таблиц в базе данных.
Классика жанра: нормализация и денормализация
В мире реляционных баз данных существует фундаментальный процесс, который называется нормализацией. Его придумал «отец» реляционной модели Эдгар Кодд, и главная цель нормализации — устранить избыточность (дублирование) данных, чтобы обеспечить их целостность и непротиворечивость.
Проще говоря, нормализация — это набор правил, которые помогают нам правильно «разложить» данные по разным таблицам. Существует несколько нормальных форм (НФ), но на практике для большинства систем (особенно транзакционных, OLTP) достаточно придерживаться первых трех.
- Первая нормальная форма (1НФ): «Нет повторяющимся группам». Все атрибуты должны быть атомарными, то есть неделимыми. Нельзя в одном поле хранить список телефонов через запятую. Для этого нужно создать отдельную таблицу Телефоны.
- Вторая нормальная форма (2НФ): «Все неключевые атрибуты полностью зависят от всего первичного ключа». Это правило актуально для таблиц с составным первичным ключом. Если какой-то атрибут зависит только от части ключа, его нужно вынести в отдельную таблицу.
- Третья нормальная форма (3НФ): «Неключевые атрибуты не зависят от других неключевых атрибутов». Если у нас в таблице заказов есть Цена, Количество и Сумма (Цена * Количество), то поле Сумма является избыточным (транзитивная зависимость). Его нужно убрать, так как его всегда можно вычислить.
Следование этим правилам делает нашу базу данных чистой, непротиворечивой и защищенной от аномалий при обновлении. Но за все приходится платить. Цена нормализации — снижение скорости чтения данных. Чтобы собрать полную информацию о заказе, нам придется соединять (JOIN) несколько таблиц, что является довольно дорогой операцией.
Именно поэтому существует обратный процесс — денормализация. Это сознательное, контролируемое «нарушение» правил нормализации ради производительности. В аналитических системах и хранилищах данных (OLAP), где 99% операций — это чтение больших объемов данных, денормализация является не ошибкой, а абсолютной необходимостью. Мы заранее «склеиваем» данные в широкие таблицы, чтобы аналитикам не приходилось делать сложные JOIN’ы.
Искусство моделировщика как раз и заключается в том, чтобы найти правильный баланс между строгостью нормализации и прагматичностью денормализации, в зависимости от задачи.
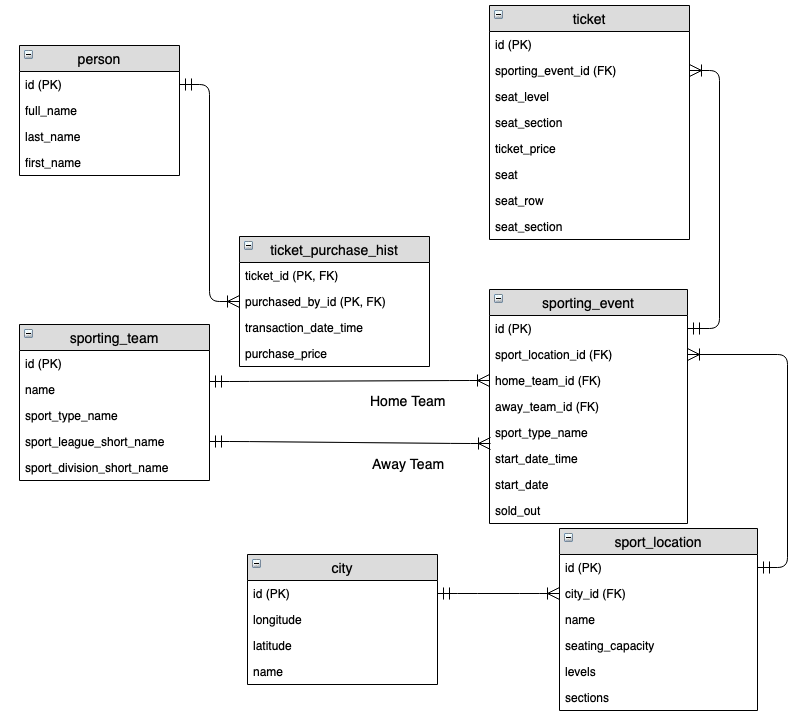
Моделирование для аналитики: строим хранилище данных
Моделирование для транзакционных систем (OLTP) и для аналитических (OLAP) — это два разных мира. Если в первом мы стремимся к нормализации, то во втором — к эффективности агрегации и анализа. Давайте рассмотрим основные подходы, которые используются при строительстве хранилищ данных.
