
В этой статье разберем кейс построения экосистемы управления Big Data с озером данных на примере федеральной фармацевтической сети - российской Ассоциации независимых аптек (АСНА). Читайте в этом материале, зачем фармацевтическому ритейлеру большие данные, с какими трудностями столкнулся этот проект цифровизации и как открытые технологии (Arenadata Hadoop, Apache Spark, NiFi и...

Сегодня поговорим про еще один open-source проект от Apache Software Foundation – Bigtop, который позволяет собрать и протестировать собственный дистрибутив Hadoop или другого Big Data фреймворка, например, Greenplum. Читайте в нашей статье, что такое Apache Bigtop, как работает этот инструмент, какие компоненты он включает и где используется на практике. Что...

Мы уже затрагивали тему корпоративных хранилищ данных (КХД), управления мастер-данными и нормативно-справочной информаций (НСИ) в контексте технологий Big Data. В продолжение этого, сегодня рассмотрим, что такое профилирование данных, зачем это нужно, при чем тут озера данных (Data Lake) и ETL-процессы, а также прочие аспекты инженерии и аналитики больших данных. Что...

Продолжая разговор про интеграцию информационных систем с помощью стриминговой платформы, сегодня мы рассмотрим преимущества event streaming архитектуры на примере Apache Kafka. Также читайте в нашей статье про 5 ключевых сценариев использования Кафка в потоковой обработке событий: от IoT/IIoT до микросервисного разделения в системах аналитики больших данных (Big Data) и машинного...

В этой статье поговорим про интеграцию информационных систем: обсудим SOA и ESB-подходы, рассмотрим стриминговую архитектуру и возможности Apache Kafka для организации быстрого и эффективного обмена данными между различными бизнес-приложениями. Также обсудим, что влияет на архитектуру интеграции корпоративных систем и распределенных Big Data приложений, что такое спагетти-структура и почему много сервисов...

Сегодня мы расскажем, почему каждый Big Data специалист должен знать этот язык программирования и как «Школа Больших Данных» поможет вам освоить его на профессиональном уровне. Читайте в нашей статье, кому и зачем нужны корпоративные курсы по Python в области Big Data, Machine Learning и других методов Data Science. Чем хорош...

В продолжение темы про проявление Agile-принципов в Big Data системах, сегодня мы рассмотрим, как DevOps-подход отражается в использовании Apache Kafka. Читайте в нашей статье про кластерную архитектуру коннекторов Кафка и KSQL – SQL-движка на основе API клиентской библиотеки Kafka Streams для аналитики больших данных, о которой мы рассказывали здесь. Из...

Мы уже рассказывали, как некоторые принципы Agile отражаются в Big Data системах. Сегодня рассмотрим это подробнее на примере коннекторов Кафка и KSQL – SQL-движка для Apache Kafka. Он который базируется на API клиентской библиотеки для разработки распределенных приложений с потоковыми данными Kafka Streams и позволяет обрабатывать данные в режиме реального...
Сегодня рассмотрим облачные сервисы и платформы ELK-стека, которые позволяют использовать все функциональные преимущества Elasticsearch с Kibana без развертывания собcтвенной ИТ-инфраструктуры (on-demand), интегрируя их с другими облачными приложениями. Читайте в нашей статье, что такое Elastic Cloud Enterprise и чем это отличается от Amazon Elasticsearch Service, Open Distro и других cloud-решений. Такие...

В этой статье поговорим про интеграцию ELK-стека с экосистемой Apache Hadoop: зачем это нужно и с помощью каких средств можно организовать обмен данными между HDFS и Elasticsearch, а также при чем здесь Apache Spark, Hive и Storm. Еще рассмотрим несколько практических примеров, где реализована такая интеграция Big Data систем для...

Продолжая разговор про интеграцию Elasticsearch с Кафка, сегодня мы рассмотрим, с какими ошибками можно столкнуться при практическом использовании Apache Kafka Connect. Также рассмотрим, как Kafka Connect поддерживает обработку ошибок и какие параметры нужно настроить для непрерывной передачи данных или ее остановки в случае сбоя. 2 варианта обработки ошибок в Kafka...

Сегодня поговорим, как связать Elasticsearch с Apache Kafka: рассмотрим, зачем нужны коннекторы, когда их следует использовать и какие особенности популярных в Big Data форматов JSON и AVRO стоит при этом учитывать. Также читайте в нашей статье, что такое Logstash Shipper, чем он отличается от FileBeat и при чем тут Kafka...

В этой статье рассмотрим несколько примеров по аналитике больших данных в Elasticsearch (ES), а также разберем возможности алгоритмов машинного обучения в ELK Stack. Читайте, как использовать NoSQL-СУБД ES в качестве озера данных для проверки различных бизнес-гипотез с помощью Machine Learning, показывая результаты моделирования в интерфейсе Kibana: практическая аналитика Big Data....

Вчера мы рассказывали про самые известные утечки Big Data с открытых серверов Elasticsearch (ES). Сегодня рассмотрим, как предупредить подобные инциденты и надежно защитить свои большие данные. Читайте в нашей статье про основные security-функции ELK-стека: какую безопасность они обеспечивают и в чем здесь подвох. Несколько cybersecurity-решений для ES под разными лицензиями...

Продолжая разговор про Elastic Stack, сегодня мы рассмотрим проблемы cybersecurity в Elasticsearch: разберем самые известные утечки данных за последнюю пару лет и поговорим, кто и как обнаруживает подобные инциденты. Читайте в нашей статье, какие средства используют «белые хакеры» для поиска уязвимостей в Big Data системах и что общего между Росгвардией...

Сегодня рассмотрим основные преимущества и недостатки ELK-стека. Читайте в этой статье, чем хороши Elasticsearch с Logsatsh и Kibana, а также каковы их основные недостатки и ограничения для использования в реальных Big Data проектах. Также мы собрали для вас несколько практических примеров, где и как используется Elasticsearch в интернет-магазинах, банках и...
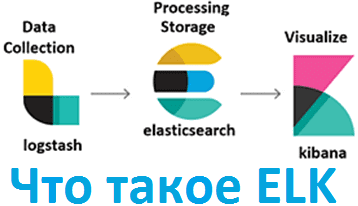
В этой статье рассмотрим ELK-инфраструктуру: разберем, зачем поисковый движок Elasticsearch использует сборщик логов Logstash и при чем здесь визуальный интерфейс Kibana. Также поговорим, в каких Big Data проектах используются эти системы и для чего. Зачем вам Elasticsearch: полнотекстовый поиск по Big Data Чтобы определить, почему деньги пропали с банковского счета или...

Вчера мы разобрали, чем хорош ClickHouse и почему. Сегодня рассмотрим обратную сторону скорости, расширяемости и других преимуществ этой аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Также читайте в нашей статье, как обойти недостатки и ограничения этой системы или понизить степень их влияния на...

Сегодня рассмотрим основные преимущества ClickHouse – аналитической СУБД от Яндекса для обработки запросов по структурированным большим данным в реальном времени. Читайте в нашей статье, чем еще хорош Кликхаус, кроме высокой скорости, и почему эту систему так любят аналитики, разработчики и администраторы Big Data. Чем хорош ClickHouse: главные преимущества Напомним, основным...

Интеграционный движок Kafka Engine для потоковой загрузки данных в ClickHouse из топиков Кафка – наиболее популярный инструмент для связи этих Big Data систем. Однако, он не единственное средство интеграции Кликхаус с Apache Kafka. Сегодня рассмотрим, как еще можно организовать потоковую передачу больших данных от самого популярного брокера сообщений в колоночную...