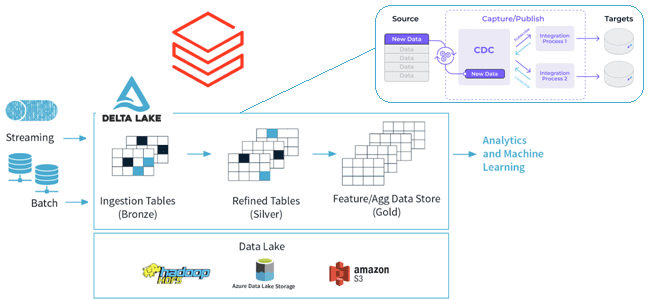
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...
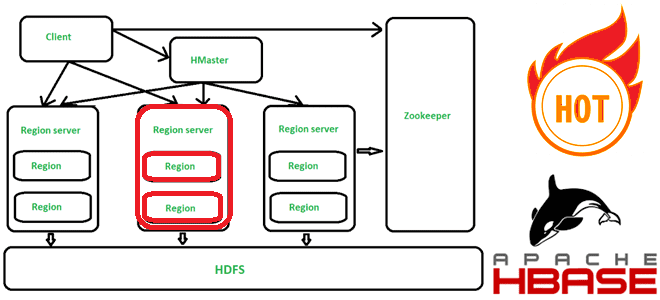
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...
Почему в проектах машинного обучения накапливается технический долг, каковы главные факторы его появления и каким образом MLOps устраняет проблемы, связанные с разработкой, тестированием, развертыванием и сопровождением систем Machine Learning. Скрытый технический долг в ML-системах Технический долг означает дополнительные затраты, возникающие в долгосрочной перспективе, с которыми сталкивается команда, в результате выбора...
Для продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим 5 самых известных языков запросов для управления данными графов. Что общего у GraphQL, Gremlin, Cypher, SPARQL и AOL, а также чем они отличаются. GraphQL Языки запросов, используемые для управления данными графов (GQL, Graph Query Language), определяют способ извлечения...
Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим несколько лучших практик разработки DAG в Apache AirFlow, а также поговорим про операторы, которые обеспечивают повторное использование и настраиваемый запуск задач в конвейере обработки данных. Еще 7 полезных практик работы с Apache AirFlow для дата-инженера В дополнению к тегированию...

Мы уже писали, как ускорить выполнение заданий Spark SQL по чтению данных из JDBC-источников. В продолжение этой важной темы для обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, зачем настраивать опции функции spark.read() и как это сделать наиболее эффективно. Скорость выполнения SQL-запросов и параметры чтения данных из JDBC-источников в Apache...

23 января 2023 года вышел очередной релиз самой популярной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.3.2: готовность протокола KRaft, новый API для метрик, разделитель по умолчанию для записей без ключа, исправления и улучшения, важные для дата-инженера и администратора кластера. Apache Kafka 3.3.2: главные новинки и изменения Минорный...
Сегодня познакомимся с еще одним полезным инструментом Apache NiFi: как использовать предметно-ориентированный язык RecordPath, чтобы получить доступ к полям записи. Смотрим на примере процессора UpdateRecord. Что такое RecordPath в Apache NiFi Apache NiFi имеет множество готовых процессоров, способных принимать, обрабатывать, маршрутизировать, преобразовывать и доставлять данные любого формата и размера благодаря...
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...

28 октября 2022 года вышел мажорный релиз Apache Flink. Что нового в выпуске 1.16.0, который сегодня имеет официальный статус стабильного: зачем нужен SQL Gateway, как улучшен Changelog State Backend, какие DDL-выражения добавлены и зачем внесена поддержка кэширования результата преобразования в PyFlink. Главные обновления Apache Flink 1.16 В версии 1.16 Flink...
Что означает кластеризация таблиц в PostgreSQL, как это связано с индексацией и очисткой данных, чем полезно применение команды CLUSTER для AO/CO-таблиц в Greenplum 7, а также какой SQL-запрос поможет найти все кластеризованные таблицы в текущей базе данных. Как работает кластеризация таблиц в PostgreSQL Будучи основанной на объектно-реляционной базе данных PostgreSQL,...

Чем задание в Spark-приложениях отличается от задачи, зачем нужны этапы и при чем здесь драйверы с исполнителями. Разбираемся с основами разработки в самом популярном движке для распределенных вычислений: ликбез для дата-инженеров. Основные концепции Spark-приложений Приложение Spark — это программа, созданная с помощью Spark API и работающая в совместимом с этим...

