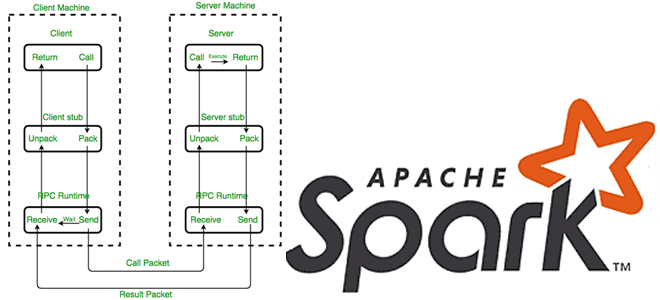
Как Apache Spark использует протокол удаленного вызова процедур для межпроцессного взаимодействия, какие параметры отвечают за эффективное выполнение RPC-запросов и где их настроить. RPC в Apache Spark Распределенный характер Apache Spark предполагает взаимодействие между компонентами, расположенными на разных узлах, например, драйвер на мастер-узле взаимодействует с исполнителями на рабочих узлах. В качестве...
Сегодня я на практическом примере покажу тонкости настройки конфигураций JDBC-коннектора источника, передающий новые записи из таблицы PostgreSQL в топик Apache Kafka. Настройка JDBC-коннектора и отправка в Kafka Connect Как я упоминала вчера, помимо CDC-коннектор Debezium, передать данные из реляционной базы данных PostgreSQL в Apache Kafka, также есть JDBC-коннектор от Confluent:...

Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker. Коннекторы Kafka к реляционным БД от Confluent О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной...

Что такое Python-декораторы в Airflow, зачем они нужны, какие они бывают и чем полезны: ликбез по TaskFlow API на практическом примере DAG. Что такое Python-декораторы в Airflow и какие они бывают Будучи написанным на Python, Apache Airflow использует именно этот язык в качестве средства разработки дата-конвейеров. После определения функции в...
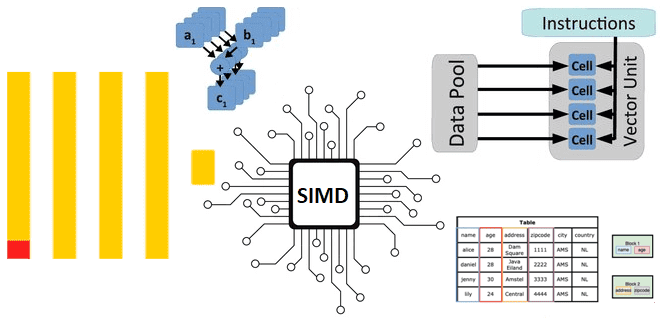
Как ClickHouse реализует параллельные векторные вычисления над большим объемом данных на любых аппаратных платформах: диспетчеризация ЦП для выполнения SIMD-инструкций в сложных функциях. Реализация векторных вычислений в ЦП Как мы уже отмечали здесь, ClickHouse имеет встроенную поддержку векторных вычислений, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно...

6 ноября 2024 года опубликован очередной выпуск самой популярной платформы потоковой передачи событий. Что нового в Apache Kafka 3.9: динамические кворумы KRaft, улучшения многоуровневого хранилища, полезные фичи Kafka Streams и Kafka Connect. Динамические кворумы KRaft Релиз Apache Kafka 3.9 официально назван последним, который использует ZooKeeper в качестве службы синхронизации метаданных....

Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости, как хранить журналы и трассировки в этой колоночной базе данных и для чего реализована интеграция с OpenTelemetry. Что такое Observability и чем ClickHouse хорош для обеспечения наблюдаемости Будучи колоночной базой данных, ClickHouse отлично подходит для мониторинга и анализа системных метрик,...

