Как протестировать работу приложения Apache Flink, используя SQL-клиентов, Table API, тестовые наборы операторов и режим локального мини-кластера. Разбираем особенности ручного и автоматизированного тестирования Flink SQL на уровне отдельных функций, модулей и их интеграционного взаимодействия. Модульное и интеграционное тестирование приложений Apache Flink SQL Тестирование является неотъемлемой частью любого процесса разработки ПО,...

Сегодня в рамках обучения администраторов SQL-on-Hadoop рассмотрим, как защитить данные в кластере Apache HBase от несанкционированного доступа. Аутентификация и авторизация пользователей, операторы управления доступом к таблицам, метки видимости и шифрование данных. Механизмы защиты данных в Apache HBase Как и любое хранилище, колоночно-ориентированная мультиверсионная NoSQL-СУБД типа key-value Apache HBase, которая работает...
Недавно мы упоминали GraphQL как мощный и гибкий язык запросов к данным, хранящимся в графовых СУБД. Сегодня рассмотрим, чем эта технология может быть полезна в проектах Machine Learning, какие сложности с ней связаны и как их решить с помощью MLOps. GraphQL для ML: возможности и примеры Не будучи в чистом...
Какие подходы позволяют увеличить емкость СУБД, чтобы повысить объем хранящихся в ней данных и ускорить вычисления. Разбираем тонкости масштабирования распределенной базы данных с массово-параллельной обработкой Greenplum: действия администратора по добавлению новых узлов в кластер. Как увеличить емкость базы данных: 4 подхода к масштабированию Чтобы увеличить емкость СУБД, т.е. объем хранимых...

Продолжая разговор про языки запросов к графовым базам данных, сегодня познакомимся с GSQL, который поддерживается в MPP-СУБД TigerGraph. Как работает эта распределенная NoSQL-база данных и каким образом реализует ACID-требования к транзакциям в операциях с графами. Архитектура и принципы работы графовой MPP-СУБД TigerGraph — это распределенное графоориентированное хранилище данных с массивно-параллельной...
Как установить и отследить в Apache AirFlow зависимости экземпляров задач друг от друга, узнать о запуске конкретной задачи в DAG, использовать обратные вызовы и правила триггеров, а также шаблоны и макросы Jinja. Полезные примеры управления ETL-конвейерами для дата-инженера в GUI и CLI-интерфейсах. Как узнать время запуска последнего экземпляра задачи? Будучи...

Как повысить скорость выполнение SQL-запросов в Spark-приложениях, используя Gluten – новый вычислительный движок, объединяющий несколько векторизированных механизмов выполнения с поддержкой аппаратных ускорителей. Что такое Gluten и как он появился в Apache Spark Когда данных много, их обработка может длиться долго. Чтобы ускорить вычисления с Big Data, разработчики распределенных приложений и...
Недавно мы писали об изменении статуса и улучшении протокола KRaft в Apache Kafka 3.3. Сегодня погрузимся в эту тему чуть глубже и рассмотрим, как отказ от Zookeeper влияет на количество разделов и возможность одного и того же кластера Kafka с одним набором топиков обслуживать разные типы приложений в различных бизнес-сценариях....
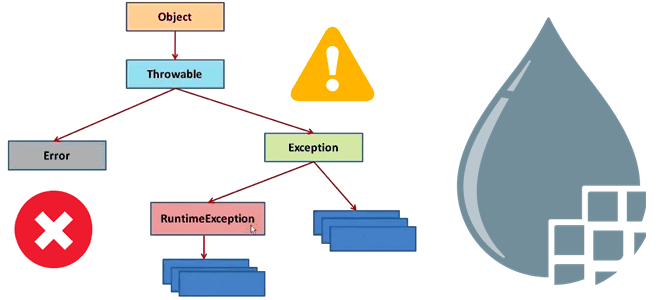
Сегодня посмотрим на Apache NiFi с точки зрения разработчика Data Flow и разберем ключевые нюансы обработки ошибок, генерации исключений и лучшие практики работы с ними для практических задач дата-инженерии. Исключения процессоров Apache NiFi При том, что Apache NiFi имеет множество готовых процессоров для подключения ко внешним источникам или приемникам данных,...
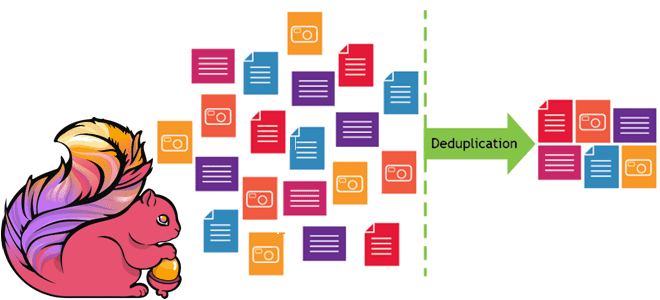
Чем опасны дубли данных при их потоковой обработке и как реализовать дедупликацию в Apache Flink SQL. Смотрим на практическом примере для обучения дата-инженеров и разработчиков распределенных приложений. Потоковая дедупликация данных в Apache Flink SQL Apache Flink можно назвать уникальный фреймворком для разработки распределенных приложений в области Big Data, который унифицирует...
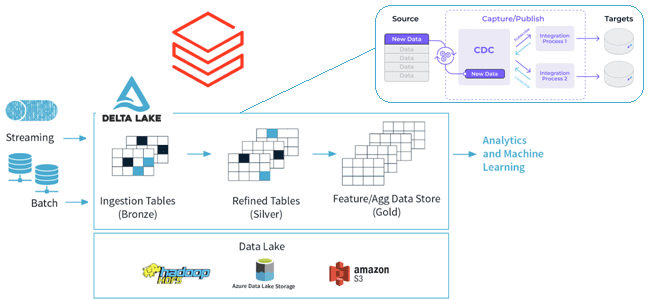
Как реализовать CDC для Delta Lake: разбираемся с функцией Change Data Feed от Databricks, которая позволяет быстро узнать обо всех изменениях строк в дельта-таблицах озера данных. Польза и принципы работы CDF для дата-инженера и архитектора данных. CDC для Delta Lake Идея сбора и обработки не всего объема данных, а только...
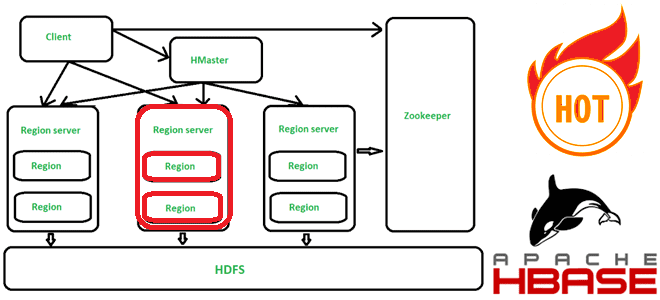
Что такое горячие точки в Apache HBase, почему они возникают, чем опасны и как их избежать. Для этого заглянем под капот NoSQL-хранилища, чтобы разобраться с особенностями хранения данных по ключу строки. Что такое горячие точки в кластере Apache HBase и почему они случаются Apache HBase представляет собой колоночно-ориентированное мультиверсионное хранилище...
Почему в проектах машинного обучения накапливается технический долг, каковы главные факторы его появления и каким образом MLOps устраняет проблемы, связанные с разработкой, тестированием, развертыванием и сопровождением систем Machine Learning. Скрытый технический долг в ML-системах Технический долг означает дополнительные затраты, возникающие в долгосрочной перспективе, с которыми сталкивается команда, в результате выбора...

