 971
971 
Содержание
- Архитектура данных— невидимый фундамент вашего бизнеса
- Принципы хорошей архитектуры по DMBOK: что в "черном ящике"?
- Компоненты корпоративной архитектуры данных
- Корпоративная модель данных (Enterprise Data Model, EDM)
- Дизайн потоков данных (Data Flow Design)
- Связь с другими фреймворками (TOGAF, Zachman)
- Современные архитектурные паттерны Big Data: выбираем правильный инструмент
- Классика: Lambda и Kappa
- Современный стандарт: Data Lakehouse
- Революция: Data Mesh и Data Fabric
- Кейс из реальной жизни: как ритейлер ускорил аналитику в 10 раз
- Решение (Архитектурная трансформация)
- Результат
- Заключение и анонс
- Рекомендованные материалы
Архитектура данных— невидимый фундамент вашего бизнеса
Представьте, что вы решили построить небоскреб. С чего вы начнете? Вряд ли с выбора панорамных окон и покупки дорогой итальянской мебели для пентхауса. Любой здравомыслящий человек начинает с фундамента. С прочного, продуманного, железобетонного основания, способного выдержать вес сотен этажей, порывы ветра и даже землетрясения.
В мире данных все точно так же. Красивые BI-дашборды, умные AI-модели и продвинутая аналитика — это та самая «мебель» в пентхаусе. А архитектура данных (Data Architecture) — это и есть тот самый невидимый, но критически важный фундамент. Если он спроектирован наспех, из неподходящих материалов и без учета будущего роста, то все, что вы построите сверху, рано или поздно даст трещину или полностью рухнет.
Симптомы плохой архитектуры знакомы многим компаниям:
- Информационные колодцы (Data Silos): Данные о клиентах заперты в десятках разных систем, которые не умеют «общаться» друг с другом. Чтобы собрать единый профиль клиента, аналитикам приходится творить чудеса с Excel.
- Черепашья скорость: Простейшие аналитические запросы выполняются часами, а иногда и сутками, парализуя работу бизнеса.
- Хрупкость и негибкость: Попытка добавить в систему новый источник данных или изменить бизнес-логику превращается в многомесячный IT-проект с непредсказуемым результатом.
Исторически компании пытались решить эти проблемы с помощью массивных, централизованных Корпоративных Хранилищ Данных (DWH). Но в эпоху Big Data, когда данные льются рекой из сотен источников, этот подход стал слишком медленным и неповоротливым. На смену ему пришли гибкие «Озера Данных» (Data Lake), затем — гибридные «Озерные Дома» (Data Lakehouse), а сегодня мы наблюдаем рождение революционных, децентрализованных концепций вроде Data Mesh.
Это не просто смена модных названий. Это фундаментальная эволюция подходов к проектированию того самого «фундамента». В этой статье мы разберемся, что такое архитектура данных с точки зрения DAMA-DMBOK, из каких принципов и компонентов она состоит, и какие современные паттерны помогут вам построить основание, способное выдержать небоскреб ваших data-driven амбиций.
Принципы хорошей архитектуры по DMBOK: что в «черном ящике»?
Многие ошибочно полагают, что архитектура данных — это набор схем в Visio и список закупленных технологий. DAMA-DMBOK учит нас смотреть глубже. Архитектура данных — это в первую очередь стратегический мост между бизнес-целями компании и их технологической реализацией.
Хорошая архитектура — это не та, в которой используются самые модные технологии, а та, которая максимально эффективно решает задачи бизнеса. Согласно DMBOK, любая надежная архитектура должна строиться на нескольких ключевых принципах.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
25 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800

- Соответствие бизнес-целям (Business Alignment)
Это главный принцип. Архитектура должна напрямую поддерживать то, чего хочет достичь бизнес.
Пример: Если бизнес-стратегия компании — стать лидером в real-time персонализации на сайте, то архитектура данных обязана включать компоненты для потоковой обработки данных, такие как Apache Kafka и Spark Streaming. Архитектура, рассчитанная только на пакетную обработку раз в сутки, здесь не сработает. - Масштабируемость и эластичность (Scalability & Elasticity)
Архитектура должна быть способна «переваривать» растущие объемы данных и количество пользователей без кардинальной перестройки и падения производительности. Облачные технологии сделали этот принцип особенно актуальным, добавив понятие эластичности — способности выделять и освобождать ресурсы по требованию. - Гибкость и адаптивность (Flexibility & Adaptability)
Бизнес меняется постоянно: появляются новые продукты, каналы продаж, источники данных. Архитектура не должна быть монолитным истуканом. Она должна быть спроектирована так, чтобы добавление нового источника или изменение бизнес-логики было относительно быстрым и безболезненным процессом. - Безопасность «по умолчанию» (Security by Design)
Механизмы защиты данных (шифрование, управление доступом, маскирование) должны быть неотъемлемой частью архитектуры, а не «заплаткой», которую пытаются прикрутить в последний момент перед запуском. - Экономическая эффективность (Cost Effectiveness)
Архитектор должен постоянно искать баланс между производительностью, надежностью и общей стоимостью владения (Total Cost of Ownership, TCO). Иногда использование чуть менее производительной, но в 10 раз более дешевой технологии является самым правильным архитектурным решением.
