
Сегодня рассмотрим преимущества потоковой обработки данных с Apache Kafka и Flink над пакетными Big Data технологиями в виде Hadoop, Spark и Oozie. В качестве примера разберем реальный кейс аналитики больших данных по пользовательским сеансам в музыкальном онлайн-сервисе Spotify, а также возможность замены Apache Flink на Spark Structured Streaming. От рекламы...
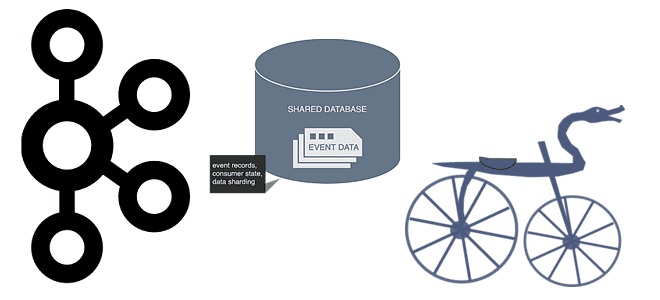
Однажды мы уже разбирали, способна ли Apache Kafka заменить собой базы данных в мире Big Data. Сегодня рассмотрим обратную постановку этой задачи: можно ли реализовать постоянный обмен сообщениями в стиле Kafka с помощью СУБД. Читайте далее, что общего у Kafka с базой данных, чем они отличаются и почему попытки заменить...

Сегодня рассмотрим, что такое Data Build Tool, как этот ETL-инструмент связан с корпоративным хранилищем и озером данных, а также чем полезен дата-инженеру. В качестве практического примера разберем кейс подключения DBT к Apache Spark, чтобы преобразовать данные в таблице Spark SQL на Amazon Glue со схемой поверх набора файлов в AWS...

Продолжая вчерашний разговор про потоковую аналитику больших данных на Apache Kafka и Pinot, сегодня рассмотрим особенности интеграции этих систем. Читайте далее, как входные данные Kafka разделяются, реплицируются и индексируются в Pinot, каким образом выполняется обработка данных через распределенные SQL-запросы. Также разберем, почему управление памятью серверов Pinot, потребляющих данные из Kafka,...

В этой статье разберем несколько популярных сценариев потоковой аналитики больших данных на Kafka, CDC-платформе Debezium и быстром OLAP-хранилище Apache Pinot. Читайте далее, почему все эти Big Data технологии отлично подходят для консолидации и интеграции данных из разных источников в реальном времени, включая аналитический аудит изменений, отслеживание событий в распределенном домене...

В феврале 2021 года разработчики корпоративной версии Apache Kafka с коммерческой поддержкой, компания Confluent, выпустили премиум-коннектор к Oracle – одной из главных реляционных баз данных мира enterprise. Разбираемся, кому и зачем это нужно, а также как устроена такая интеграция SQL-СУБД и потоковой аналитики Big Data с применением CDC-подхода. Реляционный монолит...

В этой статье по обучению дата-инженеров и разработчиков Big Data рассмотрим, как эффективно записать большие данные в СУБД PostgreSQL с применением Apache Spark. Читайте далее, чем отличается foreach() от foreachBatch(), как это связано с количеством подключений к БД, асимметрией разделов и семантикой доставки сообщений. Как Spark-приложение записывает данные в PostgreSQL...

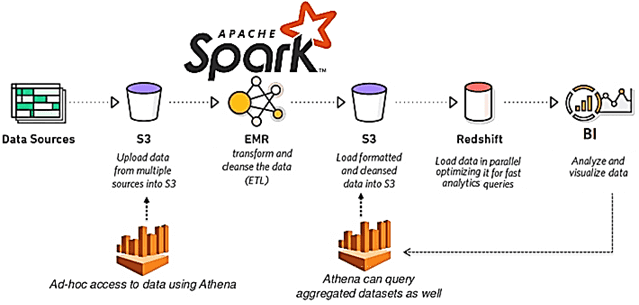
Сегодня рассмотрим пример построения системы аналитики больших данных для мониторинга финансовых транзакций в реальном времени на базе облачного Delta Lake и конвейера распределенных приложений Apache Kafka, Spark Structured Streaming и других технологий Big Data. Читайте далее о преимуществах облачного Delta Lake от Databricks над традиционным Data Lake. Постановка задачи: финансовая...

Недавно мы уже упоминали о некоторых продуктах на базе Apache Spark. Продолжая обучение основам Big Data, сегодня рассмотрим, что такое SnappyData или TIBCO ComputeDB и как это связано с популярным фреймворком разработки распределенных приложений аналитики больших данных. Кому и зачем нужны дополнительные решения поверх Apache Spark При всей популярности Apache Spark,...