В 7-м релизе Greenplum, о котором мы писали здесь и здесь, вышло много изменений. Одним из них стал целый набор обновленных функций, связанных с партиционированием таблиц. Читайте далее, как Greenplum стал еще на шаг ближе к PostgreSQL и что изменилось в части синтаксиса SQL-запросов. Управление разделами в Greenplum и PostgreSQL...
Для продвижения нашего нового курса по графовым алгоритмам в бизнес-приложениях, сегодня рассмотрим 5 самых известных языков запросов для управления данными графов. Что общего у GraphQL, Gremlin, Cypher, SPARQL и AOL, а также чем они отличаются. GraphQL Языки запросов, используемые для управления данными графов (GQL, Graph Query Language), определяют способ извлечения...
Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим несколько лучших практик разработки DAG в Apache AirFlow, а также поговорим про операторы, которые обеспечивают повторное использование и настраиваемый запуск задач в конвейере обработки данных. Еще 7 полезных практик работы с Apache AirFlow для дата-инженера В дополнению к тегированию...

Мы уже писали, как ускорить выполнение заданий Spark SQL по чтению данных из JDBC-источников. В продолжение этой важной темы для обучения дата-инженеров и разработчиков распределенных приложений, сегодня рассмотрим, зачем настраивать опции функции spark.read() и как это сделать наиболее эффективно. Скорость выполнения SQL-запросов и параметры чтения данных из JDBC-источников в Apache...

23 января 2023 года вышел очередной релиз самой популярной платформы потоковой передачи событий. Разбираемся с новинками Apache Kafka 3.3.2: готовность протокола KRaft, новый API для метрик, разделитель по умолчанию для записей без ключа, исправления и улучшения, важные для дата-инженера и администратора кластера. Apache Kafka 3.3.2: главные новинки и изменения Минорный...
Сегодня познакомимся с еще одним полезным инструментом Apache NiFi: как использовать предметно-ориентированный язык RecordPath, чтобы получить доступ к полям записи. Смотрим на примере процессора UpdateRecord. Что такое RecordPath в Apache NiFi Apache NiFi имеет множество готовых процессоров, способных принимать, обрабатывать, маршрутизировать, преобразовывать и доставлять данные любого формата и размера благодаря...
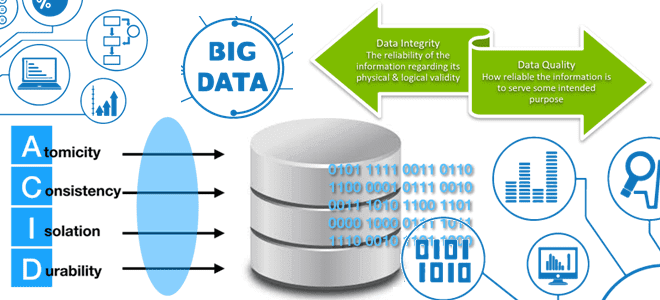
Чем целостность данных отличается от их качества и как реализуются ACID-свойства распределенных транзакций в Big Data системах. Разбираем понятия и технологии, важные для обучения ИТ-архитекторов и дата-инженеров. Целостность и качество данных: versus или вместе? Целостность данных и качество данных — связанные, но разные понятия, важные для дата-инженера. Целостность описывает точность...