 1092
1092 
Содержание
Вчера мы рассказывали про нововведения в Apache Spark 3.0 и упомянули про улучшения в SparkR. Сегодня рассмотрим, почему в новой версии фреймворка вызов пользовательских функций стал быстрее в 40 раз и какие еще проблемы работы с R были решены в этом релизе.
Что не так со SparkR: десериализация и особенности структур данных
Одним из достоинств Apache Spark считается богатый API: помимо Java, Scala и Python, этот Big Data фреймворк также позволяет работать с языком R, который считается весьма популярным в области анализа данных, о чем мы писали здесь. Однако, на практике при работе со SparkR можно было столкнуться со следующими трудностями [1]:
- неоднозначность типовых структурах данных. В языке R frame – это объект в оперативной памяти (in-memory) в виде списка векторов одинаковой длины. Каждый столбец содержит значения одной переменной, а каждая строка – одно наблюдение. Таким образом, в классическом R data.frame – это список переменных с одинаковым количеством строк с уникальными именами строк, матричная структура, столбцы которой могут быть разных типов (числовые, логические, факторные, символьные и пр.) [2]. В свою очередь, SparkDataFrame – это представление (view) Dataset, который является коллекцией сериализованных JVM-объектов. Сам Dataset, то есть исходный набор инструкций, полученный в результате перевода R-кода в Spark, с помощью SparkSQL форматируется так, чтобы имитировать таблицу.
- локальность данных. Если изначально Spark разрабатывался именно как распределенная система, то R – как локальная. Поэтому, например, из-за своей распределенной природы и по причине передачи данных между JVM-процессами SparkR не может работать с объектами на уровне отдельных ячеек. Таким образом, несмотря на то, что Apache Spark реализует строковую парадигму, нельзя получить доступ к конкретным строкам SparkDataFrame. Это означает, что можно выполнять только столбцовые операции с исходным DataFrame: т.е., требуется пройти по всему SparkDataFrame, применяя изменения к тому, что в R было бы эквивалентом вектора. Поэтому возникает необходимость применять неудобные обходные пути для выполнения простых типовых задач, таких как заполнение пустых значений. Распределенная природа и секционирование данных в Spark, приводят к разным результатам в виде подмножества данных при работе со SparkDataFrame в зависимости от скорости завершения вычислительных процессов на кластере и план выполнения запросов. Это также обусловливает разницу в некоторых вычислительных методах в SparkR и классическом R. В частности, функция apply(), реализация метода k-средних.
- Сложность отладки. Когда локальный R-код преобразуется в SparkDataFrame, выполняется целая последовательность действий:
- R открывает порт и ждет подключений, которые устанавливает SparkR;
- Каждый вызов SparkR отправляет сериализованные данные по локальному подключению и ожидает ответа;
- Обработка запросов происходит в backend;
- R отправляет JVM сериализованные двоичные данные, при этом типы данных преобразуются в списки, а методы и аргументы сериализуются и отправляются в backend. Ищется соответствующий метод и выполняется.
Таким образом, ошибка может случиться при обработке начального R-кода, сериализации данных для SparkR, преобразовании для JVM, перемещения данных от драйвера к исполнителям, выполнении фактического Spark-задания (job) или обработке результатов.
Для решения части этих проблем в Apache Spark 3.0 была введена векторизация, о которой мы поговорим далее.
Векторизация в Apache Spark 3.0
Итак, когда SparkR не требует взаимодействия с процессом R, производительность практически идентична API других языков: Scala, Java и Python. Значительное снижение производительности происходит, когда задания SparkR взаимодействуют с собственными функциями R или типами данных. В частности, когда требуется выполнить собственную функцию R или преобразовать ее в собственные типы R или наоборот, производительность сильно падает из-за операций сериализации и десериализации данных. Например, следующие методы заметно снижают производительность в связи с преобразованием данных из JVM со стороны драйвера R [3]:
- createDataFrame();
- collect();
- dapply();
- dapplyCollect();
- gapply();
- gapplyCollect().