Компоненты корпоративной архитектуры данных
Архитектура данных на уровне предприятия — это не одна схема, а набор взаимосвязанных «чертежей» и документов, которые описывают информационный ландшафт компании с разных ракурсов. DMBOK выделяет несколько ключевых артефактов.
Корпоративная модель данных (Enterprise Data Model, EDM)
Представьте, что вы смотрите на город с высоты птичьего полета. Вы не видите отдельные машины и людей, но четко различаете районы, главные проспекты, мосты и ключевые здания. Корпоративная модель данных — это и есть такая «карта города» для ваших данных.
Это не детальная физическая схема базы данных. Это высокоуровневая, концептуальная модель, которая описывает:
- Ключевые бизнес-сущности: Что самое важное для нашего бизнеса? Обычно это «Клиент», «Продукт», «Заказ», «Сотрудник», «Поставщик».
- Атрибуты: Какими основными характеристиками обладают эти сущности? (Например, у «Клиента» есть «Имя», «Адрес», «Телефон»).
- Связи: Как эти сущности связаны между собой? («Клиент» делает много «Заказов», в каждом «Заказе» есть много «Продуктов»).
Главная ценность EDM в том, что она создается совместно бизнесом и IT и становится единым языком для всей компании. Она помогает устранить путаницу, когда маркетинг называет «лидом» то, что продажи считают «контактом».
Дизайн потоков данных (Data Flow Design)
Если EDM — это статичная карта, то дизайн потоков данных — это схема транспортных маршрутов. Этот артефакт визуализирует, как данные движутся по организации:
- Где они рождаются (в какой системе создается новая запись о клиенте)?
- Как они путешествуют между системами (например, из CRM в систему биллинга)?
- Где они трансформируются и обогащаются (например, в ETL-процессе)?
- Где они в конечном итоге используются (например, в BI-отчете)?
- Где они архивируются и «умирают»?
Анализ потоков данных помогает выявлять «бутылочные горлышки», находить точки отказа, оптимизировать процессы и понимать, откуда на самом деле берутся цифры в отчетах.
Связь с другими фреймворками (TOGAF, Zachman)
DAMA-DMBOK не существует в вакууме. Для крупных организаций важно понимать, что архитектура данных — это лишь один из доменов общей корпоративной архитектуры (Enterprise Architecture). Такие фреймворки, как TOGAF или Zachman, описывают, как управлять архитектурой всего предприятия (бизнес-процессы, приложения, технологии, данные). DMBOK здесь выступает как детальная инструкция для домена данных, которая отлично интегрируется в общую картину.
Современные архитектурные паттерны Big Data: выбираем правильный инструмент
Теория и принципы — это важно, но как это выглядит на практике в 2025 году? Давайте разберем основные архитектурные паттерны, которые сегодня используются для построения современных платформ данных.
Классика: Lambda и Kappa
- Lambda Architecture: Этот паттерн был одним из первых ответов на вызовы Big Data. Его суть — в разделении обработки данных на два параллельных потока:
- Batch Layer (Пакетный слой): Медленный, но надежный слой, который обрабатывает все исторические данные целиком (например, раз в сутки) и создает полные, точные представления (Batch Views).
- Speed Layer (Слой реального времени): Быстрый слой, который обрабатывает только самые свежие данные «на лету» и создает инкрементальные обновления.
- Результаты этих двух слоев объединяются на уровне запросов, чтобы дать пользователю полную картину.
- Главный недостаток: Сложность. Одну и ту же бизнес-логику часто приходилось реализовывать дважды — для batch и для streaming слоев.
