Как с Apache Flink настроить локальную службу OLAP, а также развернуть ее в рабочей среде производственного кластера: архитектура, принципы работы и параметры конфигурации для сложных аналитических сценариев. Служба Flink OLAP: архитектура и принципы работы Идея выделить в Apache Flink механизм OLAP для анализа данных в потоковом хранилище появилась еще год...
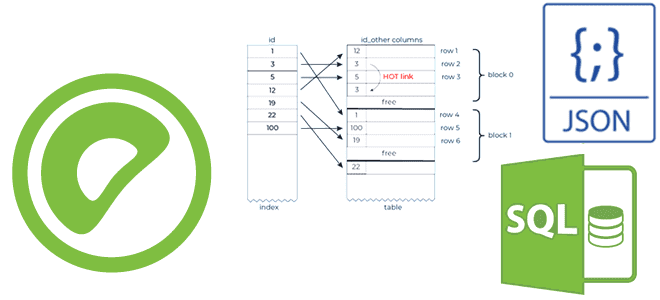
Как Greenplum индексирует JSON-документы, что такое GIN-индекс в PostgreSQL, чем он отличается от B-дерева и хэш-таблицы, когда и как их использовать, а также почему поддерживается только индексация JSONB-полей. Как Greenplum индексирует JSONB-документы Поскольку Greenplum основана на PostgreSQL, она также поддерживает работу со сложными типами данных и может вести себя подобно...

30 апреля 2024 года опубликован очередной выпуск ClickHouse, который включает 13 новых функций, 16 улучшений производительности и 65 исправлений ошибок. Знакомимся с самими интересными новинками релиза 24.4. Значимые новинки Clickhouse 24.2 Начнем с повседневных операций с таблицами: теперь в ClickHouse можно зараз удалить несколько таблиц со всем их содержимым, используя...
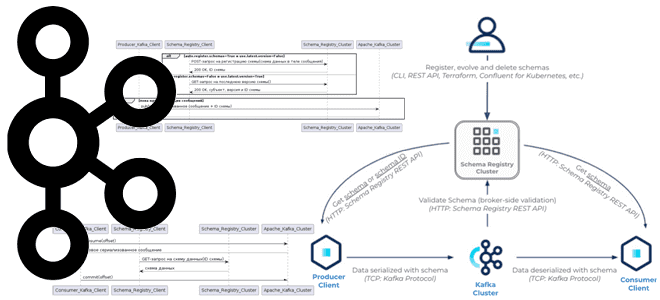
Почему клиентское приложение для публикации сообщений или их потребления из Kafka при использовании реестра схем существует в двух экземплярах, что добавляется к сериализованному сообщению, где хранится идентификатор схемы и другие тонкости работы с Confluent Schema Registry. Сериализация и десериализация сообщений с реестром схем Apache Kafka Недавно я показывала небольшую демонстрацию...
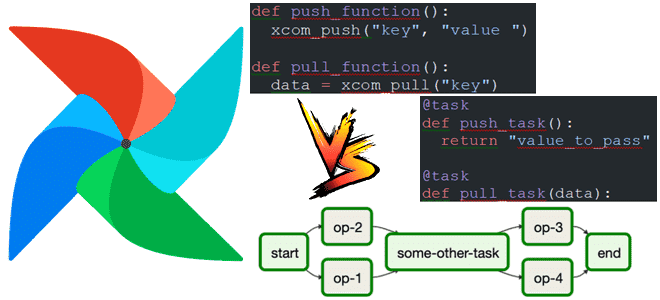
Чем API TaskFlow отличается от традиционных операторов Apache Airflow, можно ли их использовать вместе и как это сделать для более эффективной передачи данных между задачами DAG с помощью механизма XCom: несколько примеров. Что такое API TaskFlow в Apache Airflow Чтобы реализовать конвейер обработки данных в Apache AirFlow, можно использовать традиционные...

