Почему параллельное выполнение заданий в Apache Spark зависит от языка программирования и как можно обойти однопоточную природу Python в PySpark. Что не так с параллельным выполнением заданий PySpark и как это исправить? Apache Spark позволяет писать распределенные приложения благодаря инструментам для распределения ресурсов между вычислительными процессами. В режиме кластера каждое...
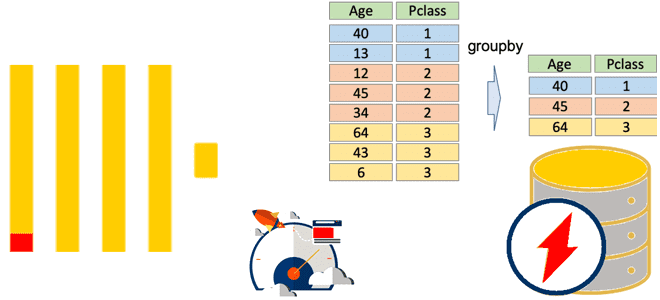
Как работают агрегатные функции в ClickHouse, почему SQL-запросы с GROUP BY потребляют много памяти и что поможет сделать их быстрее и эффективнее: лайфхаки многопоточной агрегации в колоночной базе данных. Особенности выполнения оператора GROUP BY в ClickHouse Агрегатные функции позволяют вычислить экстремум (минимум/максимум), среднее значение, количество, сумму или другое результирующее значение...
Что такое вебхук и как отправить событие из PostgreSQL в Apache Kafka, используя API Webhook на платформе Upstash. NoCode-интеграция БД и брокера сообщений: практический пример. Практический пример: CDC из PostgreSQL в Kafka через веб-хуки Веб-хук или перехватчик – это настраиваемый обратный HTTP-вызов из одной системы к другой. Он используется для...

26-28 июня мы провели первый пилот нашей новой образовательной программы для дата-инженеров по Yandex Managed Service for Apache Airflow™, разработанной в сотрудничестве со специалистами компании Яндекс. Наши слушатели провели 3 активных дня, изучая теорию про самый популярный пакетный оркестратор и сразу же применяя ее на практике. За 24 часа каждый...

Как размер пакета, режим вывода и интервал срабатывания триггера потоковой обработки влияют на скорость вычислений в приложении Apache Spark Structured Streaming и как настроить эти параметры. Размер пакета при потоковой обработке данных в Spark Streaming Хотя скорость обработки данных средствами Apache Spark Streaming зависит от многих факторов, включая саму структуру...