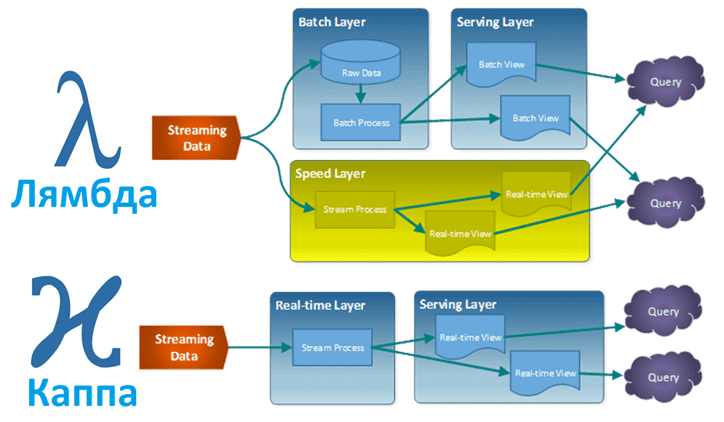
- Kappa Architecture: Этот паттерн появился как упрощение Lambda. Его автор, Джей Крепс (один из создателей Kafka), предложил идею: а что, если рассматривать все данные как бесконечный поток (стрим)? Тогда нам не нужен отдельный batch-слой. Мы можем обрабатывать все в едином streaming-конвейере, а если нужно пересчитать историю — просто «перепроиграть» поток с самого начала.
- Преимущество: Значительное упрощение архитектуры и избавление от дублирования кода.
Современный стандарт: Data Lakehouse
Концепция Data Lakehouse — пожалуй, самый популярный сегодня подход. Он стремится объединить лучшее из двух миров:
- От Data Lake: Дешевое, гибкое хранение любых типов данных (структурированных и неструктурированных) в открытых форматах (например, Parquet) в облачных хранилищах вроде Amazon S3.
- От Data Warehouse: Надежность, ACID-транзакции, управление версиями данных и высокая производительность запросов.
Это стало возможным благодаря появлению открытых табличных форматов, таких как Delta Lake, Apache Iceberg и Apache Hudi. Эти технологии, по сути, добавляют «умный» слой метаданных поверх «глупых» файлов в Data Lake, что позволяет работать с ними как с полноценными транзакционными таблицами в базе данных.
Архитектура Lakehouse позволяет построить единую платформу, где можно выполнять и классические BI-запросы, и задачи Data Science, и даже стриминговую аналитику, не копируя данные между разными системами.

Революция: Data Mesh и Data Fabric
В последние годы набирают популярность две концепции, которые предлагают еще раз переосмыслить подход к архитектуре.
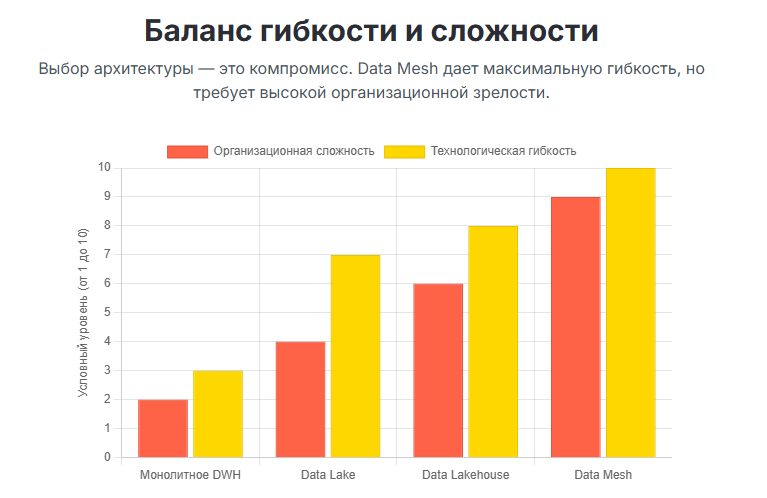
- Data Mesh (Социо-технический подход): Это не столько технологический паттерн, сколько новая организационная парадигма. Она говорит: «Хватит строить централизованные команды и платформы, которые становятся «бутылочным горлышком»!». Вместо этого Data Mesh предлагает децентрализацию и строится на четырех принципах:
- Доменная ориентированность: Ответственность за данные передается из центральной IT-команды в бизнес-домены (команды, которые эти данные создают и лучше всех понимают).
- Данные как продукт (Data as a Product): Каждая доменная команда должна относиться к своим данным как к продукту, у которого есть потребители (другие команды). Этот продукт должен быть легко находимым, понятным, надежным и доступным.
- Self-service платформа: Центральная IT-команда предоставляет доменам общую платформу и инструменты, которые позволяют им самостоятельно создавать свои «продукты данных».
- Федеративное управление (Federated Governance): Общие правила и стандарты (Governance) создаются не «сверху вниз», а совместно представителями всех доменов.
- Data Fabric (Технологический подход): Если Data Mesh — это про организацию, то Data Fabric — это про умную автоматизацию. Концепция Data Fabric предлагает создать «интеллектуальный слой», который соединяет все источники и потребителей данных в компании. Этот слой, используя метаданные и AI, автоматизирует многие процессы: интеграцию данных, управление качеством, создание единого каталога, оптимизацию запросов. Цель Data Fabric — скрыть от конечного пользователя всю сложность нижележащего ландшафта и предоставить ему нужные данные в нужное время и в нужном формате.