Что такое assert, зачем это нужно в тестировании и отладке, как эта конструкция применяется для сравнения датафреймов в PySpark: примеры работы функций assertDataFrameEqual() и assertSchemaEqual() в Apache Spark. Что такое assert: конструкция тестирования При разработке PySpark-приложения дата-инженер чаще всего оперирует такими структурами данных, как датафрейм. Датафрейм (DataFrame) – это распределенная...
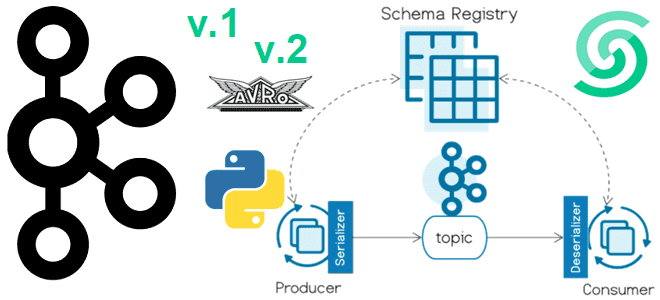
Версионирование схемы сообщений в формате AVRO с использованием реестра схем Apache Kafka и библиотеки confluent_kafka: практический пример на Python в Google Colab. Публикация сообщений в Kafka с использованием реестра схем Недавно я показывала пример использования реестра схем (Schema Registry) Apache Kafka при публикации сообщений. Сегодня рассмотрим версионирование схемы данных в...
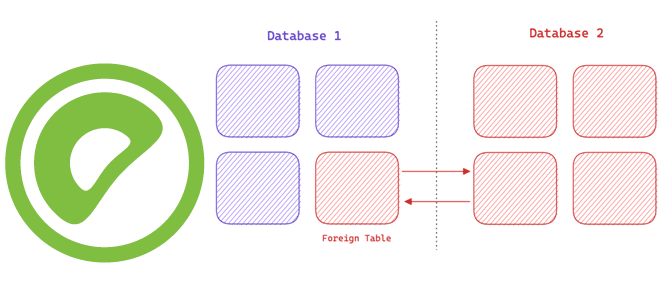
Чем внешняя таблица Greenplum отличается от сторонней, и как они преобразуются друг в друга: организация доступа к данным вне базы, FDW-обертки и протоколы для интеграции MPP-СУБД с другими источниками информации. Сторонняя таблица в Greenplum Термины внешняя (external) и сторонняя (foreign) table похожи, но нюансы их использования в Greenplum отличаются. Такие...
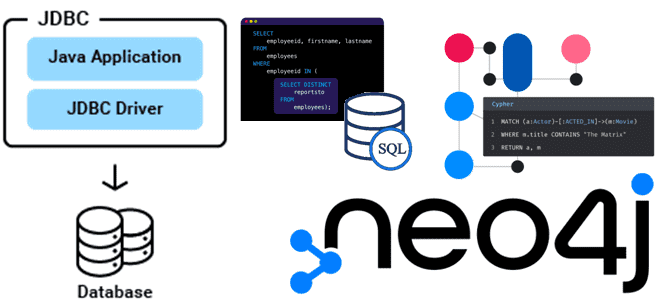
Что не так с общим Java-драйвером Neo4j, зачем нужен JDBC-драйвер, какие функции он поддерживает, а что не позволяет разработчику делать с этой графовой базой данных. Что не так с общим Java-драйвером Neo4j и зачем нужен JDBC-драйвер 25 марта 2024 года вышла 6-я версия драйвера JDBC для графовой СУБД Neo4j, поддерживаемого...
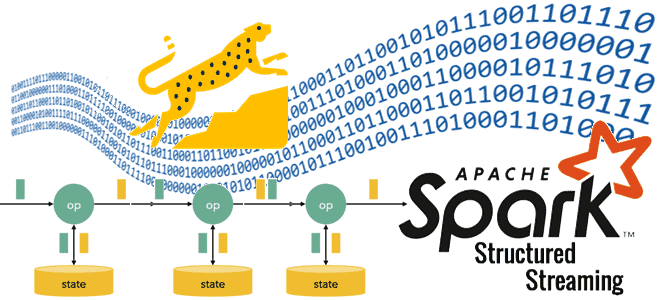
Где stateful-операторы хранят состояния, почему RocksDB лучше HDFSBackedStateStore и как Databricks адаптировал key-value хранилище к особенностям Spark Structured Streaming, чтобы сделать потоковую обработку больших данных еще быстрее. Где stateful-операторы Spark Structured Streaming хранят состояния? Хотя Apache Spark Structured Streaming реализует потоковую парадигму обработки информации, он по-прежнему использует микропакеты, т.е. ограниченные...

8 апреля 2024 года вышел очередной релиз Apache AirFlow. Знакомимся с ключевыми новинками выпуска 2.9: от функций работы с наборами данных до настроек внешнего объектного хранилища в качестве бэкенда XCom-объектов и особенностей поддержки Python 3.12. Наборы данных и гибкое планирование DAG Airflow Выпуск 2.9 содержит более 35 интересных новых функций,...
Как связать ClickHouse с Apache Kafka: примеры проектирования и реализации онлайн-аналитики с использованием облачного сервиса колоночной СУБД, брокера сообщений и BI-системы Яндекса. Постановка задачи и проектирование потокового конвейера Для взаимодействия с внешними хранилищами ClickHouse использует специальные механизмы – интеграционные движки таблиц. Вчера я показывала пример интеграции ClickHouse со встроенной key-value...

Сегодня разберем, как из ClickHouse обратиться к встроенной key-value БД RockDB, используя табличный движок EmbeddedRocksDB, и познакомимся с возможностями новой песочницы колоночной базы данных. Постановка задачи и DDL-скрипты Колоночная СУБД ClickHouse поддерживает несколько движков таблиц, включая интеграционные механизмы для взаимодействия со сторонними системами, одной из которых является key-value база данных...