Два титана: Инмон vs. Кимбалл
Исторически сложилось два фундаментальных подхода к проектированию DWH.
- Подход Билла Инмона («Сверху-вниз»): Инмон, которого называют «отцом хранилищ данных», предложил строить DWH по аналогии с централизованным заводом. Сначала все данные из разных систем-источников собираются в единое, нормализованное (в 3НФ) корпоративное хранилище, которое он назвал Corporate Information Factory (CIF). Это и есть та самая «единая версия правды». И только потом, из этого центрального хранилища, для разных отделов создаются специализированные, денормализованные витрины данных для анализа.
- Подход Ральфа Кимбалла («Снизу-вверх»): Кимбалл предложил более прагматичный и гибкий подход. Вместо того чтобы сразу строить гигантский центральный завод, он предложил начинать с отдельных «цехов» — витрин данных, ориентированных на конкретные бизнес-процессы (продажи, закупки, маркетинг). Эти витрины строятся по определенной методике, используя так называемую схему «звезда» (star schema). В центре «звезды» находится таблица фактов (например, Продажи), которая содержит числовые, измеримые показатели (количество, сумма). А вокруг нее лучами расходятся таблицы измерений (Товары, Клиенты, Календарь, Магазины), которые содержат описательные атрибуты, по которым можно группировать и фильтровать факты.
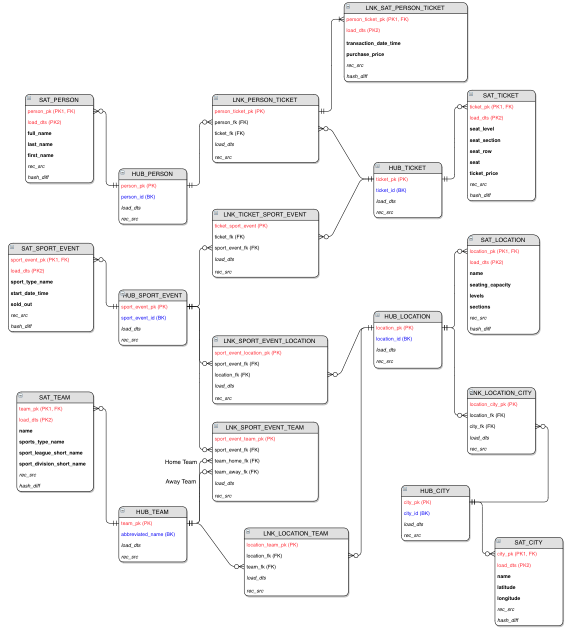
Data Vault 2.0: гибкость и масштабируемость
Классические подходы Инмона и Кимбалла отлично работали десятилетиями, но в эру Big Data, когда новые источники данных появляются каждую неделю, их стало не хватать. Они оказались недостаточно гибкими. Ответом на этот вызов стала методология Data Vault 2.0, разработанная Дэном Линстедтом.
Data Vault — это гибридный подход, который вобрал в себя лучшее от обоих «титанов». Его основная цель — создать максимально гибкий, аудируемый и легко расширяемый слой сырых, исторических данных в DWH.
Модель Data Vault строится из трех простых, как кирпичики Lego, типов сущностей:
- Hub (Хаб): Хранит уникальные бизнес-ключи наших основных сущностей (например, CustomerID, ProductID). Хабы почти никогда не меняются.