Чем уязвимость устаревшего метода аутентификации OpenID в Flask-AppBuilder опасна для Apache AirFlow и как это исправить? Обзор уязвимости CVE-2024-25128. Уязвимости OpenID для FAB в Apache AirFlow В конце февраля 2024 выяснилось, что в прошлом релизе Apache AirFlow 2.8, вышедшем 14 декабря прошлого года, обнаружилась критическая уязвимость, набравшая более 9 баллов...
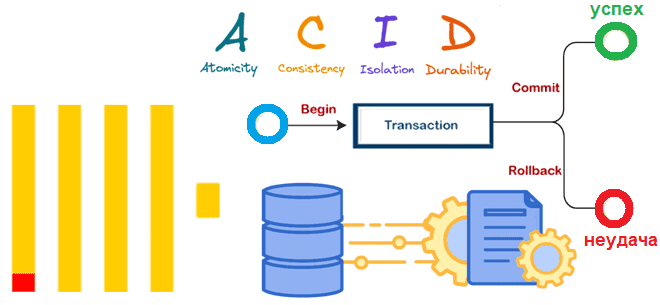
Почему в ClickHouse нет полноценных транзакций, но введена экспериментальная поддержка ACID для операций вставки в таблицы движка MergeTree, как это реализуется и чем синхронная вставка отличается от асинхронной. Особенности операций вставки в ClickHouse В ClickHouse нет полноценных транзакций, поскольку это колоночное хранилище в первую очередь ориентировано на чтение большого объема...
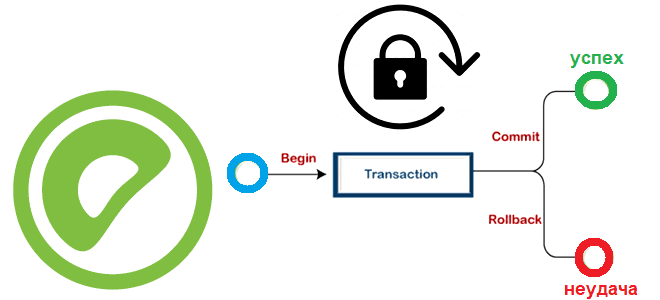
Какие SQL-команды есть в Greenplum для транзакционной обработки данных, как MVCC исключает явные блокировки, можно ли установить их вручную и как это сделать: режимы блокировки и глобальный детектор взаимоблокировок в MPP-СУБД. Транзакции, MVCC и режимы блокировки Greenplum Про изоляцию транзакций в Greenplum и Arenadata DB мы уже писали здесь. Транзакции...
Как Apache Kafka использует страничный кэш операционной системы, какие конфигураций файловой системы надо настраивать для повышения пропускной способности и снижения задержки и каковы недостатки RAID-массивов для надежного хранения опубликованных сообщений. Страничный кэш ОС и быстродействие Kafka В отличие от RabbitMQ, Apache Kafka может обеспечить долговременное хранение сообщений, записывая их на...
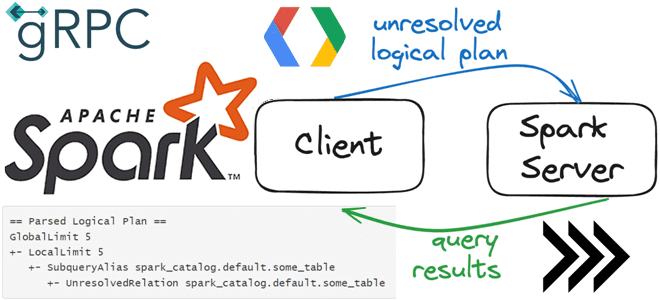
Что общего у клиент-серверной архитектуры Spark Connect с JDBC-драйвером подключения к БД, как взаимодействуют клиент и сервер по gRPC, как подключиться к серверу и указать обязательность поля в схеме proto-сообщения. Как работает Spark Connect О том, что представляет собой Spark Connect и зачем нужен этот клиентский API, позволяющий удаленно подключаться...

3 июня 2024 года вышел предварительный релиз Apache Spark 4.0. Эта версия еще не считается стабильной и предназначена только для ознакомления. Поэтому даже полноценные release notes по ней пока отсутствуют. Тем не менее, сегодня познакомимся с наиболее интересными фичами этого выпуска: новый тип данных VARIANT, API источника данных Python и...