Какие задачи решают инженеры и администраторы кластера для организации многопользовательского доступа к платформе потоковой передачи событий, а также чем полезен фреймворк Strimzi для развертывания и сопровождения мультиарендной среды Apache Kafka на Kubernetes. Задачи управления мультипользовательским кластером Kafka Выступая в качестве средства интеграции информационных систем и микросервисов, в корпоративной среде Apache...
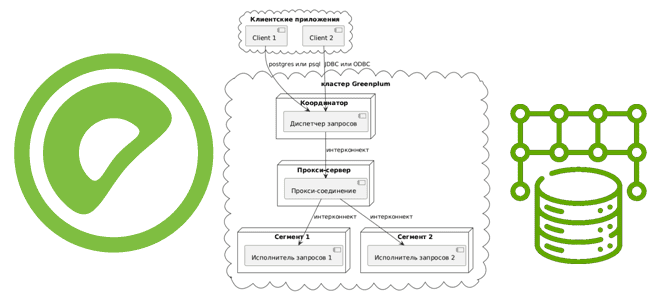
Как сегменты Greenplum взаимодействуют друг с другом для выполнения распределенных SQL-запросов, чем UDPIFC-режим интерконнекта лучше TCP-протокола, зачем проксировать межсетевые соединения и какими командами это сделать. Что такое интерконнекты в Greenplum Greenplum представляет собой массив отдельных баз данных PostgreSQL 12, работающих вместе для представления единого образа базы данных. Точкой входа в...
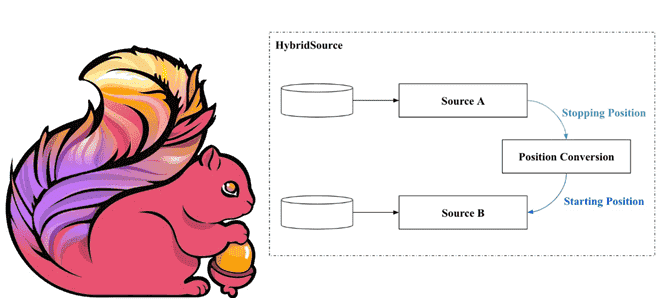
Как задание Apache Flink может читать информацию из разных источников данных в одном потоке. Что такое HybridSource и как с ним работать: разбираем на примере файла и топика Kafka. Что такое гибридный источник данных Иногда заданию Flink необходимо считывать данные из нескольких источников в последовательном порядке. Напомним, источником данных для...

23 октября 2024 года опубликован предварительный выпуск Apache Flink. Знакомимся с самыми яркими новинками этого мажорного релиза: удаленные API, коннекторы и конфигурации, динамическая оптимизация логических планов, а также дизагрегированное состояние и управление им. Критические изменения: удаление устаревших компонентов Начнем с критических изменений, связанных с удалением устаревших компонентов. В Apache Flink...

Коллеги, с ноября 2024 года мы выводим курсы по Apache Hadoop из нашей продуктовой линейки открытых программ: Основы Hadoop Администрирование кластера Hadoop Безопасность озера данных Hadoop Hadoop для инженеров данных Хотя теперь эти курсы у нас находятся в статусе архивных, и набор открытых групп на них не ведется, вы по-прежнему...

