Рассматривая практическое обучение Kafka, сегодня мы поговорим, зачем нужен Zookeeper и можно ли использовать Кафка без этой централизованной службы синхронизации распределенных сервисов. Читайте в нашей статье о роли Zoo в системах обработки больших данных (Big Data) и о том, может ли Apache Kafka эффективно работать без Zookeeper, а также как...

Продолжая разговор о том, как выбрать курсы по Kafka и другим технологиям больших данных (Big Data), сегодня рассмотрим, кому и в каких случаях нужно такое повышение квалификации. В этой статье мы собрали для вас 5 прикладных кейсов по Кафка для ИТ-профессионалов разных специальностей, от системного администратора до Data Engineer’а. А...

В этой статье мы рассмотрим наиболее значимые факторы по выбору образовательных курсов по Apache Kafka и другим технологиям больших данных (Big Data). А также расскажем, как эти условия реализуются в нашем учебном центре, чтобы сделать повышение квалификации ИТ-специалистов и руководителей максимально эффективным. Что важно при выборе курсов по Кафка Проанализировав...

Продолжая разговор про примеры практического использования Apache Cassandra в реальных Big Data проектах, сегодня мы расскажем вам о рекомендательной системе стримингового сервиса Spotify на базе этой нереляционной СУБД в сочетании с другими технологиями больших данных: Kafka, Storm, Crunch и HDFS. Рекомендательная система Spotify: зачем она нужна и что должна делать...

Завершая разговор про ETL-инструменты Big Data и цикл статей об Apache NiFi (ANF), сегодня мы сравним его со StreamSets Data Collector (SDC): чем похожи и чем отличаются эти системы маршрутизации данных. Также рассмотрим, в каких случаях следует выбирать ту или иную платформу и почему. Что общего между Apache NiFi и...
Рассмотрев пакетные ETL-инструменты больших данных, сегодня мы поговорим про потоковые средства загрузки и маршрутизации информации из различных источников: Apache NiFi, Fluentd и StreamSets Data Collector. Читайте в нашей статье про их сходства, различия, достоинства и недостатки. Также мы собрали для вас реальные примеры их практического использования в Big Data системах...
Популярность Apache NiFi в Big Data системах и интернете вещей (Internet of Things, IoT), в т.ч. индустриальном (Industrial Iot, IIoT), обусловлена широкими функциональными возможностями этой платформы по быстрой загрузке и маршрутизации данных любого формата между множеством источников и приемников информации. Также среди ключевых преимуществ NiFi отмечается распределенная архитектура, масштабируемость, наличие...
Продолжая разговор про практическое использование Apache NiFi в системах больших данных (Big Data) и интернета вещей (Internet of Things), сегодня мы рассмотрим, чем обусловлена популярность этой кластерной платформы маршрутизации, преобразования и доставки распределенной информации. Читайте в нашей статье про ключевые преимущества Apache NiFi в контексте прикладного использования этого инструмента. 10...

В прошлый раз мы рассмотрели пример прототипа IIoT-системы на основе одноплатного мини-компьютера Raspberry Pi, брокере обмена сообщениями Mosquitto и платформе маршрутизации данных Apache NiFi. Сегодня мы покажем, что этот инструмент преобразования и доставки данных из множества сторонних систем может применяться не только в IoT-решениях. Читайте в нашей статье про 5...
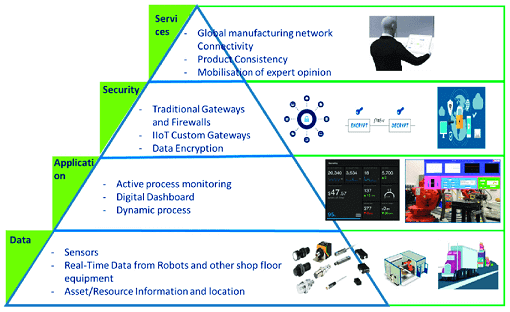
Мы уже рассматривали типовую архитектуру систем Internet of Things (IoT). Сегодня поговорим подробнее про уровневую модель передачи и обработки данных от конечных устройств до облачных IoT-платформ, а также приведем примеры наиболее популярных средств обеспечения каждого из уровней этой сложной архитектуры Industrial Internet of Things, включая инструменты Big Data. Многоуровневый IIoT:...

В этой статье мы рассмотрим, чем похожи и чем отличаются 5 самых популярных инструментов распределенной обработки потоков Big Data: Apache Kafka Streams, Spark Streaming, Flink, Storm и Samza, а также поговорим про наиболее значимые факторы выбора между этими программными средствами. 5 общих характеристик распределенных Big Data фреймворков потоковой обработки Прежде...

Apache Samza часто сравнивают с другими Big Data фреймворками распределенных потоковых вычислений в реальном времени (Real Time, RT): Kafka Streams, Spark Streaming, Flink и Storm. Apache Spark и Flink обладают практически одинаковым набором функциональных возможностей и компонентов, поэтому их можно сравнивать между собой более-менее объективно. Apache Samza является более простой...

Apache Storm (Сторм, Шторм) часто употребляется в контексте других BigData инструментов для распределенных потоковых вычислений в реальном времени (Real Time, RT): Spark Streaming, Kafka Streams, Flink и Samza. Однако, если Apache Spark и Flink по функциональным возможностям и составу компонентов еще могут конкурировать между собой, то сравнивать с ними Шторм,...

