
Продолжая разбираться с информационной безопасностью Internet of Things и Big Data систем, сегодня мы поговорим о каналах передачи данных – защищенных протоколах и криптографических средствах в smart-устройствах. От IoT-устройства в облако Big Data: особенности многоуровневой передачи данных по сетям Интернет вещей – это комплексная система трехзвенной архитектуры: информация с «умного»...

Мы уже рассказывали про уязвимости систем Internet of Things и причинах их возникновения. Сегодня поговорим о том, как снизить риски нарушения информационной безопасности интернета вещей, и кто отвечает за мероприятия по защите smart-устройств от взломов и IoT-платформ от утечек Big Data. Способы обеспечения информационной безопасности интернета вещей В соответствии с...

Продолжая тему информационной безопасности в мире Big Data, сегодня мы поговорим об проблемах защиты данных в системах Internet of Things. Читайте в нашем материале, как вредоносные ботнеты взламывают бытовые smart-устройства, с чем сталкивается промышленный интернет вещей при обеспечении безопасности, а также какие компоненты IoT/Big Data систем наиболее уязвимы и почему....
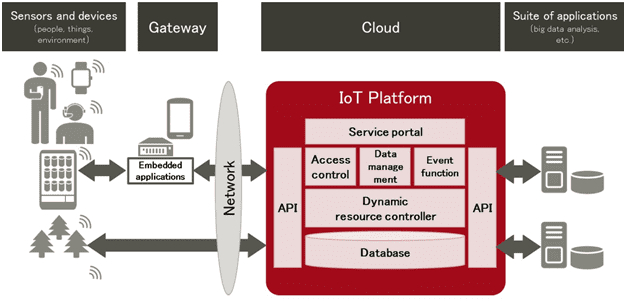
Рассматривая архитектуру и принципы работы IoT-систем, мы уже упоминали, что наиболее интеллектуальная часть работы по анализу данных выполняется в облаке с помощью специальных средств Big Data, объединенных в общую платформу. Сегодня поговорим о функциях IoT-платформ и технологиях, на которых основаны эти облачные решения. Также мы подготовили для вас краткий обзор...
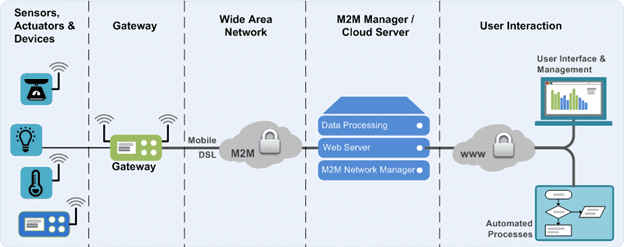
Мы уже немного рассказывали об архитектуре IoT-систем в статье про промышленный интернет вещей. Сегодня поговорим подробнее про аппаратные и программные компоненты Internet of Things и IIoT, а также разберем, как малые данные со множества датчиков преобразуются в Big Data. Архитектура IoT-системы Типовая архитектура IIoT-систем состоит из следующих 3-х уровней [1]:...
Мы уже рассказывали, как интернет вещей (Internet of Things, IoT) вместе с технологиями Big Data и машинного обучения (Machine Learning) используются в нефтегазовой, транспортной, сельскохозяйственной и машиностроительных отраслях. Сегодня поговорим подробнее про промышленный IoT (Industrial Internet of Things, IIoT) на примерах его применения в тяжелом машиностроении и рассмотрим, почему индустриальный...

В результате цифровой трансформации «традиционного предприятия» должна получиться идеальная организация, работающая на основе данных, в т.ч. больших (Big Data). Сегодня мы поговорим, что такое Data-Driven Company, чем она отличается и как ей стать: читайте в нашей статье, какие инструменты Big Data, методы Agile и инженерные подходы системного анализа применяются для...

Продолжая тему развития Agile, сегодня мы расскажем о новом видении DevOps, предполагающем полный отказ от девопс-инженеров при сохранении всех принципов этого похода. Читайте в нашей статье, что такое NoOps и как эта концепция реализуется в мире Big Data. 5 разных мнений о DevOps Хотя термину «DevOps» уже исполнилось более 10...

Несмотря на почти 20-летнюю историю термина «DevOps», даже в ИТ-среде до сих пор есть мнение, что все рабочие задачи этого девопс-инженера может выполнить рядовой системный администратор. Почему это не так и как обстоят дела с администрированием Big Data систем, читайте в нашей сегодняшней статье. Критерии и источники данных для сравнения...

