
В этой статье мы расскажем, что такое корпоративное хранилище данных, зачем оно нужно и как устроено. Еще рассмотрим основные достоинства и недостатки Data Warehouse, а также чем оно отличается от озера данных (Data Lake) и как традиционная архитектура КХД может использоваться при работе с большими данными (Big Data). Где хранить...

Мы уже рассказывали про профессиональный стандарт бизнес-аналитика – руководство BABOK и его значимость в области больших данных. Сегодня рассмотрим еще 3 подобных свода знаний, которые полезны для архитектора, разработчика, менеджера, инженера, исследователя и аналитика Big Data: PMBOK, SWEBOK и DMBOK. А также разберем, что такое EABOK и насколько это применимо...
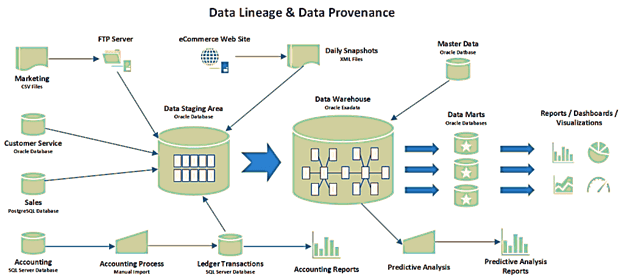
В этой статье мы продолжим разговор про основы управления данными и рассмотрим, что такое data provenance и data lineage, чем похожи и чем отличаются эти понятия. Также разберем, почему эти термины особенно важны для Big Data, какие инструменты помогают работать с ними, а также при чем здесь GDPR. Что такое...

Управление данными не сводится к выделению роли дата стюарда и обеспечению Data Quality. Сегодня мы расскажем, что такое мастер-данные, как искусственный интеллект помогает решать проблемы управления НСИ и почему эффективный Master Data Management (MDM) особенно важен в мире Big Data. Что такое мастер-данные или зачем управлять НСИ Начнем с определения:...
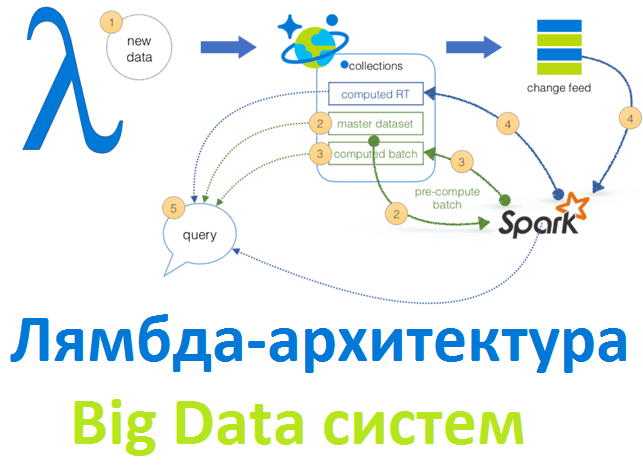
Рассматривая основы больших данных, сегодня мы расскажем лямбда-архитектуру, одну из двух главных подходов к построению Big Data систем. Читайте в нашей статье, зачем нужна эта концепция и как она работает, а также при чем тут машинное обучение, интернет вещей, Apache Spark и Hadoop. Что такое Лямбда-архитектура и зачем она нужна...

Завершая цикл публикаций о применении больших данных и машинного обучения в оперативно-розыскной деятельности и других задачах МВД, сегодня мы рассмотрим перспективы этих технологий: заменят ли они живых полицейских и когда это произойдет. Спойлер: еще не скоро. Читайте в нашей статье про доверие к Big Data и Machine Learning для их...

Чтобы зарядить вас оптимизмом и в очередной раз показать практическую пользу от технологий больших данных, машинного обучения и других методов искусственного интеллекта, сегодня мы расскажем, как Big Data и Machine Learning предупреждают аварии, диагностируют смертельные болезни на ранних стадиях и помогают найти без вести пропавших людей. Большие данные и машинное...