Проанализировав сходства и различия Apache Kafka Streams и Spark Streaming, можно сделать некоторые выводы относительно выбора того или иного решения в качестве основного инструмента потоковой обработки Big Data. В этой статье мы собрали для вас аргументы в пользу Кафка Стримс и Спарк Стриминг в конкретных ситуациях, а также нашли некоторые...

Сегодня мы рассмотрим популярные Big Data инструменты обработки потоковых данных: Apache Kafka Streams и Spark Streaming: чем они похожи и чем отличаются. Стоит сказать, что Спарк Стриминг и Кафка Стримс – возможно, наиболее популярные, но не единственные средства обработки информационных потоков Big Data. Для этой цели существует еще множество альтернатив,...

В этой статье мы продолжим говорить про основы Apache Kafka Streams для начинающих и рассмотрим одно из самых важных свойств Кафка – возможность обработки любых данных, накопленных с начала работы Big Data системы. Что такое окна Apache Kafka Streams и зачем они нужны Кафка обеспечивает объективную достоверность накопленных исторических данных...
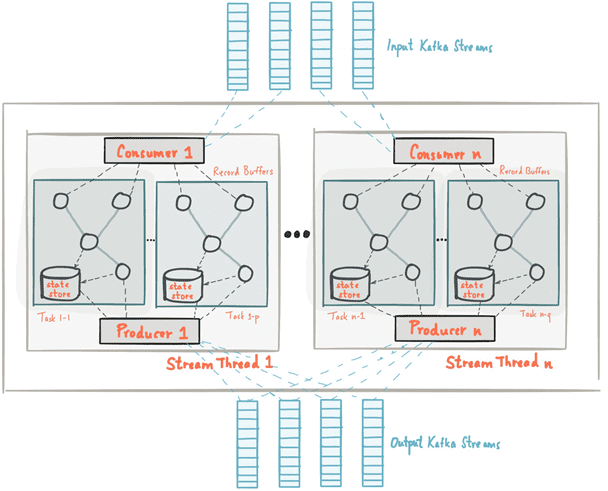
Как мы уже писали, в Apache Kafka Streams таблица и поток данных – это базовые и взаимозаменяемые понятия. Сегодня поговорим о том, как работать с этими объектами Big Data с помощью внутренних средств Кафка Стримс, используя готовые методы высокоуровневого языка DSL и низкоуровневый API-интерфейс для распределенной обработки потоковых данных в...
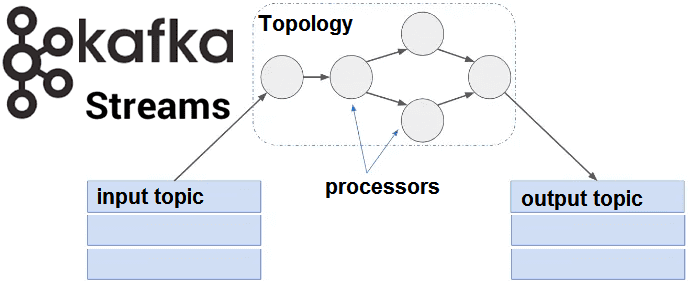
В продолжение темы про основы Apache Kafka Streams для начинающих, сегодня мы поговорим про то, как абстрактные понятия топика (topic), таблицы (table) и потока (stream) позволяют распараллелить обработку информационных потоков. Читайте в нашем новом материале, что такое обработчики потоков Кафка Стримс, как они обрабатывают разделы топиков (topic partition) Kafka и...
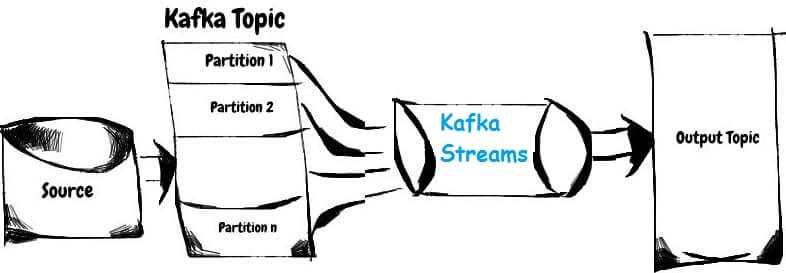
Сегодня мы поговорим про базовые понятия Apache Kafka Streams: потоки, таблицы и топики Кафка. Читайте в нашей статье, как Stream, Table и Topic связаны между собой, чем они похожи, когда таблица становится потоком и почему это обеспечивает эластичность и отказоустойчивость распределенных потоковых приложений Big Data. Что такое таблица, топик и...
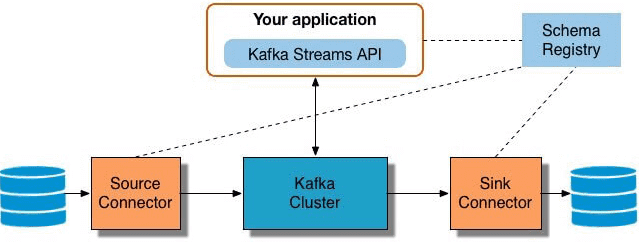
Мы уже рассказывали про Apache Kafka Streams API. В продолжение этой темы, сегодня отметим ключевые преимущества этой технологии, особенно важные для DevOps-инженера и разработчика Big Data систем, а также поговорим про некоторые недостатки и возможные альтернативы Кафка Стримс API. 5 главных достоинств Apache Kafka Streams API Для DevOps-инженера Big Data...