Зачем Trino использует внешние таблицы при запросах к данным в объектных хранилищам и удаленных файловых системах, чем они отличаются от внутренних и как повысить производительность таких SQL-запросов с помощью кэширования. Доступ из Trino к данным в объектных хранилищах Помимо реляционных и нереляционных баз данных, Trino позволяет делать распределенные запросы и...

Как реализовать концепцию обратного давления (backpressure) в потоковой обработке событий с Apache Kafka: настройка конфигураций на стороне приложений-продюсеров и потребителей, а также мониторинг системных метрик. Обратное давление при публикации событий в Kafka Мы уже писали о том, зачем нужна концепция обратного давления (backpressure) в потоковой передаче событий и как она...
Зачем и как Apache Flink использует удаленный вызов процедур, с помощью каких технологий реализуется это RPC-взаимодействие и почему в 2023 году Akka заменен на Pekko. Удаленный вызов процедур в Apache Flink Мы уже рассказывали, как RPC-вызовы используются для коммуникации между компонентами Spark. Удаленный вызов процедур используется и в Apache Flink,...

Что общего между Trino и dbt, чем они отличаются и в каких случаях выбирать тот или иной инструмент для инженерии и анализа данных. Краткий ликбез для начинающего дата-инженера и аналитика. Сходства и отличия Trino и dbt Trino и dbt (Data Build Tool) — это два популярных инструмента с открытым исходным...
Чем полезна поддержка gRPC в Clickhouse и как ее реализовать: разбираем интерфейс удаленного вызова процедур на примере потоковой вставки событий пользовательского поведения из Kafka в таблицу колоночной базы данных со стриминговым выводом. Поддержка gRPC в ClickHouse ClickHouse поддерживает gRPC – фреймворк от Google и система удаленного вызова процедур с открытым...
Что не так с классическими ETL/ELT-конвейерами транзакционных и аналитических систем в гибридное хранилище LakeHouse, и как дата-инженеры платформы Confluent хотят решить эти проблемы с помощью Tableflow, передавая события из Kafka в таблицы Iceberg. Очередная попытка унификации пакетной и потоковой парадигмы Чтобы обеспечивать потребности современного бизнеса в пакетной и потоковой аналитике,...
Зачем Trino статистика таблиц, как MPP-движок создает план выполнения SQL-запросов к разным источникам данных, применяя CBO-оптимизацию, а также полную или частичную передачу обработки предикатов в базовое хранилище. Внутренние оптимизации Trino В отличие от MapReduce с материализацией промежуточных результатов на диске, в массово-параллельной архитектуре Trino промежуточные результаты передаются между рабочими узлами...
Что не так с Apache Zookeeper и почему разработчики ClickHouse решили заменить его на встроенный сервис синхронизации метаданных на базе RAFT-протокола с линеаризацией записи и чтения. Как работает ClickHouse Keeper и где его настроить. Что не так с Apache Zookeeper Многие распределенные системы, которые состоят из нескольких узлов, для обеспечения...
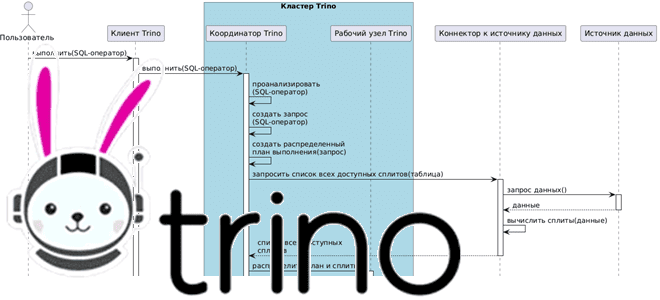
Как взаимодействуют рабочие узлы Trino между собой и с координатором кластера, а также с клиентскими приложениями и драйверами при выполнении SQL-запросов к данным из внешних источников без их фактического копирования. Последовательность выполнения запросов в кластере Trino Продолжая разбираться с Trino, сегодня рассмотрим, как этот аналитический движок с массово-параллельной архитектурой (MPP,...
Как без копирования анализировать данные из разных источников в реальном времени с помощью SQL-запросов: каталоги и коннекторы Trino. Коннекторы Trino: как они работают и что настроить в каталоге Вчера мы разобрали, как устроен кластер Trino – аналитического движка с массово-параллельной архитектурой (MPP, Massively Parallel Processing), который обрабатывает данные на нескольких...
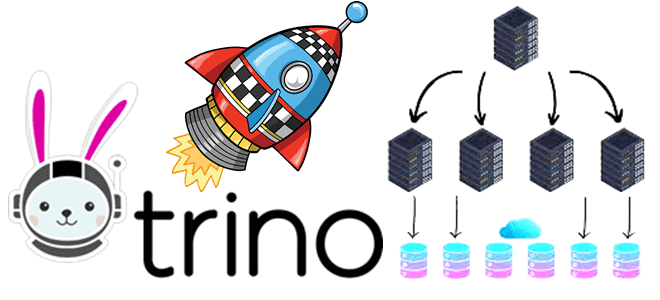
Как с помощью SQL-запросов анализировать огромные объемы данных из множества источников в реальном времени без их фактического копирования. Архитектура и принципы работы MPP-движка Trino. Что такое Trino и зачем он нужен Массово-параллельная архитектура (MPP, Massively Parallel Processing) с разделяемой памятью, когда система состоит из отдельных узлов, которые вместе выполняют одну...

