
В рамках обучения инженеров больших данных, вчера мы рассказывали о новой версии Apache AirFlow 2.0, вышедшей в декабре 2020 года. Сегодня рассмотрим особенности перехода на этот релиз: в чем сложности миграции и как их решить. Читайте далее про сохранение кастомизированных настроек, тонкости работы с базой метаданных и конфигурацию для развертывания...

Отвечая на вопрос, что такое большие данные для чайников, сегодня мы рассмотрим 3 практических примера использования технологий Big Data в малом и среднем бизнесе. Никакой Rocket Science, только понятные кейсы, которые актуальны для любой современной компании, даже если она состоит из пары человек: аналитика больших данных и машинное обучение для...

Совместное использование Apache Kafka и Spark очень часто встречается в потоковой аналитике больших данных, например, в прогнозировании пользовательского поведения, о чем мы рассказывали вчера. Однако, временные метки (timestamp) в приложении Spark Structured Streaming могут отличаться от времени события в топике Kafka. Читайте далее, почему это случается и какие подходы к...
В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
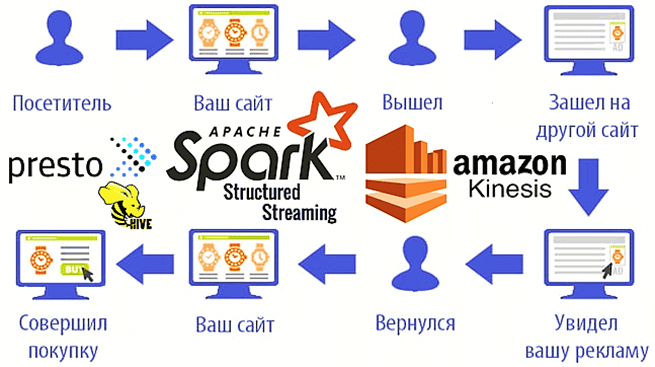
Мы уже рассказывали о возможностях ретаргетинга и использовании Apache Spark Structured Streaming для реализации этого рекламного подхода на примере Outbrain. Такое применение технологий Big Data сегодня считается довольно распространенным. Чтобы понять, как это работает на практике, рассмотрим кейс маркетинговой ИТ-компании MIQ, которая запускает Spark-приложения на платформе Qubole и сервисах Amazon,...

Вчера мы говорили про реализацию exactly once семантики доставки сообщений в Apache Spark Structured Streaming. Сегодня рассмотрим, что не так с размером компактных файлов для хранения контрольных точек потоковой передачи, какие параметры конфигурации Spark SQL отвечают за такое логирование и как ускорить микро-пакетную обработку больших данных и чтение результатов выполнения...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

В этой статье разберем ключевые характеристики идеального конвейера обработки больших данных. Читайте далее, чем отличается Big Data Pipeline, а также какие приемы и технологии помогут инженеру данных спроектировать и реализовать его наиболее эффективным образом. В качестве практического примера рассмотрим кейс британской компании кибербезопасности Panaseer, которой удалось в 10 раз сократить...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Чтобы добавить в наш новый курс по Apache Kafka для разработчиков еще больше практических примеров, сегодня мы приготовили для вас кейс немецкой железнодорожной компании Deutsche Bahn AG. Читайте далее, почему приложения Kafka Streams заменили Apache Storm и как крупнейшая транспортная компания Германии построила собственную информационную платформу на базе Apache Kafka,...
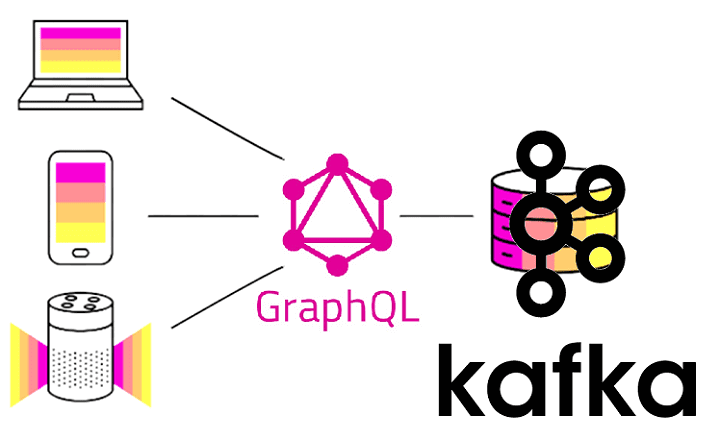
В рамках продвижения нашего нового курса Apache Kafka для разработчиков недавно мы рассматривали RESTful API к этой Big Data платформе потоковой обработки событий на примере Confluent REST Proxy. Сегодня разберем альтернативу REST-интерфейсам в виде GraphQL и применимости этой технологии к разработке распределенных Kafka-приложений. Что такое GraphQL и чем он лучше...
Сегодня поговорим про обучение Apache Kafka и рассмотрим сценарии применения HTTP и RESTful протоколов в этой Big Data платформе потоковой обработки событий. Читайте далее, чем парадигма request-response отличается от event streaming processing, как связаны REST и HTTP, каковые преимущества RESTful API и где это используется на практике для обработки и...

