
Cassandra и HBase считаются наиболее популярными NoSQL-СУБД в мире Big Data. Сегодня мы поговорим, что между ними общего и чем отличаются эти нереляционные базы данных, сравнив их по 10 ключевым параметрам: от архитектуры до инструментальных средств. Что общего между Apache Cassandra и HBase: 5 главных сходств Прежде всего отметим, чем...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Благодаря быстроте, надежности и другим достоинствам Apache Cassandra, эта распределенная NoSQL-СУБД широко применяется во многих Big Data проектах по всему миру. В этой статье мы собрали для вас несколько интересных примеров реального использования Кассандры в 5 ключевых направлениях современного ИТ. Где используется Apache Cassandra: 5 главных приложений c примерами Промышленные...
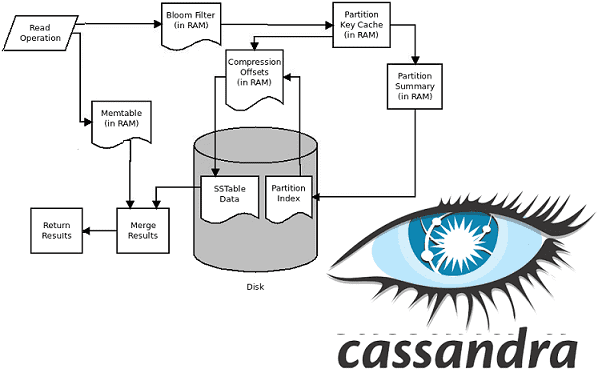
В прошлой статье мы разобрали, как настраиваемые уровни согласованности влияют на скорость работы с данными в Apache Cassandra. Сегодня поговорим, как в этой нереляционной базе данных выполняются операции записи, чтения, уплотнения и удаления. Читайте в нашей статье, что такое memTable, SSTable и Bloom-фильтр, благодаря которым рассматриваемая распределенная NoSQL-СУБД может обработать...
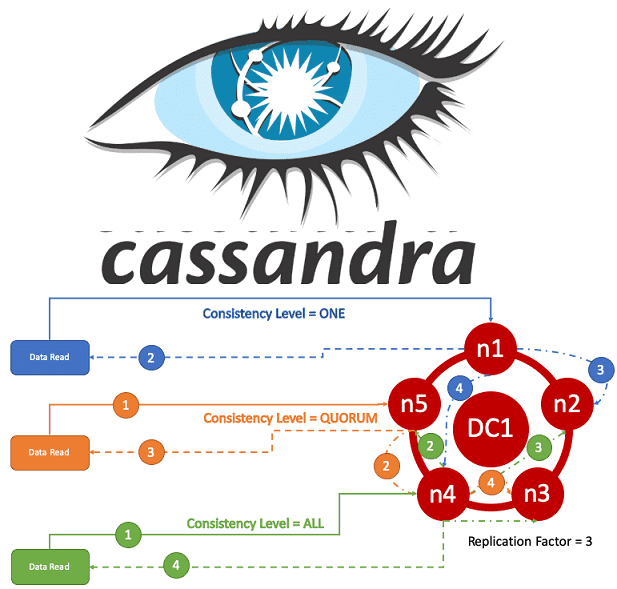
Как мы уже отмечали, одним из преимуществ Кассандры является возможность задания уровня согласованности для операций чтения и записи данных. В этой статье рассмотрим, какие бывают уровни согласованности для этих процессов в Apache Cassandra, и как они влияют на скорость работы распределенной NoSQL-СУБД при ее эксплуатации в реальных Big Data проектах....

Продолжая тему нереляционных хранилищ данных, сегодня мы поговорим о главных плюсах и минусах Apache Cassandra. Читайте в нашем материале, чем хороша эта отказоустойчивая распределенная NoSQL-СУБД и с какими проблемами можно столкнуться при ее использовании в реальном Big Data проекте. Чем хороша Кассандра: 10 ключевых преимуществ Начнем с положительных моментов. Благодаря...

В этой статье мы поговорим про ключевые достоинства и недостатки Apache HBase, а также рассмотрим наиболее интересные примеры практического использования этой нереляционной распределенной СУБД в крупных Big Data проектах. Достоинства и недостатки одной из самых популярных NoSQL СУБД для Big Data Прежде всего, отметим, что Apache HBase и Cassandra считаются...
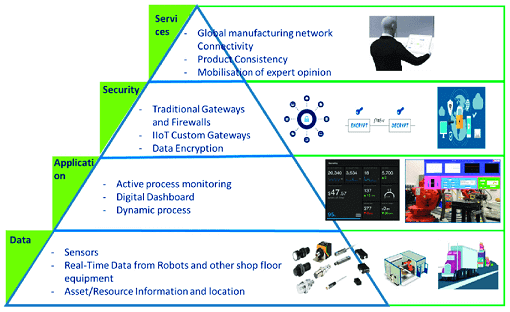
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...
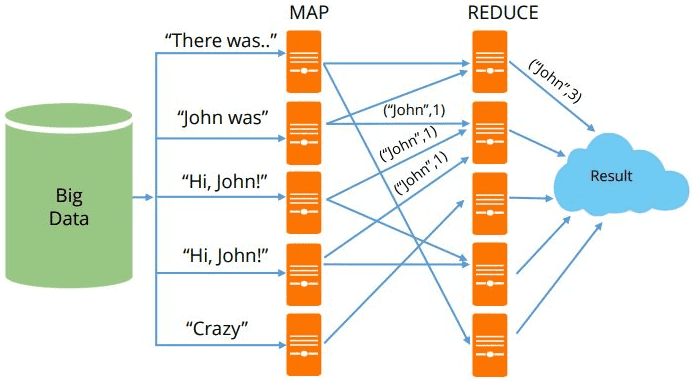
MapReduce можно назвать основой Big Data, т.к. именно данная технология позволяет обрабатывать огромные массивы информации параллельно в распределенных кластерах. Эту вычислительную модель поддерживают множество различных коммерческих и свободных продуктов: Apache Hadoop, Spark, Greenplum, Hive, MongoDB, Phoenix, DryadLINQ и прочие Big Data фреймворки и библиотеки, написанные на разных языках программирования [1]. Сегодня...