Политики хранения, сжатия и очистки данных в топиках Apache Kafka: какие конфигурации нужно настроить, чтобы работать с файлами распределенных логов наиболее эффективно. Ликбез для администратора кластера Kafka и дата-инженера. Хранение данных в Apache Kafka Мы уже писали, что топик в Apache Kafka представляет собой не физическое, а логическое хранение данных....
Как LinkedIn построила масштабируемую инфраструктуру конвейеров машинного обучения, развернув модели TensorFlow на Apache Kafka, Spark и Hadoop YARN. Что такое платформа TonY, как она работает, почему изначально вычислительная парадигма MapReduce не очень хорошо подходила для глубокого обучения и как это исправить через конфигурацию настроек YARN. MLOps и проблемы глубокого обучения...

Зачем маркировать DAG в Apache AirFlow тегами, как их задать и где это пригодится дата-инженеру. А также еще разберем, какими свойствами должен обладать хорошо спроектированный конвейер обработки данных и как они улучшают их качество. Тегирование DAG в Apache AirFlow Когда дата-инженер работает с несколькими конвейерами данных, помнить все зависимости между...

В рамках продвижения наших курсов по машинному обучению и Data Science, сегодня познакомимся с полезным инструментом визуализации данных. Что такое RawGraphs, как он работает и чем полезен для аналитики больших данных: смотрим на практическом примере. Что такое RawGraphs и как это работает Специалисты по Data Science и аналитики данных часто...
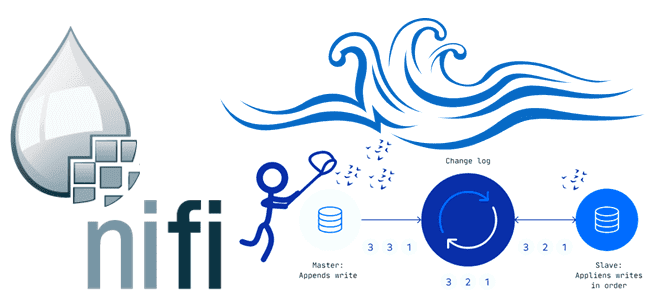
В этой статье для обучения дата-инженеров рассмотрим, как организовать сбор измененных данных из реляционных СУБД, построив CDC-конвейер с помощью Apache NiFi. А также разберем, зачем процессоры этого потокового ETL-маршрутизатора используют технологию веб-хуков. ETL-конвейер для DWH и Data Lake В общем случае сбор данных из реляционных и нереляционных источников и построение...

Интерактивные блокноты Jupyter стали фактически стандартом де-факто для Data Scientist’ов, использующих Python. Многие дата-инженеры и разработчики Spark тоже используют этот легковесный, но очень удобный инструмент. Однако, чтобы применять его для промышленной разработки Big Data приложений, нужно подключить сервер Jupyter к кластеру Spark. Читайте, как это сделать, если кластер Apache Spark...
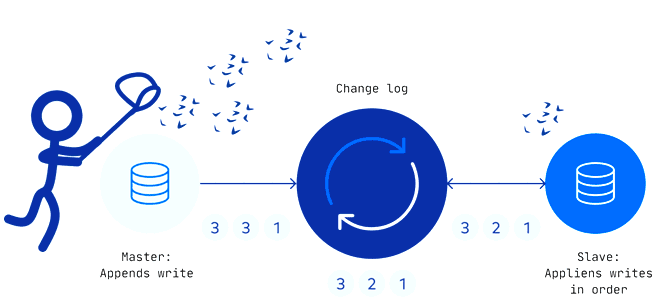
Захват измененных данных считается довольно известным паттерном организации ETL-процессов для корпоративных хранилищ и озер данных. Как реализуется CDC-технология, по каким шаблонам, что их ограничивает и чем опасен дрейф изменений в Change Data Capture. Паттерны и принципы реализации захвата измененных данных Эффективность эксплуатации озера данных зависит от ETL-процессов, поскольку объемы данных...

В этой статье рассмотрим настройку инфраструктуры Kubernetes для потоковой платформы комплексных мобильных приложений на основе Apache Kafka. Что поможет добиться оптимальной масштабируемости приложений-потребителей и высокой доступности всей Big Data системы. Проблемы масштабирования платформы Grab из приложений-потребителей Apache Kafka Grab считается ведущей платформой суперприложений в 8 странах Юго-Восточной Азии, которая предоставляет...