
Мы уже рассказывали про уязвимости систем Internet of Things и причинах их возникновения. Сегодня поговорим о том, как снизить риски нарушения информационной безопасности интернета вещей, и кто отвечает за мероприятия по защите smart-устройств от взломов и IoT-платформ от утечек Big Data. Способы обеспечения информационной безопасности интернета вещей В соответствии с...

Продолжая тему информационной безопасности в мире Big Data, сегодня мы поговорим об проблемах защиты данных в системах Internet of Things. Читайте в нашем материале, как вредоносные ботнеты взламывают бытовые smart-устройства, с чем сталкивается промышленный интернет вещей при обеспечении безопасности, а также какие компоненты IoT/Big Data систем наиболее уязвимы и почему....
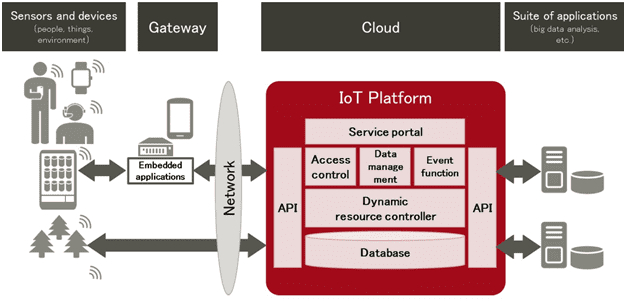
Рассматривая архитектуру и принципы работы IoT-систем, мы уже упоминали, что наиболее интеллектуальная часть работы по анализу данных выполняется в облаке с помощью специальных средств Big Data, объединенных в общую платформу. Сегодня поговорим о функциях IoT-платформ и технологиях, на которых основаны эти облачные решения. Также мы подготовили для вас краткий обзор...
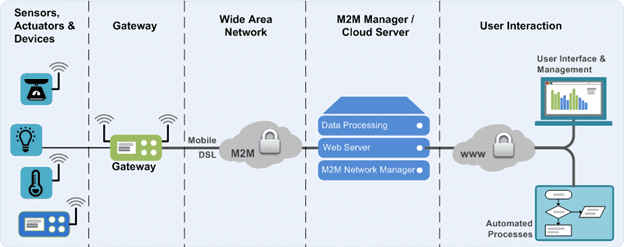
Мы уже немного рассказывали об архитектуре IoT-систем в статье про промышленный интернет вещей. Сегодня поговорим подробнее про аппаратные и программные компоненты Internet of Things и IIoT, а также разберем, как малые данные со множества датчиков преобразуются в Big Data. Архитектура IoT-системы Типовая архитектура IIoT-систем состоит из следующих 3-х уровней [1]:...
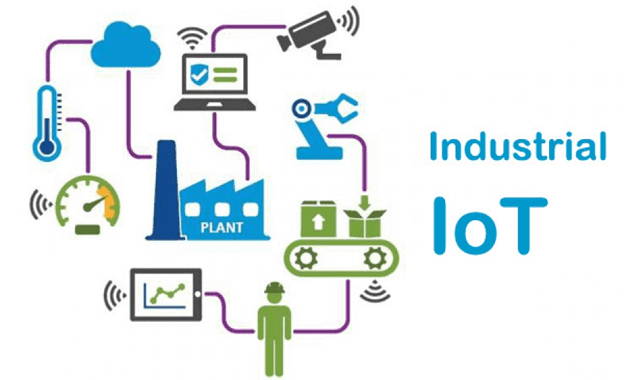
Мы уже рассказывали, как интернет вещей (Internet of Things, IoT) вместе с технологиями Big Data и машинного обучения (Machine Learning) используются в нефтегазовой, транспортной, сельскохозяйственной и машиностроительных отраслях. Сегодня поговорим подробнее про промышленный IoT (Industrial Internet of Things, IIoT) на примерах его применения в тяжелом машиностроении и рассмотрим, почему индустриальный...

В результате цифровой трансформации «традиционного предприятия» должна получиться идеальная организация, работающая на основе данных, в т.ч. больших (Big Data). Сегодня мы поговорим, что такое Data-Driven Company, чем она отличается и как ей стать: читайте в нашей статье, какие инструменты Big Data, методы Agile и инженерные подходы системного анализа применяются для...

Продолжая тему «умного» города (data-driven city), сегодня мы собрали для вас 5 практических примеров, как в крупнейших мегаполисах по всему миру интернет вещей и большие данные с датчиков, проездных билетов и дорожных камер помогают бороться с пробками и улучшать состояние дорог, повышая уровень их безопасности и удобства использования. Internet of...

