В продолжение разговора о применении технологий Big Data и Machine Learning в рекламе и маркетинге, сегодня рассмотрим архитектуру системы прогнозирования конверсии рекламных объявлений. Читайте далее, как организовать предиктивную аналитику больших данных на Apache Kafka и компонентах ELK-стека (Elasticsearch, Logstash, Kibana), почему так важно тщательно подготовить данные к машинному обучению, какие...
Сегодня поговорим про особенности построения конвейеров машинного обучения в Apache Spark. Читайте далее, как Spark MLLib реализует идеи MLOps, что такое трансформеры и оценщики, из чего еще состоит Machine Learning pipeline, как он работает с кодом на Scala, Java, Python и R, а также каковы условия практического использования методов fit(),...

Чтобы сделать самостоятельное обучение технологиям Big Data по статьям нашего блога еще более интересным, сегодня мы предлагаем вам простой интерактивный тест по основам больших данных, включая администрирование кластеров, инженерию конвейеров и архитектуру, а также Data Science и Machine Learning. Тест по основам больших данных для новичков В продолжение темы,...
Вчера мы говорили про промышленный Machine Learning в больших данных и рассматривали проблемы микросервисной архитектуры в системах машинного обучения. Продолжая разбирать, как Feature Store повышает эффективность MLOps-процессов, сокращая цикл разработки согласно Agile-идеям, сегодня мы приготовили для вас краткий обзор хранилища признаков StreamSQL. Читайте далее, что такое StreamSQL, как оно устроено,...
Сегодня рассмотрим, когда микросервисные архитектуры не подходят для систем машинного обучения и какие технологии Big Data следует использовать в этом случае. В этой статье мы расскажем, что такое Feature Store, как это хранилище признаков для моделей Machine Learning повышает эффективность MLOps-процессов и сокращает цикл разработки ML-систем, а также при чем...

Сегодня поговорим про ETL-процессы в мире Big Data на примере построения непрерывного конвейера поставки больших данных о транзакциях для сервисов машинного обучения. Читайте далее, из чего состоит типичная архитектура такой системы на базе Apache Kafka, Spark, HBase и Hive, а также почему большинство ETL-инструментов не подходят для потоковой передачи событий...

Обработка данных является одной из самых первоочередных задач анализа Big Data. Сегодня мы расскажем о самых полезных преобразованиях PySpark, которые можно выполнить над столбцами. Читайте далее, как привести значения к 0 или 1, как преобразовать из строк в числа и обратно, а также как обработать недостающие значения(Nan) с примерами в...

Продолжаем говорить о NLP в PySpark. После того как тексты обработаны: удалены стоп-слова и проведена лемматизация — их следует векторизовать для последующей передачи алгоритмам Machine Learning. Сегодня мы расскажем о 3-x методах векторизации текстов в PySpark. Читайте в этой статье: применение CountVectorizer для подсчета встречаемости слов, уточнение важности слов с...
Чтобы максимально приблизить обучение Airflow к практической работе дата-инженера, сегодня мы рассмотрим, какие еще есть альтернативы для оркестрации ETL-процессов и конвейеров обработки больших данных. Читайте далее, что такое Luigi, Argo, MLFlow и KubeFlow, где и как они используются, а также почему Apache Airflow все равно остается лучшим инструментом для оркестрации...

В этой статье мы рассмотрим комплексный конвейер (pipeline) обработки больших данных с помощью алгоритмов машинного обучения (Machine Learning) для системы речевого анализа Callinter от китайской компании Fano Labs. Apache Kafka играет ключевую роль в этом аналитическом конвейере, ежедневно обеспечивая бесперебойную стабильность и высокую производительность интеллектуальной обработки нескольких тысяч часов звонков....
В прошлый раз мы говорили о методах NLP в PySpark. Сегодня рассмотрим методы нормализации и стандартизации данных модуля ML библиотеки PySpark. Читайте в нашей статье: применение Normalizer, StandardScaler, MinMaxScaler и MaxAbsScaler для нормализация и стандартизации данных. Нормализация и стандартизация — методы шкалирования данных Нормализация (normalization) и стандартизация (standardization) являются методами...
Продолжая разговор про инженерию больших данных, сегодня рассмотрим, как построить ETL-pipeline на открытых технологиях Big Data. Читайте далее про получение, агрегацию, фильтрацию, маршрутизацию и обработку потоковых данных с помощью Apache NiFi, Kafka и Spark, преобразование JSON, а также обогащение и сохранение данных в Hive, HDFS и Amazon S3. Пример потокового...
Продолжая разговор про практическое применение Apache Kafka на примере организации рекомендательной системы Twitter, сегодня мы рассмотрим, как с помощью Kafka Streams был разработан конвейер сбора и агрегации данных для машинного обучения (Machine Learning). Читайте в нашей статье про особенности объединения больших данных через LeftJoin и InnerJoin в Apache Kafka Streams. Архитектура приложения...
Недавно мы рассказывали про преимущества event-streaming архитектуры с помощью Apache Kafka на примере The New York Times. В продолжение этой темы Apache Kafka, сегодня поговорим про использование этой Big Data платформы в Twitter для построения конвейера потоковой регистрации событий в рекомендательной системе на базе алгоритмов машинного обучения (Machine Learning). Как...
В прошлый раз мы говорили о решении задачи классификации в рамках Machine Learning с помощью PySpark MLlib. Сегодня рассмотрим задачу регрессии. Читайте далее: что такое линейная регрессия, L1 и L2 регуляризация, алгоритм подбора значений гиперпараметров Grid Search, а также применение кросс-валидации в PySpark. Датасет с домами на продажу Обучать модель...

