Мы уже рассматривали особенности обработки вложенных структур данных на примере парсинга JSON-файлов с Apache Spark и Hive. Развивая эту тему, сегодня поговорим про перенос записей с вложенными массивами из топиков Apache Kafka в реляционные СУБД с пользовательскими SMT-преобразователями и JDBC-коннектором: кейс для разработчиков. Проблемы обработки сложных структур данных с JDBC-коннектором...
Вчера мы писали о недавно вышедшем свежем релизе Apache Kafka 3.1.0, который вышел в январе 2022 года. Сегодня рассмотрим, как безболезненно перейти на эту версию и избежать возможных побочных эффектов, связанных с некоторыми архитектурными изменениями платформы. Побочные эффекты и подводные камни обновления Напомним, в Apache Kafka 3.1.0 добавлена новая фича...

24 января 2022 года вышел новый релиз Apache Kafka. Главные новинки самой последней на сегодня стабильной версии 3.1.0: добавленные фичи, улучшения и исправленные баги краткий обзор для разработчиков распределенных приложений Kafka Streams и администраторов кластера этой платформы потоковой передачи событий. Новинки Apache Kafka 3.1.0 для администратора кластера В свежем релизе...
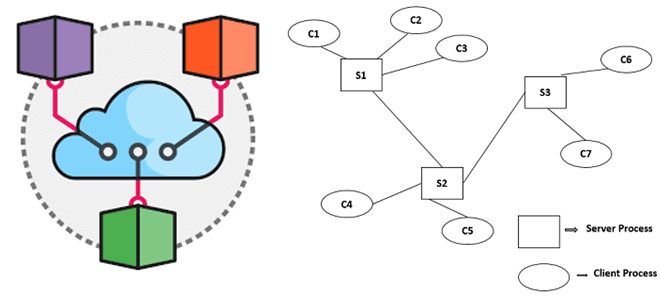
Недавно мы писали про архитектурный шаблон CQRS и его реализацию на базе Apache Kafka. В продолжение этой темы для обучения ИТ-архитекторов и разработчиков Big Data приложений, сегодня рассмотрим еще несколько популярных шаблонов проектирования распределенных систем: достоинства, недостатки, примеры реализации и способы их использования. Шаблоны проектирования распределенных систем: что это и...
Сегодня обсудим ключевые тренды развития дата-инженерии и инструментальные средства их реализации. Как это применяется на практике, рассмотрим на примере эволюции хранилища данных в индонезийской ИТ-компании Bukalapak, от локального кластера Apache HBase до Лямбда-архитектуры в облаке Google Cloud Platform с Kafka, Spark и AirFlow. 7 главных драйверов развития дата-инженерии В наши...
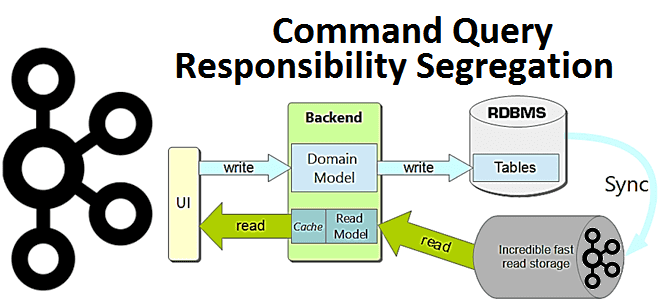
В этой статье для разработчиков распределенных приложений и ИТ-архитекторов разберем достоинства и недостатки паттерна проектирования CQRS, а также рассмотрим пример его реализации на Apache Kafka, Spring Cloud Stream и MongoDB. Что такое CQRS: основы проектирования архитектуры приложений Спрос на приложения, управляемые событиями, постоянно растет как для решения новых бизнес-задач, так...

Недавно мы писали про развертывание Apache Kafka на Kubernetes с помощью open-source проекта Strimzi. Сегодня рассмотрим, как обеспечить безопасный доступ к данным на таком кластере, применив различные методы аутентификации и авторизации. Лучшие практики cybersecurity на практическом примере. Постановка задачи: пример приложения с безопасным доступом к данным Напомним, Strimzi – это...

Чтобы сделать наши курсы для дата-инженеров еще более интересными, сегодня рассмотрим практический пример построения инфраструктуры для автоматической диагностики и исправления ошибок пакетной и потоковой обработки данных в Netflix. Комплексная система на базе Apache Spark, Kafka, Flink, Druid, сервисов AWS и других технологий Big Data. Предыстория: зачем Netflix разработал Pensive Обработка...

