
Как использовать преимущества графических процессоров для Spark-приложений аналитики больших данных и машинного обучения с помощью библиотек RAPIDS. Знакомимся с ускорителем Spark RAPIDS и его возможностями сделать популярный вычислительный движок еще быстрее. Что такое RAPIDS Accelerator для Apache Spark и как он работает Системы Machine Learning, особенно проекты глубокого обучения, уже...

Что такое Delta Sharing, зачем нужен и как устроен этот открытый стандарт, а также как его использовать для централизованного управления доступом к данным в архитектуре Data Mesh. Что такое Delta Sharing и при чем здесь Data Lake Чтобы упростить обмен большими данными между разными компаниями в режиме реального времени и...
Как протестировать работу приложения Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Разбираем особенности ручного и автоматизированного тестирования Flink SQL на уровне отдельных функций, модулей и их интеграционного взаимодействия. Модульное и интеграционное тестирование приложений Apache Flink SQL Тестирование является неотъемлемой частью любого процесса разработки ПО,...
Какие подходы позволяют увеличить емкость СУБД, чтобы повысить объем хранящихся в ней данных и ускорить вычисления. Разбираем тонкости масштабирования распределенной базы данных с массово-параллельной обработкой Greenplum: действия администратора по добавлению новых узлов в кластер. Как увеличить емкость базы данных: 4 подхода к масштабированию Чтобы увеличить емкость СУБД, т.е. объем хранимых...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...

Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей. Что такое Gluten и как он появился в Apache Spark Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и...
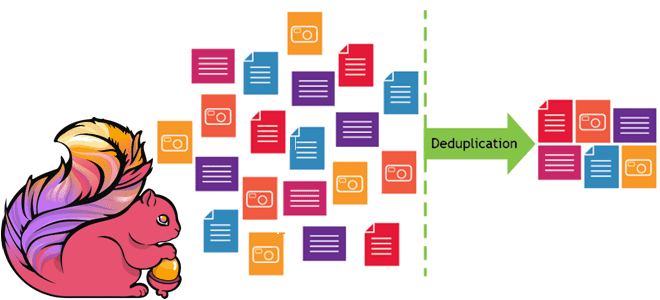
Чем опасны дубли данных при их потоковой обработке и как реализовать дедупликацию в Apache Flink SQL. Смотрим на практическом примере для обучения дата-инженеров и разработчиков распределенных приложений. Потоковая дедупликация данных в Apache Flink SQL Apache Flink можно назвать уникальный фреймворком для разработки распределенных приложений в области Big Data, который унифицирует...
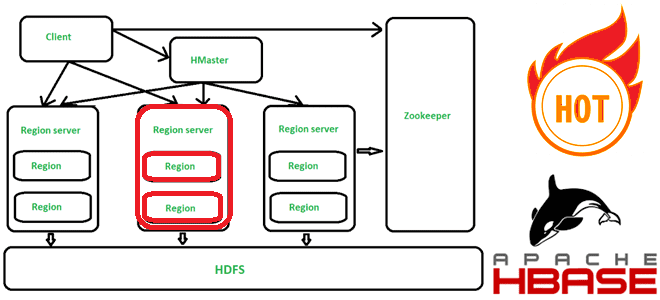
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...

В 7-м релизе Greenplum, о котором мы писали здесь и здесь, вышло много изменений. Одним из них стал целый набор обновленных функций, связанных с партиционированием таблиц. Читайте далее, как Greenplum стал еще на шаг ближе к PostgreSQL и что изменилось в части синтаксиса SQL-запросов. Управление разделами в Greenplum и PostgreSQL...
Для продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим 5 самых известных языков запросов для управления данными графов. Что общего у GraphQL, Gremlin, Cypher, SPARQL и AOL, а также чем они отличаются. GraphQL Языки запросов, используемые для управления данными графов (GQL, Graph Query Language), определяют способ извлечения...
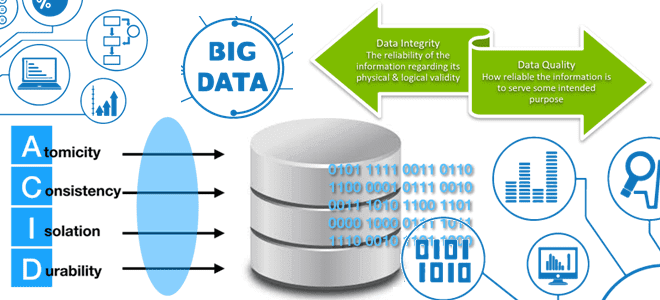
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...
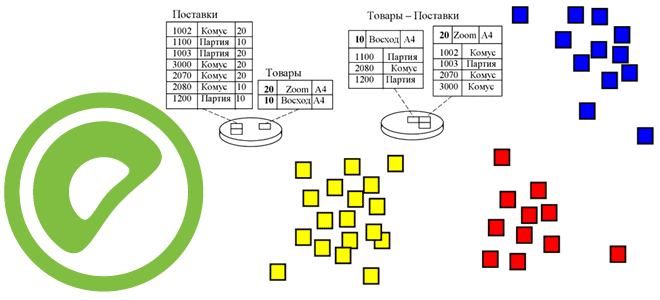
Что означает кластеризация таблиц в PostgreSQL, как это связано с индексацией и очисткой данных, чем полезно применение команды CLUSTER для AO/CO-таблиц в Greenplum 7, а также какой SQL-запрос поможет найти все кластеризованные таблицы в текущей базе данных. Как работает кластеризация таблиц в PostgreSQL Будучи основанной на объектно-реляционной базе данных PostgreSQL,...
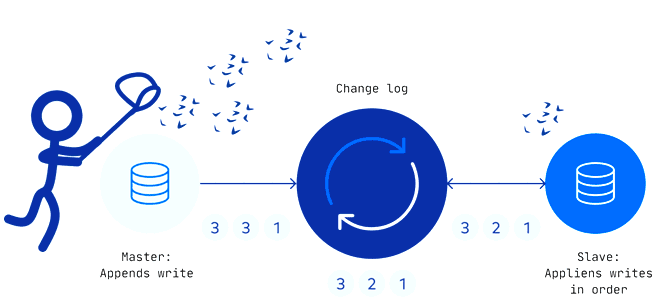
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