Рассматривая облачные сервисы для Big Data проектов, мы уже говорили про SLA (Service Level Agreement, соглашение об уровне предоставления услуг) и упоминали показатели измерения эксплуатационной надежности в материале про эволюцию Agile-подходов. Читайте в нашей сегодняшней статье, как эти SRE-метрики помогают DevOps-инженерам и администраторам обосновать экономическую необходимость затрат на средства дополнительной защиты Big...
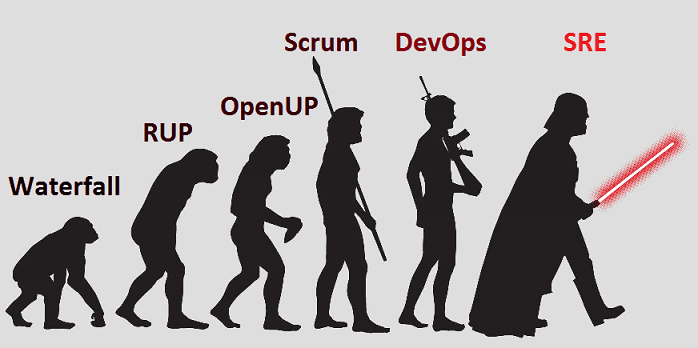
Большие данные требуют огромной гибкости и большой надежности – сегодня мы расскажем, что кто обеспечивает бесперебойную работу Google и других ИТ-гигантов и что нас ждет после DevOps. Читайте в нашей новой статье, как развиваются Agile-подходы к организации процессов разработки и эксплуатации Big Data систем и сколько это стоит. Что такое...

При всех достоинствах DevOps, этот, особенно популярный сейчас, подход к организации процессов разработки и эксплуатации ПО, не лишен недостатков. Сегодня мы поговорим о том, когда лучше обойтись без девопс и как его внедрить, если он не очень подходит, а очень хочется. Также расскажем, почему DevOps – не панацея и какие...

Продолжая тему «умного» города (data-driven city), сегодня мы собрали для вас 5 практических примеров, как в крупнейших мегаполисах по всему миру интернет вещей и большие данные с датчиков, проездных билетов и дорожных камер помогают бороться с пробками и улучшать состояние дорог, повышая уровень их безопасности и удобства использования. Internet of...

Big Data – это основа бизнеса страховых компаний, работа которых полностью основана на информации: статистике, сведениях о клиентах, страховых случаях и вероятностях их наступления, а также финансовой оценке всех этих данных. Читайте в нашей сегодняшней статье, как «большая тройка» современных информационных технологий (большие данные, машинное обучение и интернет вещей) увеличивают...

Ранее мы уже писали про DataOps- и DevOps-инженеров, а также про администраторов больших данных. Продолжая тему гибкого управления проектами (Agile) для повышения эффективности и ускорения бизнес-процессов, сегодня поговорим о том, какие еще специалисты нужны для успешного Big Data проекта. Профильные категории и процессы Big Data проекта Независимо от конечной цели...

Мы уже писали о происхождении термина DataOps, а также про методы и средства реализации этой концепции непрерывной интеграции данных между процессами, командами и системами в рамках data-driven company. Продолжая тему развития Agile-подходов в мире больших данных, сегодня рассмотрим, чем отличаются сферы ответственности DataOps- и DevOps-инженеров и почему оба этих специалиста...

DataOps (DATA Operations, датаопс), по аналогии с DevOps (DEVelopment Operations, девопс) — это концепция и набор практик непрерывной интеграции данных между процессами, командами и системами для повышения эффективности корпоративного управления или отраслевого взаимодействия за счет распределенного сбора, централизованной аналитики и гибкой политики доступа к информации с учетом ее конфиденциальности, ограничений на...

Администратор – обязательная роль в Big Data проекте, даже если он построен по принципу микросервисной архитектуры, когда за создание и развертывание каждого модуля отвечает отдельный DevOps-инженер. Задачи постоянной оценки производительности и поддержки ИТ-инфраструктуры актуальны как для новоявленных стартапов, работающих по современным Agile-принципам, так и для крупного бизнеса (enterprise). В этой...
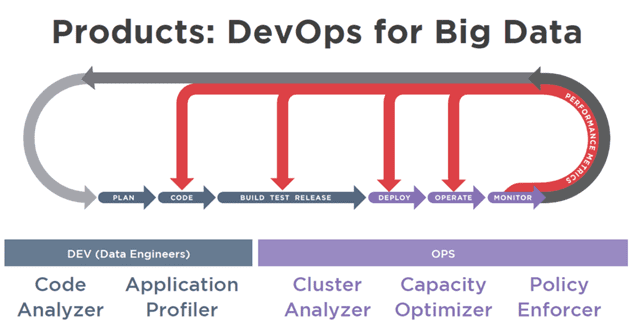
С точки зрения бизнеса DevOps (DEVelopment OPerations, девопс) можно рассматривать как углубление культуры Agile для управления процессами разработки и поставки программного обеспечения с помощью методов продуктивного командного взаимодействия и современных средств автоматизации. Сегодня мы поговорим о том, как эта методология используется в Big Data проектах, почему любой Data Scientist становится немного...
Пока Agile (эджайл) из методологии разработки программного обеспечения становится настоящей философией ведения бизнеса, мы разберем, какие именно принципы этого подхода используются в каждой системе больших данных и почему любой Big Data проект успешно реализуется с помощью этих идей. Что такое Agile: краткий ликбез Изначально термин Agile относился к подходам и...