Говоря про обучение Apache Spark для разработчиков, сегодня мы рассмотрим, как быстро конвертировать Python-скрипты в задания PySpark и какие конфигурационные параметры при этом нужно настроить, чтобы эффективно использовать все возможности распределенных вычислений над большими данными (Big Data). Читайте далее, чем отличаются датафреймы в Pandas и Apache Spark, для чего нужны...

Интерактивная аналитика больших данных - одно из самых востребованных и коммерциализированных приложений для технологий Big Data. В этой статье мы рассмотрим, как крупный британский ритейлер запустил цифровую трансформацию своей ИТ-архитектуры, уходя от традиционного DWH с пакетной обработкой к событийно-стриминговой облачной платформе на базе Apache Kafka и Snowflake. Зачем модному ритейлеру...

Чтобы добавить в наши курсы для дата-инженеров еще больше реальных примеров и лучших DataOps-практик, сегодня мы расскажем, как специалисты крупной норвежской компании DNB обеспечивают надежный доступ к чистым и точным массивам Big Data, применяя передовые методы проектирования данных и реализации конвейеров их обработки. В этой статье мы собрали для вас...

Аналитика больших данных напрямую связана с их качеством, которое необходимо отслеживать на каждом этапе непрерывного конвейера их обработки (Pipeline). Сегодня рассмотрим методы и средства обеспечения Data Quality на примере корпорации Airbnb. Читайте далее про лучшие практики повышения качества больших данных от компании-разработчика самого популярного DataOps-инструмента в мире Big Data, Apache...

Продолжая разговор про обучение Apache Spark для инженеров данных на практических примерах, сегодня разберем, как организовать интеграцию этого Big Data фреймворка с MPP-СУБД Greenplum. В этой статье мы расскажем о коннекторе Greenplum-Spark, который позволяет эффективно связывать эти средства работы с большими данными, выстраивая аналитический конвейер их обработки (data pipeline). Типовые...

Говоря про практическое обучение Apache Spark для дата-инженеров, сегодня рассмотрим особенности разработки собственного коннектора для этого фреймворка на примере его интеграции с BI-системой Tableau. Читайте далее, как конвертировать Spark RDD в нужный формат и сделать свой коннектор удобным для пользователей. Интеграция Spark с внешними источниками данных через коннекторы Apache Spark...

Сегодня рассмотрим Apache Spark с важной для разработчиков распределенных приложений точки зрения, разобрав как в рамках этого Big Data фреймворка справиться с утечками данных при их потоковой передаче. Читайте далее, почему возникает OutOfMemory Exception в Spark-приложениях и как дата-инженеры компании Disney решили эту проблему с нехваткой памяти для JVM. Зачем...