
Самообслуживаемая аналитика больших данных – один из главных трендов в современном мире Big Data, который дополнительно стимулирует цифровизация. В продолжение темы про self-service Data Science и BI-системы, сегодня мы рассмотрим, что такое Cloudera Data Science Workbench и чем это зарубежный продукт отличается от отечественного Arenadata Analytic Workspace на базе Apache...

В этой статье мы рассмотрим, что такое Apache Zeppelin, как он полезен для интерактивной аналитики и визуализации больших данных (Big Data), а также чем этот инструмент отличается от популярного среди Data Scientist’ов и Python-разработчиков Jupyter Notebook. Что такое Apache Zeppelin и чем он полезен Data Scientist’у Начнем с определения: Apache...
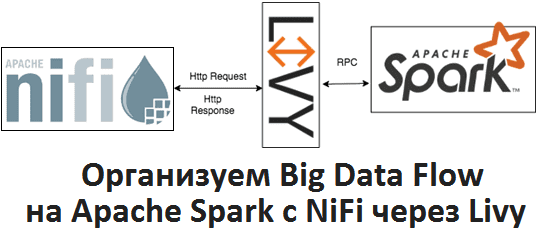
Apache Livy полезен не только при организации конвейеров обработки больших данных (Big Data pipelines) на Spark и Airflow, о чем мы рассказывали здесь. Сегодня рассмотрим, как организовать запланированный запуск пакетных Spark-заданий из Apache NiFi через REST-API Livy, с какими проблемами можно при этом столкнуться и что поможет их решить. Что...

Продолжая разговор про Apache Livy, сегодня мы сравним этот REST API для Spark c другой популярной Big Data системой планирования рабочих процессов для управления заданиями Hadoop – Oozie. Читайте в нашей статье, что такое Apache Oozie, чем он похож на Livy и в чем между ними разница, а также когда...
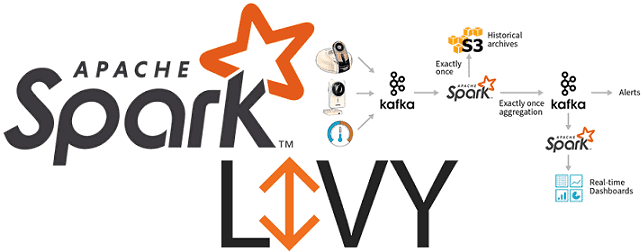
Вчера мы рассказывали про особенности совместного использования Apache Spark с Airflow и достоинства подключения Apache Livy к этой комбинации популярных Big Data фреймворков. Сегодня рассмотрим подробнее, как работает Apache Livy, а также за счет чего этот гибкий API обеспечивает удобство работы с Python-кодом и общие Spark Context’ы для разных операторов...

Сегодня поговорим про построение конвейеров обработки данных (data pipeline) на примере совместного использования Apache Spark с Airflow и рассмотрим типовые проблемы этой комбинации. Читайте в нашей статье, как автоматизировать задачи пакетной и потоковой обработки больших данных (Big Data) с помощью гибкого REST-API Apache Livy, включая работу с Python-кодом, отказоустойчивость и...

Вчера мы говорили про наиболее перспективные технологии 2020 с точки зрения исследовательского агентства Gartner и их влияние на цифровую трансформацию. Сегодня продолжим разбирать современные тенденции изменения рабочего пространства с учетом эпидемиологической напряженности и тренда на дистанционное взаимодействие. Читайте далее, что такое Desktop as a Service, как выглядит интеллектуальное рабочее пространство,...

Постоянно обновляя наши курсы «Аналитика больших данных для руководителей» в соответствии с развитием области Big Data и вызовов современного бизнеса, сегодня мы расскажем про наиболее перспективные технологии с точки зрения исследовательского агентства Gartner, а также рассмотрим их влияние на цифровую трансформацию. Читайте в нашей статье, почему цифровой двойник нужен не...

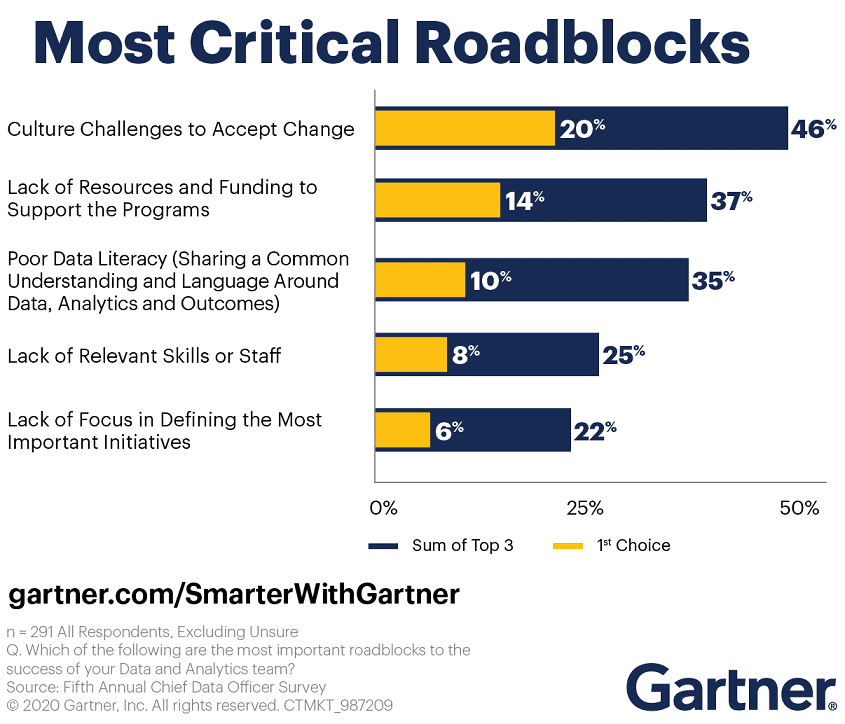
В продолжении темы про текущее состояние и ожидаемые тренды цифровой трансформации отечественных предприятий, сегодня мы рассмотрим, что мешает директору по цифровизации успешно воплощать стратегию корпоративного изменения. Читайте далее, с какими основными трудностями сталкивается Chief Digital Transformation Officer (CDTO) и как их обойти. 5 проблем CDTO: главные факторы, препятствующие цифровой трансформации...