К примеру, String в Java становится символом в R. Поэтому при преобразовании между исполнителями JVM и R нужно сериализовать и десериализовать как собственные функции R, так и сами данные, что требует дополнительных накладных расходов. Поскольку вычисления в SparkR DataFrame распределяются по всем узлам кластера, то необходимо также организовать обмен данными с помощью сокетов между JVM и драйвером/исполнителями R. При этом операции сериализации и десериализации, а также передачи данных выполняются построчно между JVM и R с неэффективным форматом кодирования, который не принимает во внимание современный дизайн ЦП, такой как конвейерная обработка. Поэтому в Apache Spark 3.0 в SparkR реализована новая векторизация за счет использования Apache Arrow для обмена данными напрямую между JVM и драйвером/исполнителями R с минимальными затратами на сериализацию и десериализацию.
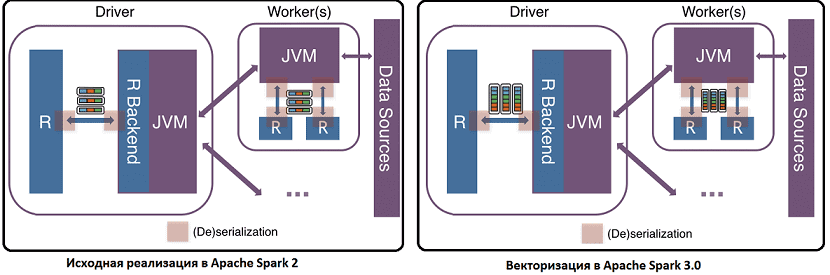
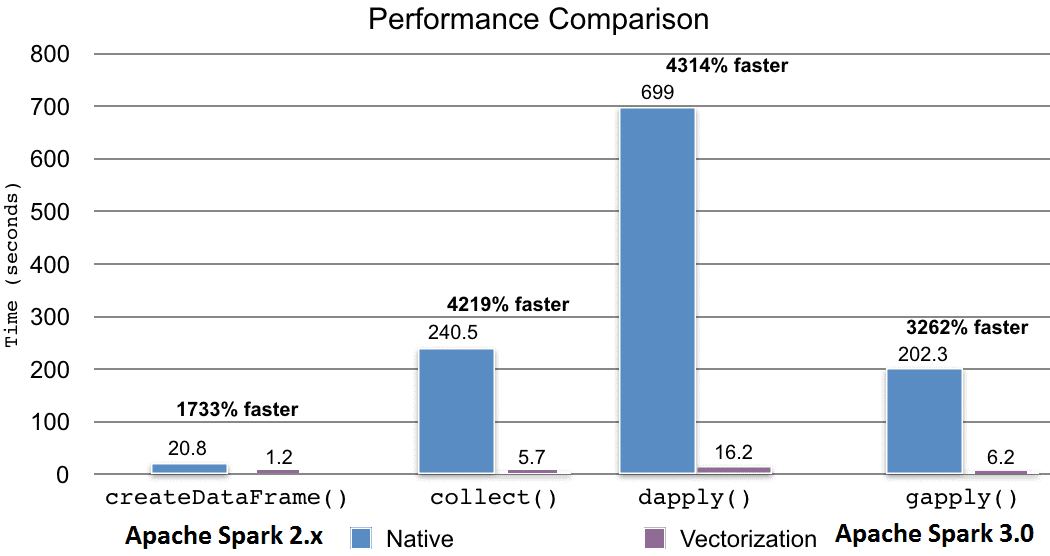
Вместо построчных сериализаций и десериализаций с использованием неэффективного формата между JVM и R, новая векторизация использует Apache Arrow, чтобы обеспечить конвейерную обработку и множественные данные с одной инструкцией (SIMD) и эффективным столбцовым форматом. Примечательно, что новые векторизованные API-интерфейсы SparkR не включены по умолчанию в версии 3.0. Их можно включить самостоятельно, установив для свойства spark.sql.execution.arrow.sparkr.enabled значение TRUE. Справедливости ради стоит отметить, что векторизация методов dapplyCollect() и gapplyCollect() еще не реализована, вместо них рекомендуется использовать dapply() и gapply(). Бенчмаркинговый тест, проведенный компанией Databrics, показал, что новая векторизация работает примерно в 40 раз быстрее прежней версии [3].
Больше подробностей по применению Apache Spark и R для аналитики больших данных в проектах цифровизации частного бизнеса, а также государственных и муниципальных предприятий, вы узнаете на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:
Источники
- http://datareview.info/article/dolzhen-li-spark-imet-api-dlya-r/
- https://www.rdocumentation.org/packages/base/versions/3.6.2/topics/data.frame
- https://databricks.com/blog/2020/06/01/vectorized-r-i-o-in-upcoming-apache-spark-3-0/

