
Cloudera Impala – далеко не единственное SQL-решение для быстрой обработки больших данных (Big Data), хранящихся в среде Hadoop. C Impala часто сравнивают Apache Hive, однако они существенно отличаются в плане прикладного использования, как мы уже показали здесь. Гораздо ближе к Impala с точки зрения вычислительной модели и сценариев использования (use...
Завершая сравнение SQL-инструментов для больших данных (Big Data), хранящихся в среде Hadoop, сегодня мы рассмотрим аргументы в пользу Apache Hive и Cloudera Impala – когда стоит выбирать ту или иную систему и почему. Также в этой статье мы собрали для вас несколько практических примеров реального использования Импала и Хайв в...

Продолжая тему SQL-on-Hadoop, сегодня мы рассмотрим вопросы обеспечения информационной безопасности в Apache Hive и Cloudera Impala. Читайте в нашем материале, что такое RBAC, в чем специфика cybersecurity больших данных в экосистеме Hadoop и какие средства помогут защитить Big Data при работе с Hive и Impala. Что такое RBAC для SQL-on-Hadoop...

Мы уже разобрали, что общего между Apache Hive и Cloudera Impala. В этой статье рассмотрим работу этих систем с точки зрения программиста, а также поговорим про язык HiveQL. Читайте в сегодняшнем материале, как эти системы выполняют SQL-запросы для аналитики больших данных (Big Data), хранящихся в кластере Hadoop. Что такое HiveQL,...

В прошлой статье мы рассмотрели основные возможности и ключевые характеристики Apache Hive и Cloudera Impala. Сегодня подробнее поговорим про то, что между ними общего и чем отличаются друг от друга эти SQL-инструменты для обработки больших данных (Big Data), хранящихся в кластере Hadoop. Что общего между Apache Hive и Cloudera Impala:...

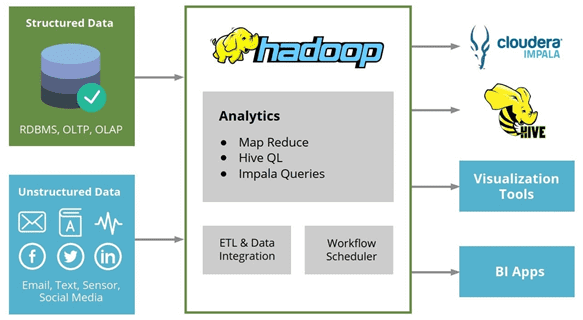
Сегодня мы рассмотрим Apache Hive и Cloudera Impala – аналитические SQL-средства для работы с данными, хранящимися в экосистеме Apache Hadoop и других Big Data хранилищах: HDFS, HBase, Amazon S3. Читайте в нашей статье, что такое Hive и Impala, где они используются и почему они не заменяют, а дополняют друг друга....