Проанализировав сходства и различия пяти самых популярных Big Data фреймворков для распределенных потоковых вычислений (Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza), в этой статье мы сравним их по 10 критериям и отметим, какие именно факторы являются наиболее значимыми для объективного выбора. Сравнительный анализ самых популярных фреймворков потоковой обработки...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Flink часто сравнивают с Apache Spark, другим популярным инструментом потоковой обработки данных. Оба этих распределенных отказоустойчивых фреймворка с открытым исходным кодом используются в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop [1] и других кластерных системах. В этой статье мы поговорим, чем похожи и чем отличаются Флинк и Спарк, а...

Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...

В этой статье мы продолжим говорить про основы Apache Kafka Streams для начинающих и рассмотрим одно из самых важных свойств Кафка – возможность обработки любых данных, накопленных с начала работы Big Data системы. Что такое окна Apache Kafka Streams и зачем они нужны Кафка обеспечивает объективную достоверность накопленных исторических данных...
Как мы уже писали, в Apache Kafka Streams таблица и поток данных – это базовые и взаимозаменяемые понятия. Сегодня поговорим о том, как работать с этими объектами Big Data с помощью внутренних средств Кафка Стримс, используя готовые методы высокоуровневого языка DSL и низкоуровневый API-интерфейс для распределенной обработки потоковых данных в...
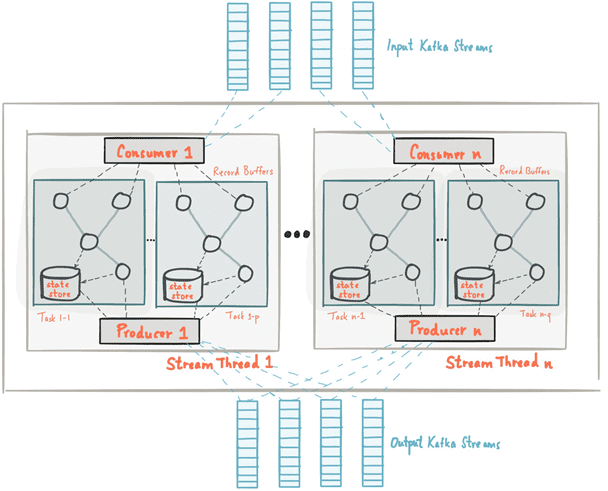
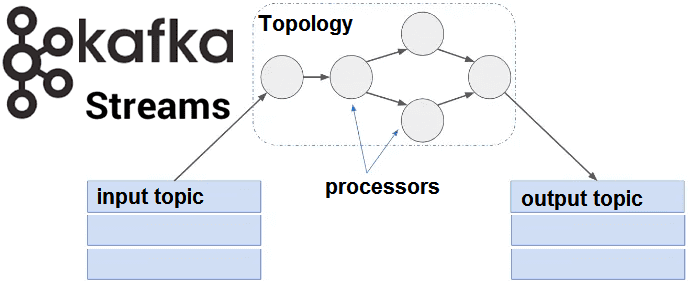
В продолжение темы про основы Apache Kafka Streams для начинающих, сегодня мы поговорим про то, как абстрактные понятия топика (topic), таблицы (table) и потока (stream) позволяют распараллелить обработку информационных потоков. Читайте в нашем новом материале, что такое обработчики потоков Кафка Стримс, как они обрабатывают разделы топиков (topic partition) Kafka и...
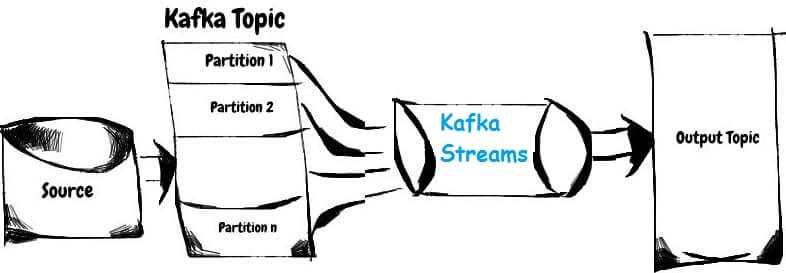
Сегодня мы поговорим про базовые понятия Apache Kafka Streams: потоки, таблицы и топики Кафка. Читайте в нашей статье, как Stream, Table и Topic связаны между собой, чем они похожи, когда таблица становится потоком и почему это обеспечивает эластичность и отказоустойчивость распределенных потоковых приложений Big Data. Что такое таблица, топик и...