Продолжая разговор о том, как технологии Big Data и Machine Learning борются с нелегитимным оборотом денег, сегодня мы рассмотрим сферу страхования. Читайте в нашей статье, как графовая аналитика больших данных и алгоритмы машинного обучения помогают страховым компаниям и сотрудникам полиции раскрывать мошеннические схемы и предупреждать правонарушения. Страшно аж жуть: рынок...
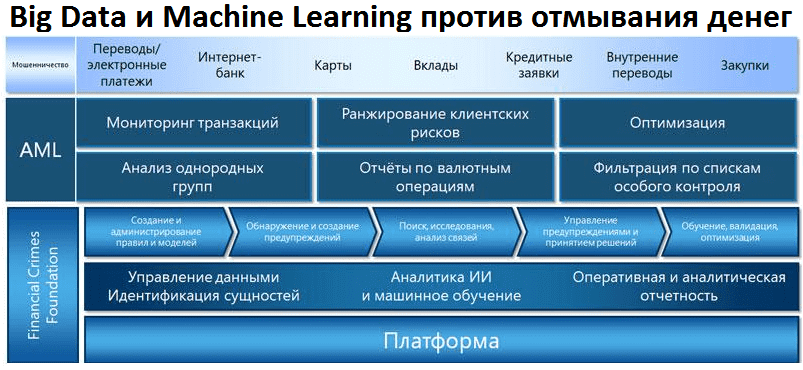
Сегодня мы продолжим разговор про антифрод-системы и расскажем, как аналитика Big Data и модели Machine Learning помогают бороться с отмыванием денег. Читайте в нашей статье, зачем нужен светофор транзакций, что такое AML-системы и при чем тут графы больших данных. Светофор транзакций и Big Data в антифрод-системах Сначала рассмотрим, как работают...

В продолжение темы про предупреждение и раскрытие преступлений с помощью ИТ, сегодня мы расскажем, что такое антифрод-системы, зачем они нужны и где используются. А также рассмотрим, какова роль технологий Big Data и Machine Learning в таких средствах обнаружения мошенничества. Читайте в нашей статье, почему как большие данные и машинное обучение...

В этой статье мы продолжим рассматривать примеры использования технологий Big Data и Machine Learning в задачах профилактики и расследовании преступлений. Сегодня читайте, как машинное обучение и большие данные позволяют предупредить массовые убийства и выявить закладки наркотиков с помощью методов графовой аналитики и автоматической оценки сообщений в соцсетях. Machine Learning против...

Цифровизация и искусственный интеллект повышают эффективность не только коммерческого бизнеса, промышленных производств и государственных услуг. В этой статье мы расскажем, как технологии больших данных (Big Data) и машинное обучение (Machine Learning) борются с незаконным оборотом наркотиков. Читайте в сегодняшнем материале 3 примера практического использования науки о данных (Data Science) в...

Сегодня мы расскажем про интерактивные карты преступности в России и за рубежом, а также рассмотрим, как технологии больших данных (Big Data) и машинного обучения (Machine Learning) помогают обнаружить и предупредить городские преступления. Читайте в этой статье, что такое Crime Mapping, где уже запущены биометрические системы идентификации подозреваемых и как дроны...

В контексте темы бережливого производства в ИТ, сегодня мы расскажем про анализ требований к разработке ПО в условиях Agile-подходов к организации работы и соответствия жестким рамкам отечественных ГОСТов и зарубежных стандартов. Читайте в нашей статье, что говорит BABOK по этому поводу и когда нужно запускать процесс создания программной документации, чтобы...
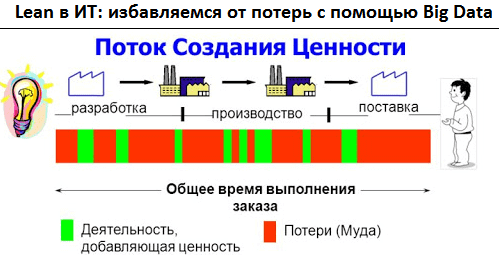
Продолжая разговор про бережливое производство в ИТ, сегодня мы рассмотрим виды потерь и источники их возникновения, а также поговорим, как принципы Lean помогают бизнесу избавиться от муда, мури и мура средствами больших данных (Big Data). 8 видов потерь в Lean с примерами из ИТ Прежде всего, поясним значение понятий муда,...
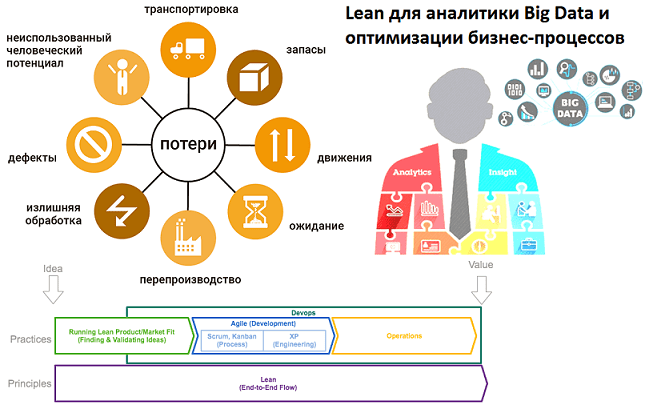
Вчера мы рассмотрели, что такое функционально-стоимостный анализ (ФСА) и как этот метод позволяет оценить бизнес-процессы в денежном выражении. Однако, результаты ФСА, в первую очередь, ориентированы на оптимизацию с точки зрения финансов, а не организации и технологий. Исправить ситуацию помогут принципы бережливого производства (Lean). Сегодня мы расскажем об одном из них...

