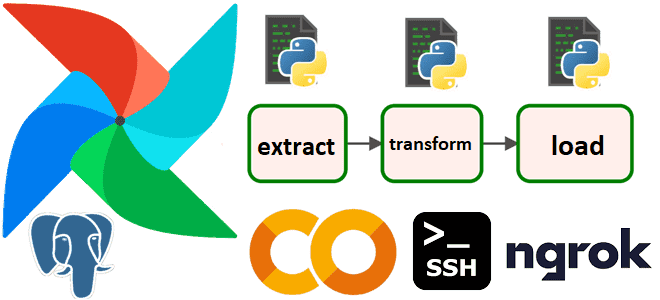
Простой пример объединения нескольких задач, описанных в разных Python-файлах, в единый DAG Apache AirFlow на кейсе выгрузки из реляционной базы PostgreSQL данных о выполненных заказах за последние 100 дней. Разработка и запуск кода в Google Colab. Объединение задач из отдельных Python-файлах в один DAG AirFlow Я уже показывала, как построить...

Как разница между Scala и Java отражается на работе Spark-приложения, почему код на Scala работает быстрее и когда выбирать этот язык программирования для разработки приложений аналитики больших данных. Scala vs Java: ключевые отличия Хотя Apache Spark позволяет разработчику писать код на нескольких языках программирования (Scala, Java, R, Python), сам фреймворк...

13 сентября 2023 года вышел Apache Spark 3.5. Знакомимся с самыми важными новинками свежего релиза: расширения Spark Connect и SQL, поддержка DeepSpeed, улучшения потоковой передачи и свежие UDF-функции Python. ТОП-5 новинок Apache Spark 3.5.0 В Apache Spark 3.5. добавлено много исправлений и улучшений, а также реализованы новые функции. Наиболее интересными...
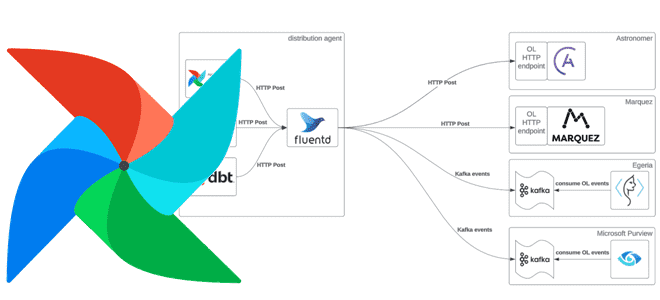
Как Apache AirFlow отслеживает происхождение данных, какова структура спецификации OpenLineage, чем она схожа с OpenAPI, какие инструменты позволяют сформировать эту документацию и чем она полезна. Что такое OpenLineage В области инженерии данных и управления конвейерами их обработки очень важно понятие происхождения данных (Data Lineage). Это концепция отслеживания и визуализации данных...

Сегодня рассмотрим, какие улучшения Apache Spark опубликованы в 2023 году и как подать свое предложение по улучшению самого популярного вычислительного движка в стеке Big Data. Что такое SPIP и как подать свое предложение по улучшению фреймворка В любом продукте помимо ошибок есть также предложения по улучшению. В Apache Spark они...

Чем отличается оркестрация ETL-процессов в Databricks и Apache AirFlow: принципы работы, достоинства и недостатки, а также что выбирать дата-инженеру для решения практических задач. Apache AirFlow vs Spark в Databricks: сходства и отличия Облачная платформа Databricks, основанная на Apache Spark, предлагает пользователям единую среду для создания, запуска и управления различными рабочими...

Как получать результаты обработки данных с помощью Apache Spark, адресуя ИИ бизнес-запросы на английском языке: знакомимся с English SDK от Databricks. Настоящий Low Code с PySpark-AI. English SDK for Apache Spark и PySpark-AI: как это работает Большие языковые модели (LLM, Large Language Model), основанные на генеративных нейросетях, применимы не только...
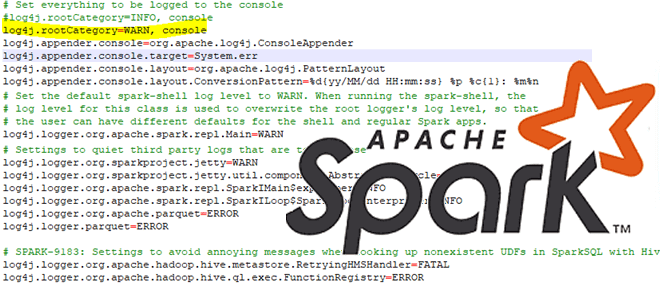
Сегодня рассмотрим особенности отладки PySpark-приложений: как Python-код исполняется в JVM, какие сложности возникают у разработчика при тестировании и исправлении ошибок в программе, написанной локально и запускаемой в кластере, а также как настроить вывод событий в лог-файл. Запуск и выполнение PySpark-кода Хотя Apache Spark и имеет Python API, позволяя писать код...

