
В этой статье для обучения дата-инженеров и администраторов кластера Apache NiFi познакомимся с NiFiKop – оператором, который упрощает запуск потокового ETL-маршрутизатора на платформе контейнерной виртуализации Kubernetes. 4 трудности управления кластером Apache NiFi При том, что Apache NiFI имеет множество достоинств, предоставляя возможности сбора, маршрутизации и обогащения потоков данных из разных...

Сегодня поговорим про качество данных и разберем, что такое Soda Core, как эта платформа позволяет выявлять отсутствующие значения, дубликаты, изменения схемы и проверку актуальности. А также рассмотрим, каким образом это совместимо с Apache AirFlow и что еще есть в самом популярном ETL-планировщике для обеспечения качества и надежности данных. Качество данных...

Мы уже разбирали некоторые советы оптимизации Flink-приложений, связанные с неравномерным распределением данных по вычислительным узлам. Сегодня рассмотрим, как при этом пригодится паттерн MapReduce Combiner, который часто используется в экосистеме Apache Hadoop и вместо него лучше применить Bundle оператор, доступный с версии Flink 1.15. Проблема неравномерного распределения в Big Data вообще...

Недавно мы писали про новинки сентябрьского и октябрьского релизов Greenplum 6.22, а 18 ноября 2022 года вышла новая отладочная версия, которая решает некоторые проблемы с сервером СУБД, обработкой запросов и потоком данных. Разбираемся, что стало лучше в VMware Tanzu Greenplum 6.22.2 с точки зрения администратора кластера и дата-инженера. Новинки и...
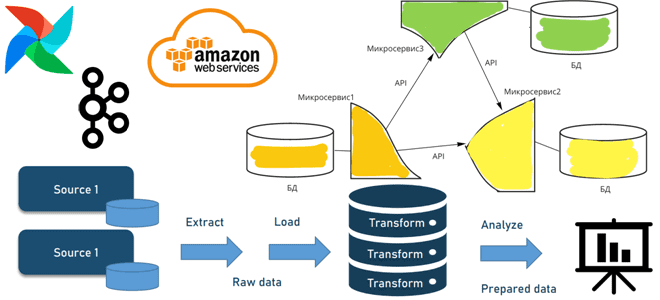
Когда и зачем переходить от пакетной парадигмы обработки к потоковой, как это сделать с помощью микросервисной архитектуры, какие проблемы могут при этом возникнуть и что за решения позволят их избежать. А в качестве примеров инструментальных средств рассмотрим сервисы AWS, Apache AirFlow и Kafka. От пакетов к потокам через микросервисы: архитектура...

Визуализация конвейеров обработки данных особенно важна в потоковой парадигме, поэтому мы часто рассматриваем полезные средства мониторинга для Apache Kafka. Сегодня разберем, что такое Streams Explorer от Bakdata и как это пригодится для дата-инженера. Проекты Bakdata для развертывания и мониторинга приложений Kafka Streams При работе с крупномасштабными потоковыми данными крайне важно...

Чтобы сделать наши курсы по Apache Spark для дата-инженеров еще более полезными, сегодня рассмотрим, как PySpark-задания могут считывать данные из корзин объектного хранилища AWS S3, используя Python-пакет boto3. Читайте далее, что представляет собой этот SDK, как использовать его вместе с IAM-ролями, а также как обеспечить безопасность конфиденциальных данных с помощью...

Мы уже сравнивали MLflow и Kubeflow, которые позволяют управлять конвейерами машинного обучения. Продолжая эту важную для ML-инженера тему, сегодня рассмотрим 2 других MLOps-инструмента для оркестрации конвейеров Machine Learning: Vertex AI Pipelines и Apache AirFlow. Что такое Vertex AI Pipelines от Google Поскольку цель концепции MLOps в том, чтобы объединить разработку...
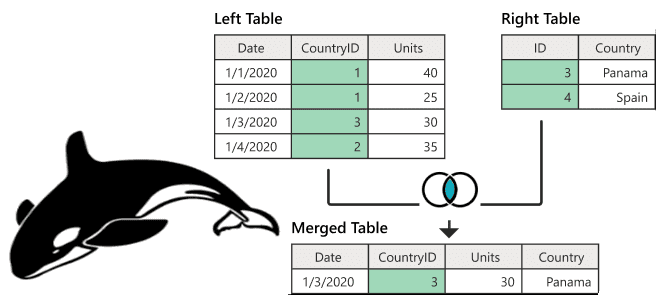
Поиск данных по нескольким таблицам в реляционных базах данных реализуется через SQL-запрос с оператором JOIN. В NoSQL-хранилищах такая возможность может отсутствовать. Разбираем, как соединить таблицы в Apache HBase и причем здесь MapReduce. Варианты реализации JOIN в Apache HBase Будучи популярной NoSQL-базой, которая реализует возможности Google BigTable для Apache Hadoop, HBase...

Поскольку Apache NiFi является распределенной системой стека Big Data, для него очень значимы вопросы балансировки нагрузки. Поэтому сегодня разберем важную для обучения дата-инженеров и администраторов кластера NiFi тему по балансировке нагрузки и распространению данных в этом потоковом ETL-фреймворке. Как происходит балансировка нагрузки в кластере Apache NiFi До версии 1.8 в...