Big Data – это основа бизнеса страховых компаний, работа которых полностью основана на информации: статистике, сведениях о клиентах, страховых случаях и вероятностях их наступления, а также финансовой оценке всех этих данных. Читайте в нашей сегодняшней статье, как «большая тройка» современных информационных технологий (большие данные, машинное обучение и интернет вещей) увеличивают...

Ранее мы уже писали про DataOps- и DevOps-инженеров, а также про администраторов больших данных. Продолжая тему гибкого управления проектами (Agile) для повышения эффективности и ускорения бизнес-процессов, сегодня поговорим о том, какие еще специалисты нужны для успешного Big Data проекта. Профильные категории и процессы Big Data проекта Независимо от конечной цели...

Мы уже писали о происхождении термина DataOps, а также про методы и средства реализации этой концепции непрерывной интеграции данных между процессами, командами и системами в рамках data-driven company. Продолжая тему развития Agile-подходов в мире больших данных, сегодня рассмотрим, чем отличаются сферы ответственности DataOps- и DevOps-инженеров и почему оба этих специалиста...

DataOps (DATA Operations, датаопс), по аналогии с DevOps (DEVelopment Operations, девопс) — это концепция и набор практик непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления или отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на...

Администратор – обязательная роль в Big Data проекте, даже если он построен по принципу микросервисной архитектуры, когда за создание и развертывание каждого модуля отвечает отдельный DevOps-инженер. Задачи постоянной оценки производительности и поддержки ИТ-инфраструктуры актуальны как для новоявленных стартапов, работающих по современным Agile-принципам, так и для крупного бизнеса (enterprise). В этой...
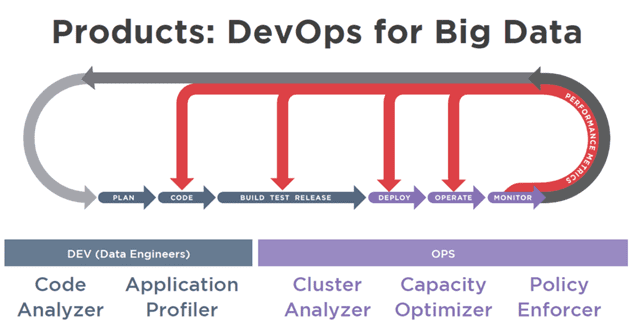
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного...
Пока Agile (эджайл) из методологии разработки программного обеспечения становится настоящей философией ведения бизнеса, мы разберем, какие именно принципы этого подхода используются в каждой системе больших данных и почему любой Big Data проект успешно реализуется с помощью этих идей. Что такое Agile: краткий ликбез Изначально термин Agile относился к подходам и...

Чтобы сохранить большие данные от утечек, чиновники придумывают различные законы, а разработчики чинят уязвимости в Big Data системах. Продолжая разговор про информационную безопасность больших данных, сегодня мы подготовили для вас статью про технические средства защиты кластера Apache Hadoop. Возможные угрозы для кластера Big Data и средства их предотвращения В реальности...

Мы уже рассказывали о наиболее крупных утечках персональных данных за последние несколько лет и о том, как эту проблему пытаются решить разные страны на законодательном уровне. Сегодня, продолжая тему информационной безопасности Big Data, поговорим об основных уязвимостях главного инфраструктурного решения для больших данных - Apache Hadoop. Некоторые инциденты нарушения безопасности...

Среди угроз несанкционированного использования Big Data наиболее опасны утечки персональных данных. Когда сведения о личностях сотен тысяч людей по всему миру в очередной раз «утекли» в открытый доступ, компании снова задумываются о защите информации. В этой статье мы расскажем о наиболее крупных утечках персональных данных за последние несколько лет, а...

Цифровизация различных прикладных отраслей продолжается - сегодня мы нашли для вас интересные кейсы, как большие данные, машинное обучение и интернет вещей используется в жилой и коммерческой недвижимости. Чем Big Data, Machine Learning и Internet Of Things (IoT) полезны строителям и риелторам, и каким образом внедрение этих технологий поможет потребителям. Big...

Цифровизация возможна не только на предприятиях. Цифровая трансформация настигает даже города, чтобы сделать их более удобными для жителей и менее вредными для планеты. Сегодня мы подготовили для вас 8 интересных примеров по 4 разным направлениям об использовании больших данных (Big Data), машинного обучения (Machine Learning) и интернета вещей (Internet of...

Проанализировав предложения крупных PaaS/IaaS-провайдеров по развертыванию облачного кластера, сегодня мы сравним 4 наиболее популярных дистрибутива Hadoop от компаний Cloudera, HortonWorks, MapR и ArenaData, которые используются при развертывании локальной инфраструктуры для проектов Big Data. Как мы уже отмечали, эти дистрибутивы распространяются бесплатно, но поддерживаются на коммерческой основе. Некоторые отличия популярных дистрибутивов...