PySpark позволяет работать не только с большими данными (Big data), но и создавать модели машинного обучения (Machine Learning). Сегодня мы расскажем вам о модуле ML и покажем, как обучить модель Machine Learning для решения задачи классификации. Читайте у нас: подготовка данных, применение логистической регрессии, а также использование метрик качеств в...

Озеро данных (Data Lake) на Apache Hadoop HDFS в мире Big Data стало фактически стандартом де-факто для хранения полуструктурированной и неструктурированной информации с целью последующего использования в задачах Data Science. Однако, недостатком этой архитектуры является низкая скорость вычислительных операций в HDFS: классический Hadoop MapReduce работает медленнее, чем аналоги на Apache...
Завершая цикл статей про MLOps, сегодня мы расскажем про 5 шаблонов практического внедрения моделей Machine Learning в промышленную эксплуатацию (production). Читайте далее, что такое Model-as-Service, чем это отличается от гибридного обслуживания и еще 3-х вариантов интеграции машинного обучения в production-системы аналитики больших данных (Big Data), а также при чем тут...
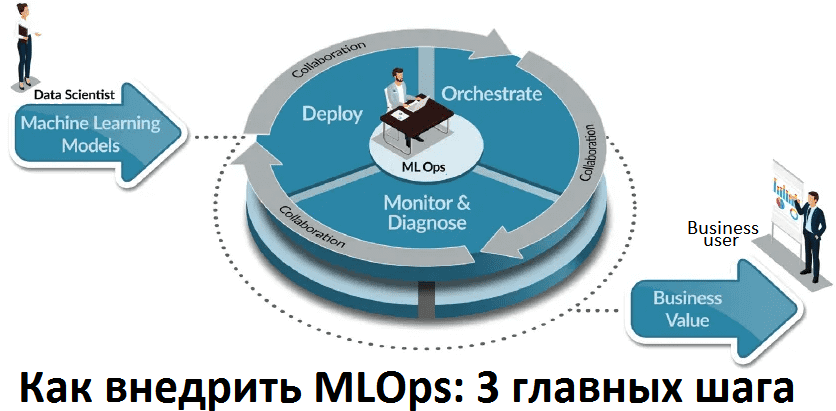
Рассказав, как оценить уровень зрелости Machine Learning Operations по модели Google или методике GigaOm, сегодня мы поговорим про этапы и особенности практического внедрения MLOps в корпоративные процессы. Читайте далее, какие организационные мероприятия и технические средства необходимы для непрерывного управления жизненным циклом машинного обучения в промышленной эксплуатации (production). 2 направления для...
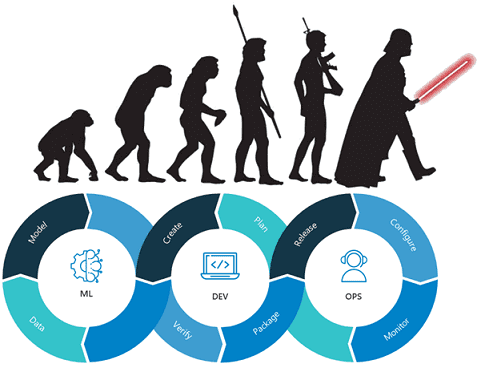
Недавно мы рассказывали про модель зрелости MLOps от Google. Сегодня рассмотрим альтернативную методику оценки зрелости операций разработки и эксплуатации машинного обучения, которая больше похоже на наиболее популярную в области управленческого консалтинга модель CMMI, часто используемую в проектах цифровизации. Читайте далее, по каким критериям измеряется Machine Learning Operations Maturity Model и...