Тонкости параллельной среды выполнения Cypher-запросов в NoSQL-СУБД Neo4j и критерии выбора runtime для аналитических и транзакционных сценариев работы с графами. Слотовая и конвейерная среды выполнения Вообще в графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. По умолчанию в версии в Community Edition используется слотовая, а...
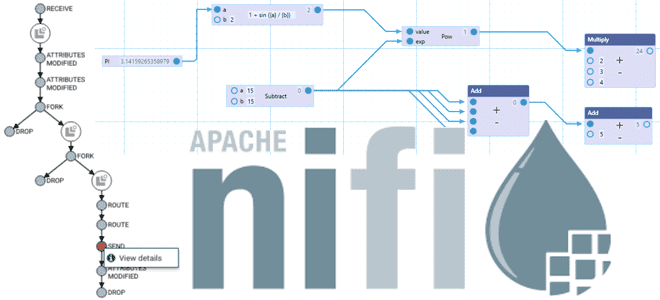
Что такое программирование потоков данных и как ключевые идеи FBP-парадигмы обеспечивают высокую скорость и мощь Apache NiFi в потоковой обработке. Что такое Flow-Based Programming Каждый дата-инженер, работающий с Apache NiFi, знает, что этот фреймворк поддерживает потоковую обработку информации, понимая под потоком неограниченно поступающие данные. Однако, фундаментальные концепции NiFi основаны на...

В конце февраля вышел очередной релиз Apache Kafka за номером 3.7. Поддержка JBOD в KRaft-кластерах, новый протокол перебалансировки потребителей, мониторинг метрик клиента на брокере, новинки Streams и Connect, и другие изменения самой популярной платформы потоковой передачи событий для дата-инженера и администратора. Изменения в брокерах, продюсера, контроллерах и Admin Client 27...
Чем слотовая среда выполнения Cypher-запросов в Neo4j отличается от конвейерной, как ее задать и что выбрать для транзакционных и аналитических сценариев работы с графами: наглядные примеры. Слотовая среда выполнения В графовой NoSQL-СУБД Neo4j есть три типа среды выполнения Cypher-запросов: слотовая, конвейерная и параллельная. В большинстве случаев среды выполнения по умолчанию...

18 марта 2024 года вышел очередной релиз Apache Flink. Знакомимся с его главными новинками и разбираемся, чем они полезны для потоковой обработки больших данных: ключевые изменения выпуска 1.19 для разработчика stateful-приложений. Динамическая настройка параллелизма Выпуск Apache Flink 1.19 можно назвать значимой вехой, поскольку он не только включает новые функции, улучшения...
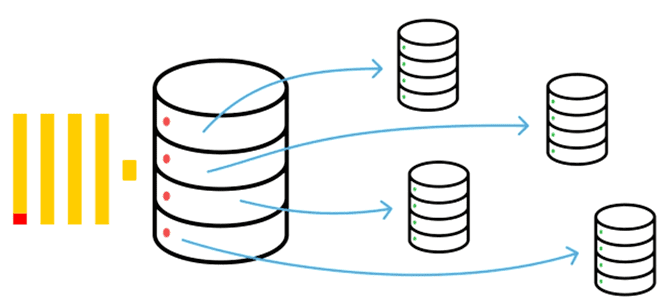
Как повысить производительность ClickHouse с помощью горизонтального масштабирования, разделив данные на шарды: принципы шардирования, стратегии выбора ключа, особенности работы с distributed-таблицами и настройки конфигураций сервера. Шардирование в ClickHouse Именно хранилище данных всегда является узким местом любой системы. Поэтому именно его надо расширить для повышения производительности. Это можно сделать с помощью...
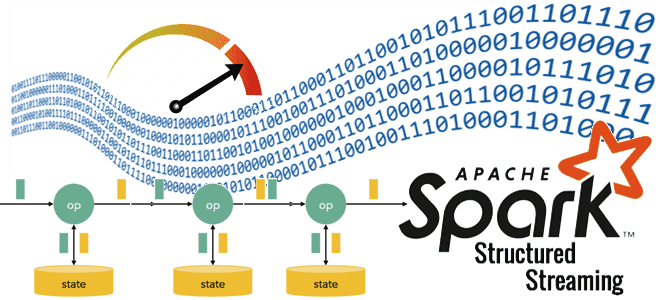
Где хранятся состояния операторов в stateful-приложениях Apache Spark Structured Streaming, зачем разработчику нужны данные о состояниях, как их получить и чем для этого полезен новый API State Reader от Databricks. Хранение состояние в Apache Spark Structured Streaming В феврале 2024 года компания Databricks выпустила очередную версию Databricks Runtime – среду...