Почему потоковый сервер Greenplum выгружает данные во внешние системы пакетно: тонкости утилиты gpfdist и YAML-файла конфигурации выгрузки. Возможности и ограничения GPSS-сервера при выгрузке данных во внешние системы из MPP-СУБД. Потоковый сервер Greenplum Ключевым отличием Greenplum от PostgreSQL является поддержка механизма массово-параллельной обработки, благодаря чему эта MPP-СУБД относится к стеку Big...
Как изменить приоритет задачи в очереди исполнителя Apache AirFlow, на что влияет метод определения весов, каким образом можно балансировать нагрузку с помощью пулов и зачем настраивать количество слотов. Как приоритизировать задачи в очереди Apache AirFlow Дата-инженеры, которые используют Apache AirFlow для оркестрации пакетных процессов, знают, что задачи скапливаются в очереди...
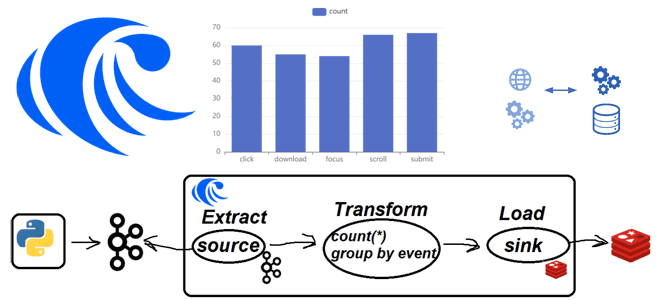
Практическая демонстрация потоковой агрегации событий пользовательского поведений из Apache Kafka с записью результатов в Redis на платформе RisingWave: примеры Python-кода и конвейера из SQL-инструкций. Постановка задачи Одной из ярких тенденций в современном стеке Big Data сегодня стали платформы данных, которые позволяют интегрировать разные системы между собой, поддерживая как пакетную, так...
Архитектура Data Lake: что не так с потоковыми обновлениями данных в Data Lake, как Apache Iceberg реализует эти операции и почему Upsolver решили улучшить этот формат Проблема потоковых обновлений в Data Lake и 2 подхода к ее решению Считается, что озеро данных (Data Lake) предлагают доступное и гибкое хранилище, позволяющее...
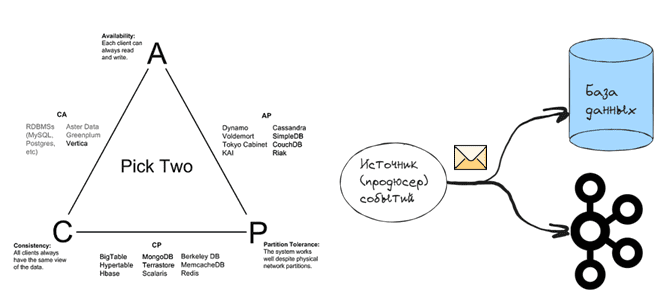
Проклятье CAP-теоремы: проблема целостности данных в распределенной системе и варианты ее решения. 3 шаблона проектирования микросервисной EDA-архитектуры на Apache Kafka: transactional outbox, Event Sourcing и listen to yourself. Что такое проблема двойной записи в распределенных гетерогенных системах Согласно CAP-теореме, распределенная система в любой момент времени обеспечивает выполнение только 2-х требований...
Что такое задачи отчетности, зачем они нужны и как с их помощью отслеживать события и системные метрики экземпляра NiFi-приложения, а также JVM. Обзор Reporting Tasks в Apache NiFi 2.0. Задачи отчетности в Apache NiFi Чтобы отслеживать события и метрики работающего экземпляра приложения Apache NiFi, этот фреймворк предоставляет специализированные инструменты, которые...
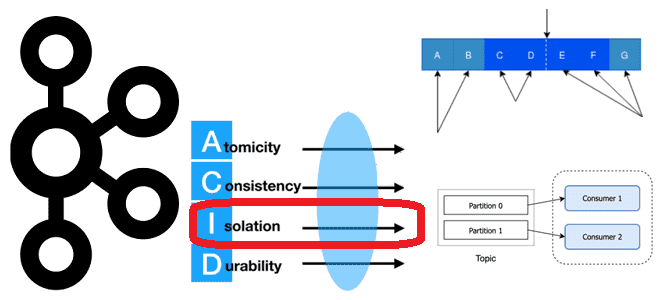
Как Apache Kafka реализует требование к изоляции потребления сообщений, опубликованных транзакционно, и где это настроить в клиентских API, зачем отслеживать LSO, для чего прерывать транзакцию, и какими методами это обеспечивается в библиотеке confluent_kafka. Транзакционое потребление: изоляция чтения сообщений в Apache Kafka При том, что Apache Kafka не является базой данных,...
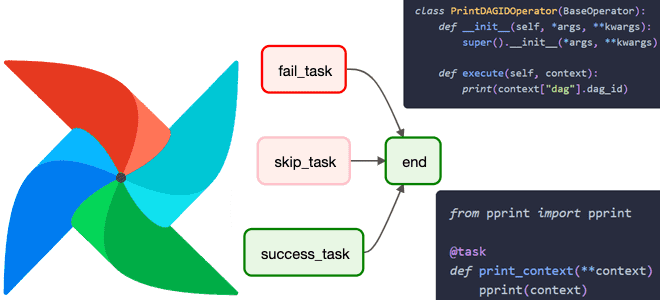
Для чего нужен контекст задачи Apache AirFlow, что он собой представляет, какие включает объекты, как получить к ним доступ и чем они полезны дата-инженеру. Что такое контекст задачи Apache AirFlow В разработке ПО контекстом называется среда, в которой существует объект. Это понятие очень важно при использовании специализированных фреймворков. Например, в...

Для чего смотреть планы выполнения запросов при работе с API pandas в Spark и как это сделать: примеры использования метода spark.explain() и его аргументов для вывода логических и физических планов. Разбираем на примере PySpark-скрипта. API pandas и физический план выполнения запроса в Apache Spark Мы уже писали, что PySpark, API-интерфейс...