Чем обмен данными через XCom отличается от использования Dataset и какой из механизмов выбирать для обмена данными между задачами Apache Airflow: разбираем на практическом примере. Обмен данными через XCom В Apache Airflow есть несколько механизмов для обмена данными между задачами: XCom и набор данных (Dataset). При общей цели они предназначены...
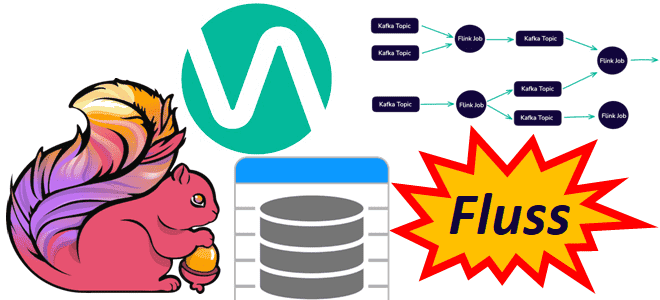
Чтобы сделать конвейеры обработки данных еще более эффективными, устраняя промежуточные хранилища для потоковых вычислений и сократить количество ETL-инструментов, немецкая компания Ververica разработала Fluss – потоковое хранилище для Apache Flink. Читайте далее, что это и чем полезно в непрерывной обработке потоков Big Data. Что не так с архитектурой конвейеров обработки данных...
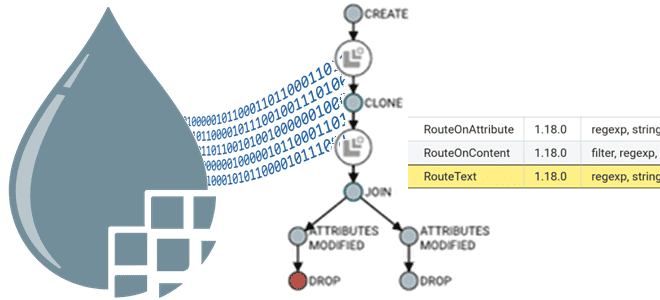
Чем процессор RouteOnContent отличается от RouteOnAttribute и RouteText: преимущества и недостатки каждого из них для маршрутизации FlowFile в Apache NiFi, варианты использования каждого из них с примерами. Маршрутизация на основе контента Как мы уже отмечали в прошлой статье, маршрутизация FlowFile в в Apache NiFi может быть на основе контента, т.е....
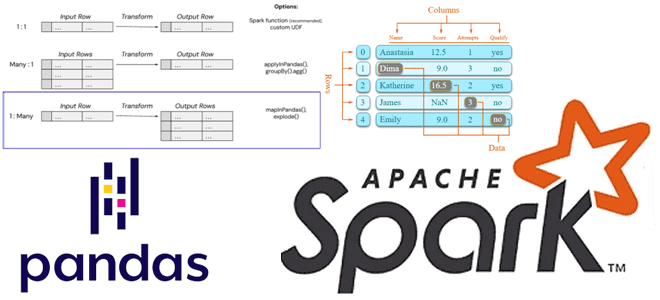
Как применить пользовательскую функцию Python к объектам pandas в распределенной среде Apache Spark. Варианты использования Pandas UDF, applyInPandas() и mapInPandas() на практических примерах. Разница между Pandas UDF, applyInPandas и mapInPandas в Apache Spark Недавно я показывала пример сравнения быстродействия метода applyInPandas() с функцией apply() библиотеки pandas. Однако, помимо applyInPandas() в...

Как разработать свой плагин Apache AirFlow: пошаговое руководство с наглядной демонстрацией. Добавляем свои пункты меню в веб-интерфейс фреймворка и встраиваем пользовательскую HTML-страницу с новым эскизом Flask. Разработка своего плагина для AirFlow Вчера я рассказывала, как расширить функциональные возможности Apache AirFlow с помощью плагинов. Сегодня рассмотрим, как это сделать на практике....
Зачем нужны плагины в Apache AirFlow, как их создать и встроить в пакетный оркестратор для внедрения пользовательских операторов, хуков, датчиков или интерфейсов взаимодействия с внешними системами. Плагины AirFlow Продолжая недавний разговор про добавление пользовательского кода в Apache AirFlow, сегодня разберемся, как расширить функциональные возможности этого ETL-оркестратора с помощью встраиваемых модулей...
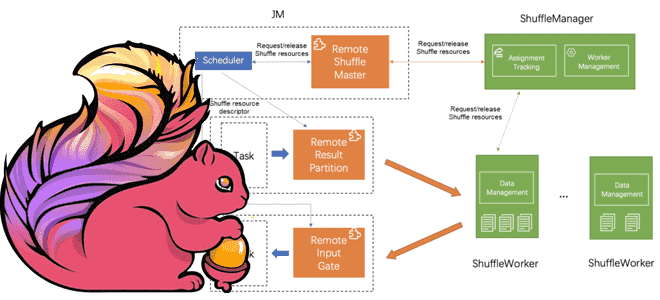
Что такое Remote Shuffle Service в Apache Flink, зачем это нужно и как служба удаленного перемешивания позволяет создавать масштабируемые и надежные приложения для унифицированной потоковой и пакетной обработки больших объемов данных. Что такое Remote Shuffle Service в Apache Flink Apache Flink рассматривает пакетную обработку как частный случай потоковых вычислений. Однако,...

4 октября 2024 года вышел очередной релиз ClickHouse. Знакомимся с его самыми интересными особенностями: добавление строк в обновляемые материализованные представления, агрегатные функции для типов данных JSON и Dynamic, поддержка заголовков HTTP-ответов, автозамена строк с overlay-командами и другие новинки выпуска 24.9. Обновляемые материализованные представления Начнем с наиболее значимой новой функции ClickHouse...