Недавно мы писали про 5 главных факторов, которые сдерживают цифровизацию бизнеса и государства по версии аналитического агентства Gartner. Сегодня поговорим про динамику отечественной цифровой трансформации, рассмотрев соответствующий отчет российского исследовательского бюро KMDA. Читайте в нашей статье, какие отрасли в России могут считать себя data-driven, от чего зависит успех цифровизации и...

Сегодня мы расскажем о важности прикладного бизнес-анализа в проектах Big Data, включая цифровизацию частного бизнеса и государственных предприятий. Читайте в нашей статье, как области знаний профессионального руководства по бизнес-анализу BABOK®Guide соответствуют типовым этапам внедрения технологий больших данных в корпоративную деятельность, и почему цифровая трансформация любой компании – это, прежде всего,...

Вчера мы рассказывали об основных сценариях запуска Apache Spark на Kubernetes и преимуществах этого варианта развертывания популярного Big Data фреймворка на DevOps-платформе автоматизированного управления контейнеризированными приложениями. Сегодня поговорим про обратную сторону всех этих преимуществ: читайте в нашей статье, каковы основные ограничения и главные недостатки запуска Apache Spark на Kubernetes (K8s)....

Чтобы сделать курсы по Spark еще более интересными и полезными, сегодня мы расскажем, зачем этот Big Data фреймворк разворачивают на Kubernetes (K8s) – платформе автоматизации развёртывания, масштабирования и управления контейнеризированными приложениями. Читайте в нашей статье про основные варианты использования и достоинства этого подхода к администрированию и эксплуатации Apache Spark. Зачем...

Продолжая тему тотальной цифровизации и аналитики больших данных в государственных интересах, сегодня мы рассмотрим, как власть хочет поддержать отечественный ИТ-сектор с помощью налоговых маневров, инвестиций в образование и систему грантов. Читайте в нашей статье, как эти мероприятия отразятся на общем бюджете страны и что думает по этому поводу бизнес. Как...

Мы уже писали о преимуществах DaaS-похода, когда облачные провайдеры предоставляют данные как услугу, включая сложную предиктивную аналитику с использованием алгоритмов машинного обучения. Это позволяет быстро и удобно воспользоваться технологиями Big Data без существенных инвестиций в ИТ-инфраструктуру и дорогих специалистов, таких как Data Scientist, инженер и аналитик больших данных. Однако все...

Недавно мы рассказывали, что аналитика больших данных с помощью технологий Big Data – это необязательно удел только крупных корпораций. В этой статье мы рассмотрим реальный бизнес-кейс, как извлечь выгоду из накопленных данных о своих пользователях, применяя для этого возможности NoSQL-СУБД Elasticsearch для полнотекстового поиска по полуструктурированным данным и веб-интерфейс визуализации...
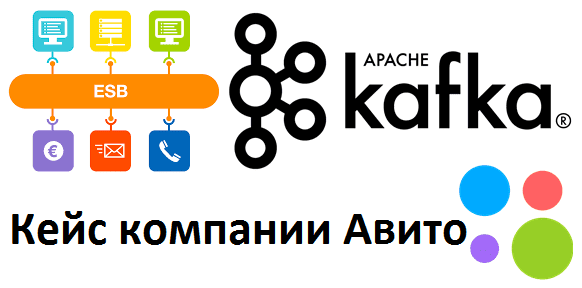
Есть мнение, что использование Apache Kafka в качестве корпоративной сервисной шины (ESB, Enterprise Service Bus) является антипаттерном. Сегодня мы проясним это категоричное утверждение и рассмотрим, как корректно реализовать ESB с помощью Kafka на практическом примере шины данных в компании Avito.ru. Что такое ESB и чем это отличается от брокера сообщений...
Сегодня цифровизация частного бизнеса и государственных предприятий – это не просто часть национальной программы «Цифровая экономика», а фактически новая национальная идея. Однако, не все так гладко: сегодня мы рассмотрим, почему на практике большинство проектов цифровой трансформации терпят неудачи или сталкиваются с существенными трудностями в процессе реализации. Читайте в нашей статье...
Сегодня рассмотрим примеры совместного использования двух популярных технологий потоковой обработки больших данных (Big Data): Apache Kafka и NiFi. Читайте в нашей статье, как они дополняют друг друга, каковы преимущества их объединения и каким образом инженеру Data Flow это реализовать на практике. Еще раз о том, что такое Apache Kafka и...

В этой статье мы рассмотрим несколько популярных мифов о Data Science и аналитике больших данных (Big Data), разобрав, когда и почему простое использование BI-систем или облачных DaaS-платформ бывает гораздо эффективнее попыток внедрения алгоритмов машинного обучения (Machine Learning) и прочих методов Data Science в операционные и стратегические бизнес-процессы. Почему 80% Data...