Что такое SQL-оператор VACUUM, зачем эта команда нужна в Greenplum и как она работает. Разбираемся с таблицами системного каталога и тонкостями ускорения SQL-запросов в самой популярной MPP-СУБД. Что такое сборка мусора в Greenplum и PostgreSQL Напомним, в объектно-реляционной базе данных PostgreSQL, на которой основана MPP-СУБД Greenplum, о чем мы писали...
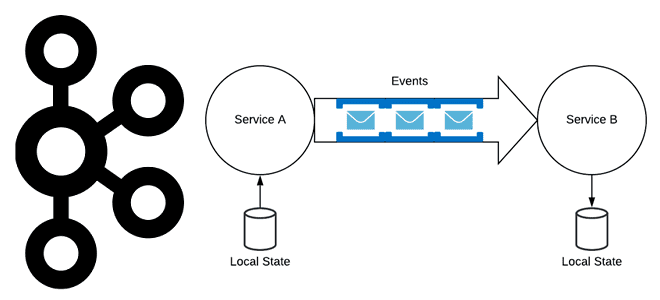
Хотя Apache Kafka часто используется в качестве шины обмена данными в микросервисной архитектуре, о чем мы писали здесь, не стоит воспринимать эту платформу как хранилище событий. В чем разница между событием и сообщением, а также другие тонкости построения микросервисной архитектуры, управляемой событиями. События vs сообщения Событие — это сообщение программной...

Использование СУБД вместо очереди сообщений считается антипаттерном, однако, команда разработки облачной системы организации конвейеров обработки данных Dagster Cloud выбрала PostgreSQL вместо Apache Kafka для регистрации событий. Разбираемся, почему плохой шаблон принес хорошие результаты и что нужно учитывать при выборе технологии. Почему не стоит использовать СУБД вместо очереди сообщений Dagster Cloud...

Мы уже писали про некоторые новинки свежего релиза Greenplum 7 здесь и здесь. Разбираемся, что еще полезного появилось в бета-версии, выпущенной 15 декабря 2022 года. А также рассмотрим, каковы ограничения этого выпуска и почему его пока нельзя использовать в production. Новые функции PostgreSQL Помимо возможности применения команды ALTER TABLE к...

Мы уже рассказывали, что Apache Flink использует Calcite для оптимизации SQL-запросов. Продолжая разбирать эту тему, важную для обучения разработчиков Flink-приложений и дата-инженеров, сегодня рассмотрим, как отследить происхождение отношения на уровне поля, используя методы класса RelMetadataQuery в Calcite. Что такое Apache Calcite и при чем здесь Flink SQL Напомним, Apache Flink...
Недавно мы писали про сравнения технологий потоковой аналитики больших данных и аналитических баз данных реального времени на примере сравнения ksqlDB и Rockset. Продолжая этот разговор про архитектуру данных и приложений, сегодня рассмотрим сходства и отличия потоковых баз данных со stateful-приложениями обработки событий в реальном времени. 2 технологии потоковой обработки: stateful-приложения...
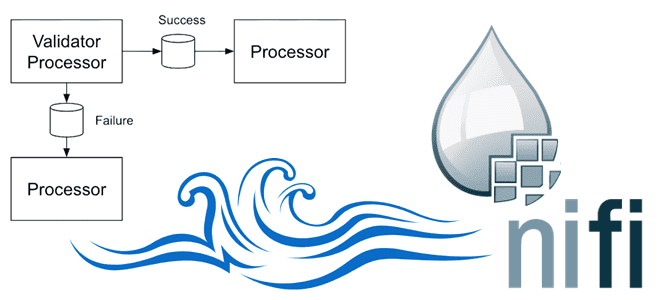
Зачем нужны средства записи и чтения в процессорах Apache NiFi и как они работают: разбираемся на примере QueryRecord, PartitionRecord и RouteText. Сходства и отличия этих процессоров, а также тонкости их использования в задачах дата-инженерии. Процессор QueryRecord в Apache NiFi Напомним, в потоковом ETL-маршрутизаторе Apache NiFi процессоры используются для прослушивания входящих...