Сегодня поговорим про бакетирование таблиц в Apache Spark для оптимизации производительности заданий и снижения затрат на кластер при их выполнении. Читайте далее, что такое Bucketing в Spark SQL и как это предотвращает операции перетасовки в приложениях аналитики больших данных. Что такое Bucketing и зачем это нужно в Big Data Бакетирование...
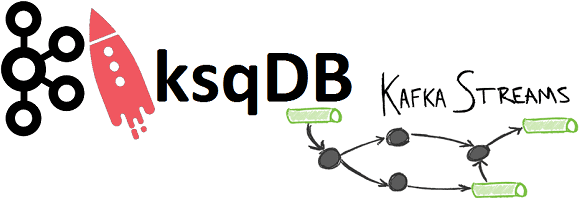
Продолжая разговор про обучение разработчиков Apache Kafka, сегодня рассмотрим, чем ksqlDB отличается от Kafka Streams. Также читайте далее про основные достоинства и недостатки перезапуска KSQL в виде отдельной базы данных потоковой передачи событий с API-интерфейсом на основе SQL для запроса и обработки информации из топиков Kafka. ksqlDB vs Kafka Streams:...
В этой статье поговорим про KSQL на примере кейса компании американской компании Pluralsight, которая предлагает различные обучающие видео-курсы для разработчиков ПО, ИТ-администраторов и творческих профессионалов. Читайте далее, как использовать Apache Kafka с Kubernetes для построения надежных систем потоковой аналитики больших данных, а также чем ksqlDB отличается от KSQL. Apache Kafka...

В этой статье рассмотрим, как сделать SQL-запросы к колоночному хранилищу больших данных с поддержкой ACID-транзакций Delta Lake еще быстрее с помощью Apache Presto. Читайте далее про синергию совместного использования Apache Spark и Presto в Delta Lake для ускорения OLAP-процессов при работе с Big Data. Еще раз об OLAP: схема звезды...

Чтобы показать, насколько разной бывает аналитика больших данных, сегодня рассмотрим кейс международной компании Spidertracks, которая с помощью технологий Big Data создает ИТ-решения для отслеживания, связи и управления безопасностью воздушных судов. Читайте далее, почему для потоковой обработки событий был выбран Kinesis Analytics for SQL, а не конвейер из Apache Kafka и...

Сегодня продолжим разбираться с реализацией CDC-подхода в современных Big Data решениях и погрузимся в Databricks Delta Lake – облачный уровень хранения и аналитики больших данных с поддержкой ACID-транзакций. Читайте далее про переход от ночных ETL-пакетов с Informatica к быстрому обновлению данных в Amazon S3 на конвейере Spark и Kafka. Возможности...

Продолжая разговор про оптимизацию Apache Spark и повышение эффективности Big Data приложений, сегодня рассмотрим способы ускорения Shuffle-операций в Spark SQL, разберем, чем хороши широковещательные JOIN-операции и как количество разделов влияет на производительность запросов в распределенных приложениях аналитики больших данных. 4 способа оптимизации Shuffle-операций При аналитике больших данных с помощью Apache...
Мы уже рассказывали, почему качество данных является важнейшим аспектом разработки и эксплуатации Big Data систем. Приемлемое для эффективного использования качество массивов информации достигается не только с помощью процессов подготовки датасета к машинному обучению и профилирования данных, но и за счет их согласования. Читайте далее, что такое Data reconciliation, зачем это...

В этой статье поговорим про интеграцию данных с помощью CDC-подхода и репликацию SQL-таблиц из корпоративной СУБД в несколько разных удаленных хранилищ в реальном времени с применением Apache Kafka и Debezium, развернутых в Kafka Connect и Confluent Cloud. Постановка задачи: CDC с Big Data в реальном времени Рассмотрим кейс, который часто...

Сегодня рассмотрим несколько простых способов ускорить обработку больших данных в рамках конвейера задач Apache Spark. Читайте далее про важность тщательной оценки входных и выходных данных, рандомизацию рабочей нагрузки Big Data кластера и замену JOIN-операций оконными функциями. Оптимизируй это: почему конвейеры аналитической обработки больших данных с Apache Spark замедляются Обычно со...

Недавно мы уже рассматривали выполнение Join-операций в Apache Spark SQL. Сегодня поговорим про особенности потокового соединения в модуле Structured Streaming этого популярного фреймворка аналитики больших данных. Читайте далее, в чем специфика внешних и внутренних соединений потоков Big Data в Apache Spark Structured Streaming, а также как и зачем Inner/Outer Join...