При том, что развертывание и эксплуатация Apache Kafka на Kubernetes требуют от администратора кластера много сил и времени, эта идея имеет массу достоинств, о чем мы писали здесь. Поэтому появляются новые инструменты, которые облегчают эти процессы, например, KubeMQ или Strimzi, который мы рассмотрим в этой статье. Что такое Strimzi и при...

3 ноября 2021 года компания Confluent, которая занимается продвижением и коммерциализацией Apache Kafka, выпустила новый релиз ksqlDB, который включает 20 исправленных ошибок и 18 добавленных фич. Самое интересное в выпуске 0.22.0: улучшенные push- и pull-запросы, а также source-потоки и таблицы. 20 исправленных багов и 18 новых фич в ksqlDB 0.22.0...

Сегодня разберем практический вопрос из обучения администраторов кластера Apache Kafka и разработчиков распределенных приложений. Про исключения в Kafka-приложениях: какие они бывают, почему случаются, с какими параметрами конфигурации связаны и что могут сказать о тонкостях потоковой обработки больших данных. Исключения и транзакции в Apache Kafka В ИТ под исключением понимается исключительная...

Чтобы сделать наши курсы по Apache Kafka для администраторов кластеров и разработчиков распределенных приложений еще более полезными, сегодня рассмотрим несколько полезных и значимых конфигурационных параметров этой платформы потоковой передачи событий. Что настроить на брокере, топике, продюсере и потребителе, как распараллелить потоки и обрабатывать транзакции. Настройка брокеров и потоков в Apache...
В этой статье разберем кейс бразильской фудтех-компании Ifood по реализации микросервисной ML-системы на Apache Kafka и serverless NoSQL-СУБД DynamoDB с пропускной способностью миллиарды сообщений в секунду. Сложности масштабирования микросервисов и оперативное чтение данных из Feature Store с помощью библиотеки Sarama – Go-клиента для Apache Kafka. Проблема микросервисов при множестве обращений...
В начале декабря 2021 года мир ИТ взволновала новость о критической уязвимости CVE-2021-44228 в библиотеке Apache Log4j. Разбираемся, что это такое и чем опасно для систем хранения и аналитики больших данных на Apache Hadoop, Kafka, Spark, Elasticsearch и Neo4j. Критическая уязвимость в библиотеке Apache Log4j: чем опасна CVE-2021-44228 9 декабря...

Недавно мы рассказывали про KubeMQ – stateless-сервис обмена сообщениями для Kubernetes, который может заменить собой сложное развертывание Apache Kafka на этой платформе управления контейнерами. Сегодня разберем, как устроен KubeMQ и сравним его с Apache Kafka по нескольким параметрам, наиболее интересным для разработчиков распределенных приложений и администраторов. Операторы и пользовательские ресурсы...

Сегодня разберем пример европейской логистической компании Sixfold, которая смогла увеличить пропускную способность своей системы мониторинга транспортных отгрузок на базе Apache Kafka и Kubernetes. Также рассмотрим, как дата-инженеры Sixfold справились с проблемами изоляции при последовательной обработке сообщений и транзакционной записи в топики Kafka с базами данных отдельных микросервисов на подах Kubernetes....
Мы уже писали о сложностях развертывания Apache Kafka на платформе управления контейнерами Kubernetes. Некоторые из этих проблем отлично решает KubeMQ – брокер очередей сообщений на Kubernetes. Зачем нужна очередная служба обмена данными, как она устроена и при чем здесь Kafka. Проблемы Kafka на Kubernetes и не только Сложная архитектура современных...

Вчера мы рассматривали коннектор Neo4j к Apache Spark, который позволяет строить конвейеры аналитики больших данных с применением графовых алгоритмов. Продолжая эту тему, сегодня разберем варианты интеграции Neo4j с Apache Kafka с помощью шаблонных запросов Cypher в плагине и коннектора от Confluent, а также от каких конфигурационных параметров зависит пропускная способность...

Недавно мы писали, что в новой версии Apache Flink 1.14, которая вышла в конце сентября 2021 года, сделаны попытки объединения потоковой и пакетной парадигм обработки данных. Сегодня рассмотрим, как подобное стремление к унификации реализуется на практике дата-инженерами фотохостинга Pinterest, которые используют Apache Flink как универсальный инструмент аналитики больших данных в...

Apache AVRO не случайно считается очень востребованным форматом и популярной системой сериализации данных, который активно в Kafka. Сегодня рассмотрим, как сериализуются данные в AVRO, каким образом это связано со структурами JSON и при чем здесь реестр схем Confluent. Еще раз про AVRO и сериализацию данных Apache Kafka часто используется в...