Чем BranchPythonOperator отличается от ShortCircuitOperator, что и когда выбирать для ветвления DAG в Apache Airflow: принципы работы и примеры использования. Ветвления DAG в Apache AirFlow с помощью операторов Чтобы поддерживать реализацию сложных конвейеров обработки данных, в Apache Airflow есть соответствующие механизмы ветвления графа задач, т.е. DAG (Directed Acyclic Graph). По...
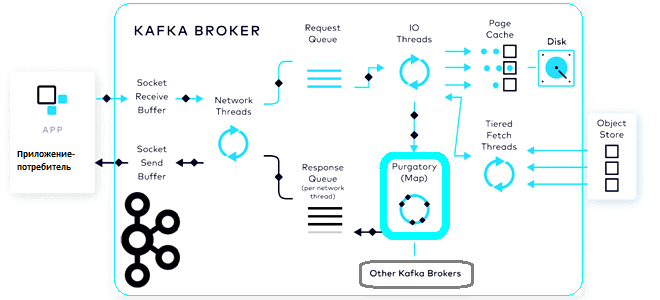
Что такое чистилище запросов, зачем это в потоковой обработке данных, при чем здесь иерархические колеса времени и как эта структура данных помогает Apache Kafka выполнять сотни тысяч асинхронных операций в секунду. Что такое чистилище запросов и зачем это в Kafka Будучи сложной распределенной системой, Apache Kafka реализует несколько типов запросов,...

Как передать JSON-документы из топика Kafka в Elasticsearch, используя OpenSearch Sink Connector. Подробная демонстрация с настройкой и регистрацией коннектора в Kafka Connect. Настройка sink-коннектора и отправка в Kafka Connect Как передать данные из Kafka в Elasticsearch, я уже показывала здесь, развернув экземпляр Kafka в облаке на платформе Upstash. Однако, с...
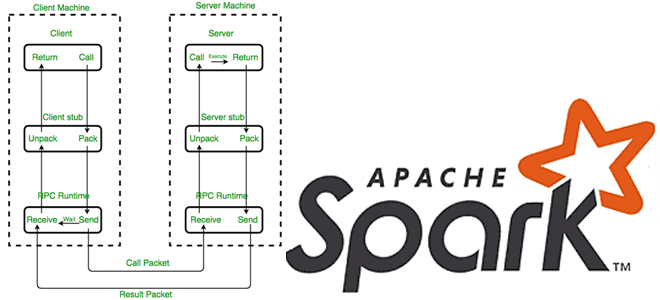
Как Apache Spark использует протокол удаленного вызова процедур для межпроцессного взаимодействия, какие параметры отвечают за эффективное выполнение RPC-запросов и где их настроить. RPC в Apache Spark Распределенный характер Apache Spark предполагает взаимодействие между компонентами, расположенными на разных узлах, например, драйвер на мастер-узле взаимодействует с исполнителями на рабочих узлах. В качестве...
Сегодня я на практическом примере покажу тонкости настройки конфигураций JDBC-коннектора источника, передающий новые записи из таблицы PostgreSQL в топик Apache Kafka. Настройка JDBC-коннектора и отправка в Kafka Connect Как я упоминала вчера, помимо CDC-коннектор Debezium, передать данные из реляционной базы данных PostgreSQL в Apache Kafka, также есть JDBC-коннектор от Confluent:...

Что общего между Kafka Connect JDBC Source и PostgreSQL CDC Source V2 (Debezium), чем отличаются эти коннекторы и как добавить JDBC-драйвер для передачи данных из PostgreSQL в Apache Kafka на Docker. Коннекторы Kafka к реляционным БД от Confluent О том, что CDC-коннектор Debezium позволяет организовать интеграцию Apache Kafka с реляционной...

Что такое Python-декораторы в Airflow, зачем они нужны, какие они бывают и чем полезны: ликбез по TaskFlow API на практическом примере DAG. Что такое Python-декораторы в Airflow и какие они бывают Будучи написанным на Python, Apache Airflow использует именно этот язык в качестве средства разработки дата-конвейеров. После определения функции в...
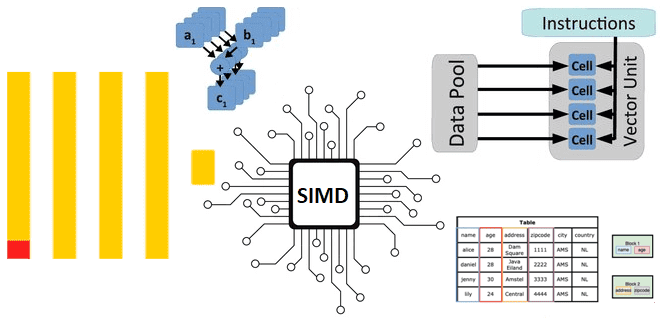
Как ClickHouse реализует параллельные векторные вычисления над большим объемом данных на любых аппаратных платформах: диспетчеризация ЦП для выполнения SIMD-инструкций в сложных функциях. Реализация векторных вычислений в ЦП Как мы уже отмечали здесь, ClickHouse имеет встроенную поддержку векторных вычислений, когда при выполнении одной инструкции процессора производится не одна операция, а одновременно...

6 ноября 2024 года опубликован очередной выпуск самой популярной платформы потоковой передачи событий. Что нового в Apache Kafka 3.9: динамические кворумы KRaft, улучшения многоуровневого хранилища, полезные фичи Kafka Streams и Kafka Connect. Динамические кворумы KRaft Релиз Apache Kafka 3.9 официально назван последним, который использует ZooKeeper в качестве службы синхронизации метаданных....