Lakehouse, Data Mesh и Data Fabric — не взаимоисключающие концепции. Часто Data Fabric используется как технологическая основа для реализации Data Mesh, а в качестве хранилища для «продуктов данных» в Data Mesh может выступать Lakehouse.
Кейс из реальной жизни: как ритейлер ускорил аналитику в 10 раз
Давайте посмотрим, как эти концепции применяются на практике.
Ситуация (Проблема). Крупная ритейл-сеть с сотнями магазинов и быстрорастущим онлайн-каналом столкнулась с классическими «болезнями роста». Их старое, неповоротливое корпоративное хранилище данных (DWH) на базе Oracle уже не справлялось с нагрузкой.
- Ежедневный расчет остатков и продаж занимал почти 24 часа. Бизнес получал данные с опозданием на день.
- Маркетологи не могли быстро тестировать гипотезы (например, запустить промо-акцию и через час оценить ее эффект), так как данные из кассовых систем и с сайта попадали в DWH слишком долго.
- Любой новый отчет требовал долгой разработки со стороны центральной IT-команды.
Решение (Архитектурная трансформация)
Компания приняла решение о кардинальной перестройке архитектуры.
- Переход в облако и Lakehouse: Вместо дорогого и неэластичного DWH была построена новая платформа в облаке Amazon Web Services. В качестве центрального хранилища был выбран Amazon S3, а поверх него развернут движок Databricks с использованием формата Delta Lake. Это позволило создать единую Lakehouse-платформу.
- Внедрение принципов Data Mesh: Было решено отказаться от идеи, что одна центральная команда отвечает за все данные. Были выделены бизнес-домены: «Продажи в магазинах», «E-commerce», «Логистика», «Клиентская аналитика». В каждом домене была сформирована кросс-функциональная команда из бизнес-экспертов и дата-инженеров, которая стала отвечать за свои «продукты данных» (например, витрину с чеками или очищенный профиль клиента).
- Self-service аналитика: Центральная платформа предоставила доменам инструменты для самостоятельной работы, а аналитики из бизнеса получили прямой доступ к данным через BI-инструменты.
Результат
- Скорость: Время расчета ключевых бизнес-метрик сократилось с 24 часов до 15 минут.
- Гибкость: Маркетологи получили возможность анализировать данные о продажах практически в реальном времени, что позволило запускать и оценивать эффективность коротких промо-акций «на лету».
- Автономность: Количество запросов в центральную IT-команду на создание отчетов сократилось на 80%. Бизнес-команды смогли самостоятельно проверять гипотезы, что увеличило скорость принятия решений в 10 раз.
Архитектура Данных
Код курса
ARMG
Ближайшая дата курса
25 февраля, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Заключение и анонс
Как мы видим, архитектура данных — это далеко не скучные схемы в Visio. Это мощнейший рычаг, который может либо тормозить развитие компании, либо выводить ее на новую орбиту скорости и эффективности. Выбор правильного архитектурного паттерна — будь то надежный Lakehouse или революционный Data Mesh — должен основываться не на моде, а на зрелости компании, ее культуре и, самое главное, ее бизнес-стратегии.
Правильная архитектура создает платформу для инноваций, снижает операционные издержки и позволяет бизнесу быстрее реагировать на вызовы рынка. Это невидимый, но абсолютно незаменимый фундамент для построения настоящей data-driven организации.
Теоретически разобраться в отличиях Data Mesh от Lakehouse можно, прочитав десяток статей. Но спроектировать такую архитектуру на практике, выбрать правильные компоненты, разработать дорожную карту миграции и защитить ее перед бизнесом — это инженерная задача высочайшего уровня. Именно такие практические навыки проектирования и сравнения архитектурных паттернов на реальных кейсах являются ядром современных курсов для архитекторов данных.
Мы спроектировали фундамент. Теперь пора заняться детальным проектированием комнат и этажей. В следующей статье мы погрузимся в мир Моделирования и дизайна данных (Data Modeling and Design) и разберемся, как правильно описывать бизнес-сущности — от классических ER-диаграмм до Data Vault и моделей для NoSQL.
Рекомендованные материалы
- DAMA-DMBOK: Data Management Body of Knowledge, Second Edition. (Глава 4: Data Architecture).
- Designing Data-Intensive Applications by Martin Kleppmann. (Фундаментальная книга по архитектуре распределенных систем).
- How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh by Zhamak Dehghani. (Оригинальная статья, положившая начало концепции Data Mesh).
- What is a Data Lakehouse? (Официальный сайт Databricks с подробным объяснением концепции).