В этой статье мы расскажем, что такое функционально-стоимостный анализ, как он связан с концепцией бережливого производства (Lean) и каким образом позволяет оценить и оптимизировать бизнес-процессы. Также рассмотрим, почему этому методу стоит уделить внимание при изучении основ цифровизации, а также в рамках проектов по внедрению технологий больших данных (Big Data). Что...
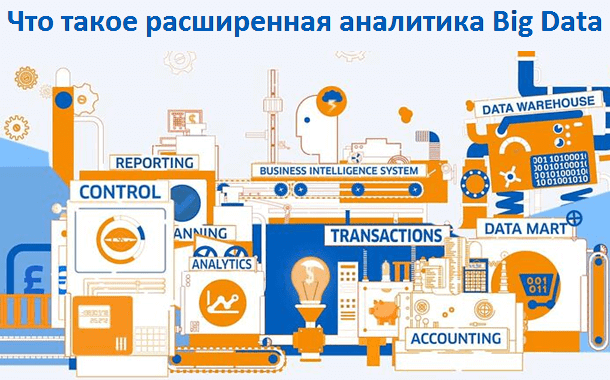
Сегодня мы рассмотрим, что такое расширенная аналитика и дополненное управление данными, как они связаны с цифровизацией бизнеса и почему исследовательское бюро Gartner включило эти технологии в ТОП-10 самых перспективных трендов 2020 года. Читайте в нашей статье, как машинное обучение (Machine Learning) помогает аналитикам и руководителям находить во множестве больших данных...
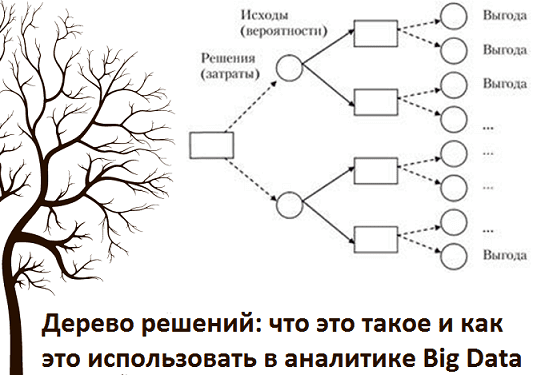
Продолжая насыщать курс Аналитика больших данных для руководителей важными понятиями системного анализа, сегодня мы рассмотрим, что такое дерево решений (Decision Tree). А также расскажем, как этот метод Data Mining и предиктивной аналитики используется в машинном обучении, экономике, менеджменте, бизнес-анализе и аналитике больших данных. Как растут деревья решений: базовые основы Начнем...

11 марта 2020 года ВОЗ объявила о пандемии нового коронавируса (Covid-19), который в декабре 2019 был впервые обнаружен в китайском мегаполисе Ухань. С тех пор вирус стремительно распространяется по всей планете, вызывая острые респираторные заболевания. Сегодня мы расскажем, почему, несмотря на повсеместные карантины и обвал мировых рынков, все не все...