- Link (Связь): Реализует отношения «многие-ко-многим» между хабами. Например, Link_Order будет связывать хабы Клиент, Товар и Сотрудник.
- Satellite (Спутник): Хранит все описательные, исторические атрибуты, которые относятся к хабу или связи. Если у клиента поменялся адрес, мы не перезаписываем старый, а просто добавляем новую запись в спутник с новой датой.
Такая структура позволяет очень легко добавлять новые источники данных, не перестраивая всю модель, и обеспечивает 100% аудируемость — мы всегда можем посмотреть, как выглядели данные на любой момент времени в прошлом.
Anchor Modeling: для самых дотошных
Иногда упоминают еще один подход — Anchor Modeling. По сути, это экстремальная форма нормализации (до 6НФ) и дальнейшее развитие идей Data Vault. В этой модели каждый атрибут каждой сущности хранится в отдельной таблице. Это обеспечивает абсолютную гибкость для отслеживания истории изменений каждого, даже самого незначительного атрибута. Однако цена такой гибкости — огромное количество таблиц и очень сложные запросы. На практике этот подход используется довольно редко, в специфических задачах, где важна максимальная гранулярность истории.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Моделирование в мире NoSQL и Big Data
С появлением NoSQL-баз данных (MongoDB, Cassandra, Redis и др.) возник популярный миф о том, что «схема больше не нужна» (schemaless). Это одно из самых опасных заблуждений.
Схема никуда не делась. Она просто переехала из базы данных в код вашего приложения (schema-on-read). База данных действительно может хранить документы с абсолютно разной структурой, но ваше приложение все равно ожидает, что в документе «Пользователь» будут поля name и email. Если их там не окажется, приложение упадет. Ответственность за поддержание схемы просто легла на плечи разработчиков.
Ключевое отличие в подходе к моделированию для NoSQL заключается в другом.
- В реляционном мире мы моделируем данные, как они есть, стремясь к нормализации и единой, консистентной структуре (schema-on-write).
- В мире NoSQL мы чаще всего моделируем данные, как их будут читать, оптимизируя структуру под конкретные, самые частые запросы приложения.

Это означает гораздо более широкое применение денормализации и дублирования данных. Например, в документоориентированной СУБД вроде MongoDB, вместо того чтобы хранить заказы и товары в разных коллекциях, мы можем вложить весь список товаров прямо в документ заказа. Это ускорит чтение информации о заказе, так как не потребует JOIN’ов.
В колоночных базах данных, таких как Cassandra, моделирование идет еще дальше. Там принято создавать разные таблицы с одними и теми же данными, но с разным первичным ключом, чтобы оптимизировать под разные типы запросов.
Моделирование для NoSQL требует от разработчика глубокого понимания паттернов доступа к данным и готовности жертвовать консистентностью ради производительности и масштабируемости.
Заключение и анонс
Мы убедились, что моделирование данных — это не просто технический навык, а фундаментальная дисциплина на стыке бизнеса, аналитики и инженерии. Это процесс перевода человеческого языка бизнес-требований на строгий язык машин.
Правильно выбранная модель — это залог того, что ваша система будет гибкой, производительной и понятной. А выбор правильного подхода к моделированию — будь то классическая «звезда» Кимбалла, гибкий Data Vault или оптимизированные под чтение NoSQL-паттерны — напрямую зависит от вашей архитектуры и бизнес-задач.
В рамках одной статьи можно лишь коснуться вершин айсберга под названием «моделирование данных». На практике же освоение таких методологий, как ER-моделирование, Data Vault или BEAM, требует часов работы с реальными кейсами, проектирования моделей в специализированных инструментах и разбора ошибок под руководством опытного наставника. Именно на такой глубокой практической работе и строятся профессиональные курсы для архитекторов и аналитиков данных.
Мы спроектировали наше здание (архитектура) и детально распланировали все комнаты (моделирование). Теперь пора подумать о том, где и как мы будем все это хранить, и как будем за этим ухаживать. В следующей статье мы поговорим о хранении данных