19 сентября 2022 года вышел очередной релиз Apache AirFlow, а через пару недель выпущены его минорные обновления. Что нового в выпуске 2.4, чем полезен новый класс Dataset, что такое наборы данных, какие триггеры позволят запускать задачи и DAG в стиле cron-соглашений, зачем убрали интеллектуальные датчики и другие важные фичи, исправления...
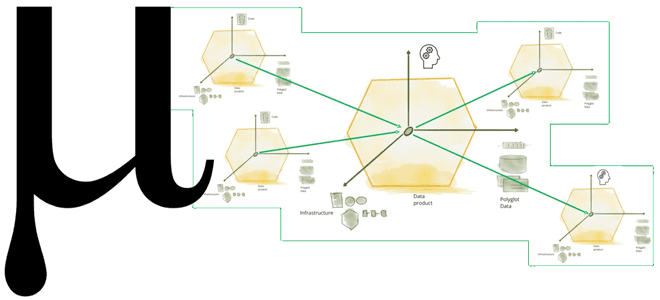
Что не так с конвейерной моделью обработки данных и почему архитектура Data Mesh с потоковой передачей событий не решают всех проблем пакетной парадигмы. Зачем нужна новая архитектура данных под названием Мю, какие инструменты и принципы она использует для устранения технологической неоднородности отдельных технологий Big Data, а также при чем здесь...

В этой статье для обучения дата-инженеров и администраторов кластера Apache Kafka разберем, какие ошибки создают медленные потребители и как решить их, просто изменив значений конфигураций по умолчанию. А также познакомимся с Lighthouse - еще одним полезным инструментом мониторинга системных метрик, который позволит обнаружить эти и другие проблемы. Проблема медленных потребителей...

Сегодня рассмотрим, зачем нужно внешнее хранилище метаданных для Apache Hive, и как запустить его высокодоступный и масштабируемый сервис в Amazon EKS путем контейнеризации приложения. Зачем нужно внешнее хранилище метаданных Apache Hive? Apache Hive используется для доступа к данным, хранящимся в распределенной файловой системе Hadoop (HDFS) через стандартные SQL-запросы. Это NoSQL-хранилище...

Можно ли применять Apache Spark Structured Streaming для пакетных заданий и в каких случаях это целесообразно. Разбираемся, как устроена потоковая передача событий в Spark Structured Streaming, с какой частотой разные режимы триггеров микропакетной обработки данных запускают потоковые вычисления и что выбрать дата-инженеру. Потоковая передача событий и пакетные задания: versus или...

В рамках продвижения нашего нового курса по графовой для аналитики больших данных аналитике больших данных, сегодня познакомимся с клиентской Python-библиотекой Neo4j под названием Py2neo, которая позволяет отказаться от языка запросов Cypher. Читайте далее, что это такое, как работает и где пригодится. Python вместо Cypher в приложениях для Neo4j Манипуляции с...

Чтобы сделать наши курсы по Apache Flink еще более полезными для дата-инженеров и разработчиков распределенных приложений потоковой аналитики больших данных, сегодня разберем, как работают источники данных потоковой обработки на примере топиков Kafka. Источники данных в Apache Flink Наряду с Apache Spark, Flink также является популярным фреймворком пакетной и потоковой обработки...
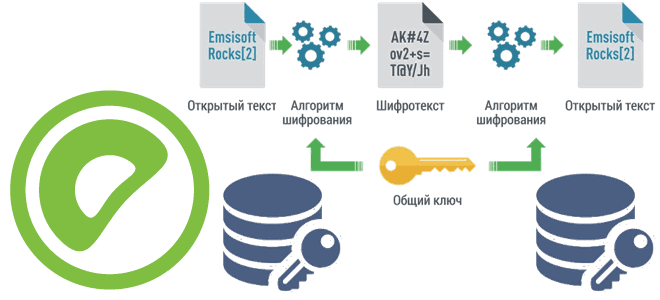
Чтобы сделать наши курсы по Greenplum еще более полезными для дата-инженеров и администраторов, сегодня познакомимся с pgcrypto – важным расширением этой MPP-СУБД, которое предоставляет криптографические функции, чтобы хранить некоторые столбцы данных в зашифрованном виде. Как установить расширение pgcrypto и использовать его для улучшения безопасности Greenplum. Шифрование данных в Greenplum База...
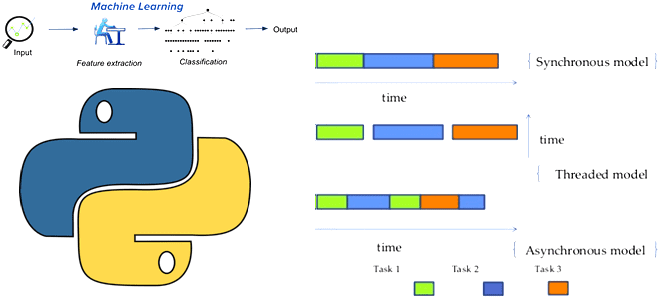
Поскольку концепция MLOps стремится устранить разрывы между разработкой ML-модели и ее имплементацией в эффективный программный код, сегодня поговорим про важную идею программирования, связанную с синхронностью и асинхронностью вызовов. Что такое асинхронное программирования, зачем это нужно в Machine Learning и какие Python-библиотеки поддерживают это. Проблемы синхронных вызовов в ML-системах В реальных...

Сегодня разберем распространенные трудности корпоративных платформ обработки и хранения Big Data, а также как избежать этих проблем, используя современные методы и средства проектирования дата-архитектур и инструменты инженерии данных. 7 главных проблем с платформами данных Обычно каждая data-driven компания органично развивает свои платформы данных, усложняя их архитектуры. Но этот процесс эволюционного...