14 августа 2023 года вышел очередной релиз Apache AirFlow . Разбираем его самые главные новые возможности, улучшения и исправления ошибок: отказ от Python 3.7, задачи установки/демонтажа, встроенная поддержка спецификации OpenLineage, обновления интерфейса, упрощение управления сложными зависимостями и другие фичи Apache AirFlow 2.7. Задачи установки/демонтажа Apache AirFlow 2.7 содержит более 35...
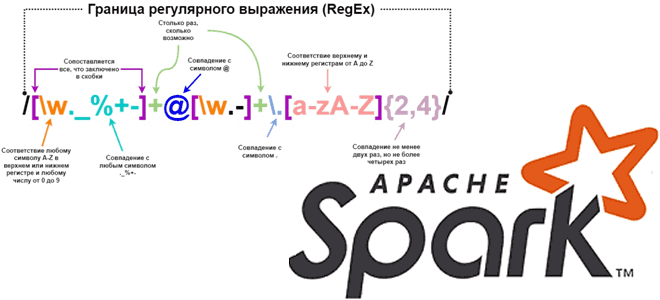
Каждый дата-инженер и аналитик данных активно использует регулярные выражения для поиска значений в тексте по заданному шаблону. Сегодня рассмотрим, как это сделать с функциями regexp_replace(), rlike() и regexp_extract в Apache Spark на примере небольшого PySpark-приложения. Как работает функция regexp_replace() Регулярным выражением называется последовательность символов, задающая шаблон соответствия в тексте. Например,...
Сегодня усложним пример из прошлой статьи с простым ETL-конвейером, который добавлял в базу данных интернет-магазина новые записи о клиентах, сгенерированные с помощью библиотеки Faker. Разбираем, как удалить из PostgreSQL данные об успешно доставленных заказах за прошлый месяц, предварительно сохранив их в JSON-файл с многоуровневой структурой. Пишем и запускаем DAG Apache...
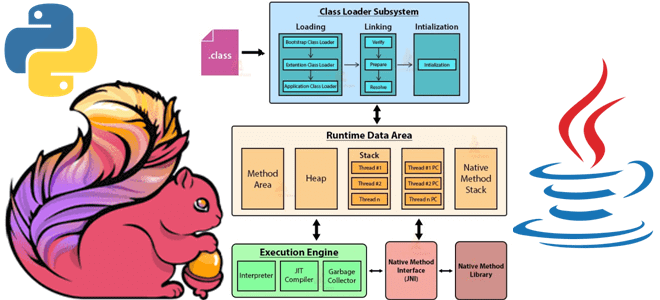
Как и большинство Big Data фреймворков, Apache Flink имеет Python API, позволяя разработчикам высоконагруженных потоковых приложений писать код на этом популярном языке программирования. Однако, Flink-задание выполняется в JVM, поэтому сам фреймворк транслирует Python-код в Java. Разбираемся, в чем особенности этого многоступенчатого процесса. Из Python в Java: как устроен API PyFlink...
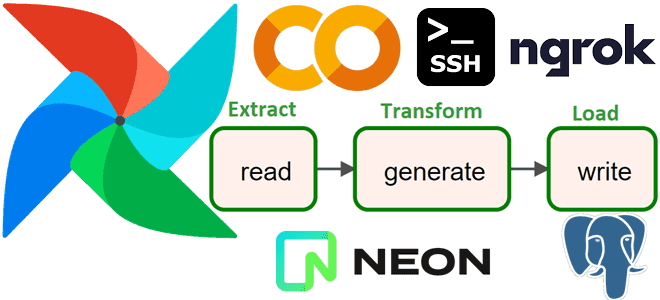
Сегодня реализуем простой ETL-конвейер для реляционной СУБД PostgreSQL, запустив Apache AirFlow в интерактивной среде Google Colab. Пример DAG из 3-х задач: получить количество строк в одной из таблиц БД, сгенерировать новые строки и записать их, не нарушив ограничений уникальности первичного ключа. Постановка задачи Возьмем в качестве примера базу данных для...
Медленно, муторно, небезопасно: что не так с запуском Apache AirFlow в интерактивной среде Google Colab и можно ли с этим смириться. Разбираем на личном опыте. Трудности работы с Apache AirFlow в среде Google Colab О том, что можно настроить AirFlow в Google Cloud Platform, и запускать DAG-файлы из Colab, используя...
В этой статье рассмотрим, как добавить собственное соединение в Apache AirFlow, запустив его в интерактивной среде Colab с помощью Python-кода, и использовать его при отправке результатов выполнения задач DAG в свой чат-бот Телеграм. Постановка задачи: DAG с отправкой данных в Телеграм Недавно я подробно рассказывала, как настроить AirFlow в Google...
Сегодня рассмотрим, как выполнить DAG Apache AirFlow, запустив его в интерактивной среде Colab и получив доступ в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. В качестве примера построим простой конвейер из 5 задач. Запуск Apache AirFlow в Google Colab Чтобы не повторять содержимое...

Сегодня рассмотрим, как запустить Apache AirFlow на мощностях Google в интерактивной среде Colab и войти в веб-GUI этого фреймворка, создав туннель локального хоста на публичный URL с помощью утилиты ngrok. Запуск Apache AirFlow в Google Colab Хотя Google Colab является мощным облачным окружением для запуска и написания Python-кода, выполнение написанных...
Самый простой способ организовать обработку и логирование ошибок в приложении-потребителе, чтобы продолжать считывание из Apache Kafka, даже если продюсер изменил структуру полезной нагрузки сообщения. Публикация данных в Kafka Напомним, Apache Kafka, в отличие от RabbitMQ, не позволяет организовать очередь недоставленных сообщений (DLQ, Dead Letter Queue) средствами самой платформы, о чем мы...

Будучи популярным фреймворком для оркестрации пакетных процессов обработки Apache AirFlow образует вокруг себя целую экосистему. Сегодня познакомимся с некоторыми инструментами, которые пригодятся дата-инженеру для проектирования и отладки конвейеров данных: ADA, Ditto, Amundsen, gusty и Viewflow. Аналитика системных метрик Apache AirFlow с ADA и Amundsen ADA — это микросервис, созданный для...
Как использовать функции обратного вызова для отладки конвейера обработки данных в Apache AirFlow, а также отправки оповещений об ошибках. Полезные примеры регистрации и мониторинга сбоев на уровне задачи и всего DAG с on_failure_callback(). Польза обратных вызовов Apache AirFlow на примере on_failure_callback По мере роста и усложнения конвейеров данных, построенных с...