
Apache NiFi – это простая и мощная система для обработки и распределения больших данных в потоковом режиме, которая отлично справляется с огромными объемами и скоростями, оперируя с сотнями гигабайт и даже терабайтами информации. Однако, на практике при работе с этой Big Data платформой можно столкнуться с проблемой ввода-вывода (IOPS, Input-Output...

Сегодня мы продолжим разговор о событийно-процессной архитектуре Big Data систем на примере использования Apache Kafka в The New York Times. Читайте далее, как одно из самых известных американских СМИ с более чем 160-летней историей хранит в Apache Kafka все свои статьи и с помощью API Kafka Streams публикует контент в...

В этой статье мы поговорим про возможность нехарактерного использования Apache Kafka: не как распределенной стримминговой платформы или брокера сообщений, а в виде базы данных. Читайте далее, как Apache Kafka дополняет другие СУБД, не заменяя их полностью, почему такой вариант использования возможен в Big Data и когда он не совсем корректен....

Недавно мы рассказывали, что аналитика больших данных с помощью технологий Big Data – это необязательно удел только крупных корпораций. В этой статье мы рассмотрим реальный бизнес-кейс, как извлечь выгоду из накопленных данных о своих пользователях, применяя для этого возможности NoSQL-СУБД Elasticsearch для полнотекстового поиска по полуструктурированным данным и веб-интерфейс визуализации...
Сегодня рассмотрим облачные сервисы и платформы ELK-стека, которые позволяют использовать все функциональные преимущества Elasticsearch с Kibana без развертывания собcтвенной ИТ-инфраструктуры (on-demand), интегрируя их с другими облачными приложениями. Читайте в нашей статье, что такое Elastic Cloud Enterprise и чем это отличается от Amazon Elasticsearch Service, Open Distro и других cloud-решений. Такие...

В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...

Продолжая разговор про интеграцию Elasticsearch с Кафка, сегодня мы рассмотрим, с какими ошибками можно столкнуться при практическом использовании Apache Kafka Connect. Также рассмотрим, как Kafka Connect поддерживает обработку ошибок и какие параметры нужно настроить для непрерывной передачи данных или ее остановки в случае сбоя. 2 варианта обработки ошибок в Kafka...

Сегодня поговорим, как связать Elasticsearch с Apache Kafka: рассмотрим, зачем нужны коннекторы, когда их следует использовать и какие особенности популярных в Big Data форматов JSON и AVRO стоит при этом учитывать. Также читайте в нашей статье, что такое Logstash Shipper, чем он отличается от FileBeat и при чем тут Kafka...

В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data....

Вчера мы рассказывали про самые известные утечки Big Data с открытых серверов Elasticsearch (ES). Сегодня рассмотрим, как предупредить подобные инциденты и надежно защитить свои большие данные. Читайте в нашей статье про основные security-функции ELK-стека: какую безопасность они обеспечивают и в чем здесь подвох. Несколько cybersecurity-решений для ES под разными лицензиями...

Продолжая разговор про Elastic Stack, сегодня мы рассмотрим проблемы cybersecurity в Elasticsearch: разберем самые известные утечки данных за последнюю пару лет и поговорим, кто и как обнаруживает подобные инциденты. Читайте в нашей статье, какие средства используют «белые хакеры» для поиска уязвимостей в Big Data системах и что общего между Росгвардией...

Сегодня рассмотрим основные преимущества и недостатки ELK-стека. Читайте в этой статье, чем хороши Elasticsearch с Logsatsh и Kibana, а также каковы их основные недостатки и ограничения для использования в реальных Big Data проектах. Также мы собрали для вас несколько практических примеров, где и как используется Elasticsearch в интернет-магазинах, банках и...
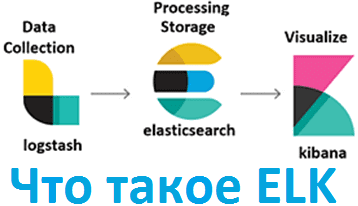
В этой статье рассмотрим ELK-инфраструктуру: разберем, зачем поисковый движок Elasticsearch использует сборщик логов Logstash и при чем здесь визуальный интерфейс Kibana. Также поговорим, в каких Big Data проектах используются эти системы и для чего. Зачем вам Elasticsearch: полнотекстовый поиск по Big Data Чтобы определить, почему деньги пропали с банковского счета или...