
Несмотря на почти 20-летнюю историю термина «DevOps», даже в ИТ-среде до сих пор есть мнение, что все рабочие задачи этого девопс-инженера может выполнить рядовой системный администратор. Почему это не так и как обстоят дела с администрированием Big Data систем, читайте в нашей сегодняшней статье. Критерии и источники данных для сравнения...

Рассматривая облачные сервисы для Big Data проектов, мы уже говорили про SLA (Service Level Agreement, соглашение об уровне предоставления услуг) и упоминали показатели измерения эксплуатационной надежности в материале про эволюцию Agile-подходов. Читайте в нашей сегодняшней статье, как эти SRE-метрики помогают DevOps-инженерам и администраторам обосновать экономическую необходимость затрат на средства дополнительной защиты Big...
Большие данные требуют огромной гибкости и большой надежности – сегодня мы расскажем, что кто обеспечивает бесперебойную работу Google и других ИТ-гигантов и что нас ждет после DevOps. Читайте в нашей новой статье, как развиваются Agile-подходы к организации процессов разработки и эксплуатации Big Data систем и сколько это стоит. Что такое...

При всех достоинствах DevOps, этот, особенно популярный сейчас, подход к организации процессов разработки и эксплуатации ПО, не лишен недостатков. Сегодня мы поговорим о том, когда лучше обойтись без девопс и как его внедрить, если он не очень подходит, а очень хочется. Также расскажем, почему DevOps – не панацея и какие...

Ранее мы уже писали про DataOps- и DevOps-инженеров, а также про администраторов больших данных. Продолжая тему гибкого управления проектами (Agile) для повышения эффективности и ускорения бизнес-процессов, сегодня поговорим о том, какие еще специалисты нужны для успешного Big Data проекта. Профильные категории и процессы Big Data проекта Независимо от конечной цели...

Мы уже писали о происхождении термина DataOps, а также про методы и средства реализации этой концепции непрерывной интеграции данных между процессами, командами и системами в рамках data-driven company. Продолжая тему развития Agile-подходов в мире больших данных, сегодня рассмотрим, чем отличаются сферы ответственности DataOps- и DevOps-инженеров и почему оба этих специалиста...

DataOps (DATA Operations, датаопс), по аналогии с DevOps (DEVelopment Operations, девопс) — это концепция и набор практик непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления или отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на...

Администратор – обязательная роль в Big Data проекте, даже если он построен по принципу микросервисной архитектуры, когда за создание и развертывание каждого модуля отвечает отдельный DevOps-инженер. Задачи постоянной оценки производительности и поддержки ИТ-инфраструктуры актуальны как для новоявленных стартапов, работающих по современным Agile-принципам, так и для крупного бизнеса (enterprise). В этой...
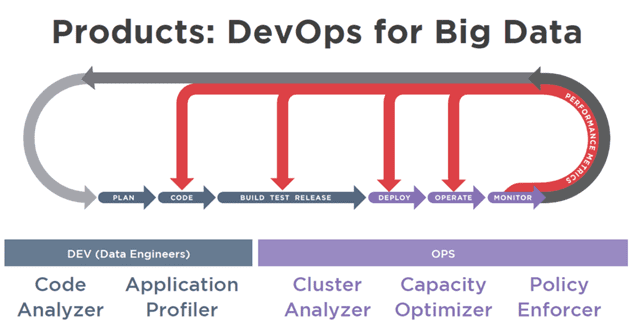
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного...