12
12 
Содержание
- Архитектура и философия: почему Apache Airflow стал стандартом
- Проблема. Почему Cron больше не справляется
- Философия направленных графов и магия идемпотентности
- Анатомия Apache Airflow - Как это работает под капотом
- Жизненный цикл задачи - от кода до исполнения
- Практика: поднимаем песочницу Apache Airflow в Docker за пять минут
- BashOperator против PythonOperator
- Чтение логов: как понять что пошло не так
- Частые затыки и как из них выбираться
- Помощь Cursor в документировании и отладке
- Референсные источники
Эта статья открывает наш цикл посвященный бесплатному курсу лекций по «Apache Airflow для новичков» и закладывает фундамент для осовения всей темы. Мы разберемся, зачем вообще нужен оркестратор, как Airflow устроен внутри и как его запустить за пять минут, чтобы начать первые эксперименты.
Архитектура и философия: почему Apache Airflow стал стандартом
Если вы когда-нибудь настраивали запуск скриптов через обычный системный планировщик задач вроде Cron, то наверняка сталкивались с ситуацией адской цепочки. Это когда один скрипт должен запуститься строго после того, как отработает другой, но первый внезапно упал из-за ошибки в данных, а второй все равно стартовал и наплодил пустых файлов. Или еще хуже: вы вообще не узнали, что что-то сломалось, пока вам не написали разгневанные пользователи отчетов.
Apache Airflow появился именно как ответ на этот хаос. Его создали в Airbnb, когда поняли, что управлять сотнями зависимых процессов вручную невозможно. В этой статье мы разберем, почему подход код как конфигурация стал золотым стандартом в дата-инженерии, и как именно работает мозг этого инструмента. Мы пройдем путь от понимания теории до запуска вашей первой рабочей песочницы в Docker.
Проблема. Почему Cron больше не справляется
Представьте стандартный рабочий процесс инженера данных: нужно выкачать лог из Kafka, сохранить его в облако S3, запустить Spark-задачу для обработки и в конце положить результат в аналитическую базу ClickHouse. В мире классических скриптов это выглядит как набор разрозненных записей в текстовом файле планировщика. У такого подхода нет общей памяти и нет понимания связей между задачами. Если Spark-задача зависнет и съест всю память, обычный планировщик просто попытается запустить следующий этап по расписанию, окончательно добив сервер.
Основные боли, которые лечит Airflow, кроются в прозрачности и управляемости. В отличие от невидимых скриптов, здесь у вас есть визуальный граф, где каждая стрелка означает жесткую зависимость. Задача Б просто не начнется, пока задача А не вернет статус успеха. К тому же, инструмент берет на себя всю рутину с перезапусками. Если сеть мигнула и выгрузка данных оборвалась, система сама попробует повторить операцию через пять минут, не отвлекая вас от важных дел. Это дает ту самую уверенность в данных, которой так не хватает при использовании самописных костылей.
Философия направленных графов и магия идемпотентности
Прежде чем лезть в настройки, нужно усвоить два термина, на которых держится весь проект. Первый — это DAG (Directed Acyclic Graph) или Направленный Ациклический Граф. Слово направленный означает, что у ваших задач есть четкий вектор движения от начала к концу. Ациклический гарантирует, что в схеме нет петель: задача не может ссылаться сама на себя через цепочку других действий. Это дает уверенность, что процесс когда-нибудь завершится, а не превратится в бесконечный цикл, пожирающий ресурсы.

Второй критически важный термин — идемпотентность. Это свойство означает, что сколько бы раз вы ни запускали одну и ту же задачу с одними и теми же входными данными, результат всегда будет одинаковым. Например, скрипт, который просто добавляет строки в таблицу, не идемпотентен, ведь при повторе он создаст дубликаты. А вот скрипт, который сначала удаляет старые данные за конкретный день, а потом записывает новые — идеальный пример. Airflow буквально заставляет вас писать код именно так, потому что в мире больших данных сбои неизбежны, и возможность безопасно перезапустить упавший пайплайн (Retry) бесценна.
Анатомия Apache Airflow — Как это работает под капотом
Apache Airflow — это не монолитная программа, а распределенная система, где каждый компонент выполняет свою узкую роль. Чтобы понимать, почему задача висит в статусе Queued и не запускается, нужно понимать, как эти компоненты общаются.
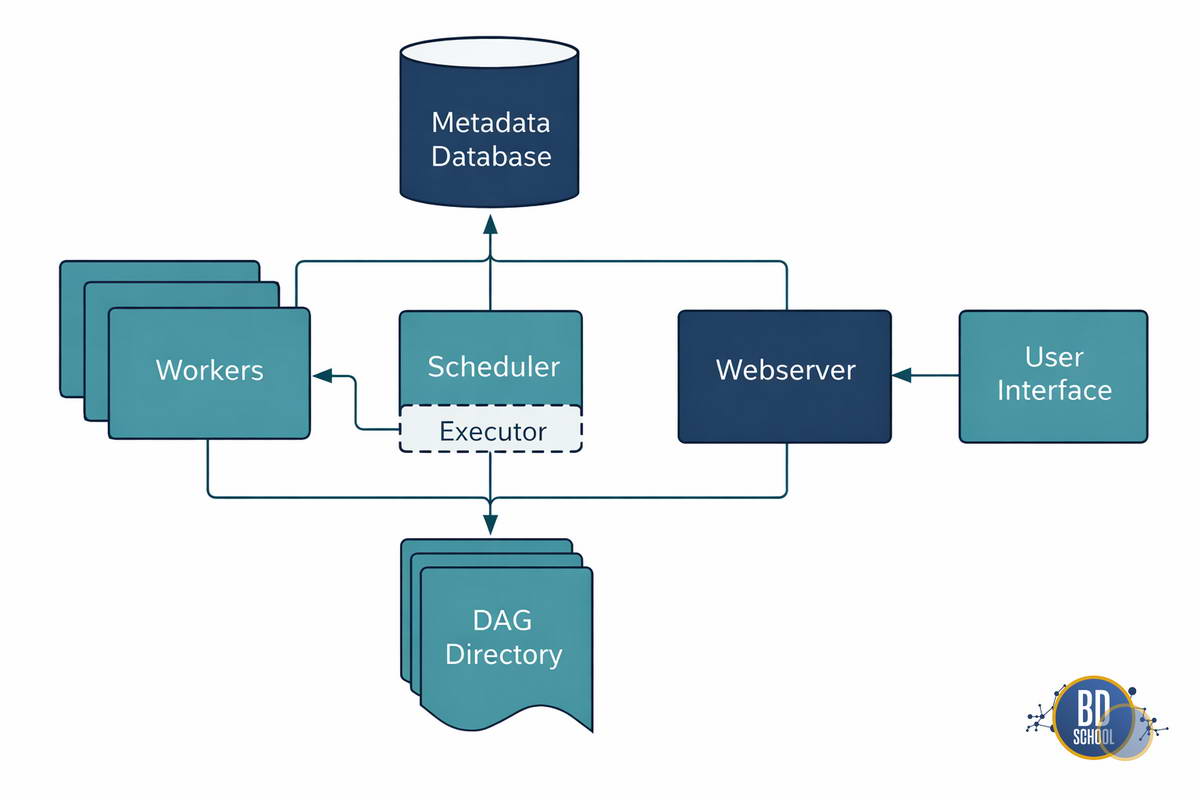
База метаданных (Metadata Database) Это «мозг» и память всей системы. Обычно это PostgreSQL или MySQL. Здесь хранится абсолютно всё: настройки подключений, логины пользователей, переменные (Variables) и, самое главное, состояние каждой задачи (Task Instance State). Важно: Компоненты Airflow (Планировщик, Веб-сервер, Воркеры) почти никогда не общаются друг с другом напрямую. Они общаются через чтение и запись в эту базу данных. Если база упадет — Airflow остановится.
Планировщик (Scheduler) Это сердце системы. Это процесс, который постоянно работает в фоне. У него две главные функции:
-
Парсинг: Он постоянно сканирует папку с вашими Python-файлами (dags/), чтобы найти новые или измененные DAG-и.
-
Планирование: Он проверяет в базе данных, наступило ли время запуска для какого-либо DAG-а. Критический нюанс: Сам Планировщик не выполняет ваши задачи (код ETL). Он лишь создает запись в базе данных: «Задачу А пора выполнять, ставлю ей статус Scheduled».
Исполнитель (Executor) Это механизм (модуль внутри Планировщика), который решает, где и как будут выполняться задачи.
-
SequentialExecutor: Простой, однопоточный. Подходит только для отладки.
-
LocalExecutor: Запускает задачи как подпроцессы на той же машине, где работает Планировщик.
-
CeleryExecutor / KubernetesExecutor: Позволяет запускать задачи на удаленных серверах (воркерах). Для нашего старта мы используем LocalExecutor — это золотая середина между простотой настройки и возможностью параллельного запуска.
Веб-сервер (Webserver) То, что вы видите в браузере. Это Flask-приложение, которое просто читает данные из Базы Метаданных и красиво их отрисовывает. Если веб-сервер упадет, ваши пайплайны продолжат работать, просто вы потеряете визуальный контроль.
Такое разделение позволяет системе быть гибкой. Вы можете обновить веб-интерфейс, не останавливая выполнение критически важных расчетов, или заменить базу данных, сохранив всю логику пайплайнов в Python-файлах.
Жизненный цикл задачи — от кода до исполнения
Понимание этого потока — ключ к успешной отладке (Troubleshooting). Что происходит, когда вы написали код?
-
Parsing: Планировщик читает ваш .py файл. Если там нет синтаксических ошибок, он создает структуру DAG в памяти.
-
Scheduling: Наступает время запуска (start_date + interval). Планировщик создает в БД объект DagRun (запуск графа) и объекты TaskInstance (экземпляры задач) со статусом None.
-
Queuing: Планировщик видит, что зависимости соблюдены, и меняет статус задачи на Scheduled, а затем отправляет её Исполнителю (Executor). Статус меняется на Queued.
-
Execution: Воркер подхватывает задачу, меняет статус на Running и начинает выполнять ваш Python-код.
-
Completion: Если код завершился без ошибок, воркер пишет в БД статус Success. Если было исключение — Failed.
В веб-интерфейсе Airflow этот жизненный цикл отображается цветами: задача меняет цвет с серого (Queued) на салатовый (Running), а затем становится темно-зеленой (Success) или ярко-красной (Failed). Именно за этой «светофором» вы и будете следить в своей повседневной работе, чтобы мгновенно оценивать здоровье пайплайнов.
![]()
Таким образом, запуск DAG — это не одномоментное действие, а эстафета, где Планировщик передает палочку Базе данных, а та — Исполнителю. Понимание этой цепочки спасет вам немало нервов при отладке. А теперь, когда мы разобрались с теорией, давайте поднимем эту архитектуру своими руками.
Практика: поднимаем песочницу Apache Airflow в Docker за пять минут
Чтобы не тратить часы на установку библиотек и настройку окружения, мы воспользуемся Docker. Это позволит создать изолированную среду, которая не замусорит вашу основную систему. Для старта нам понадобится всего один файл docker-compose.yaml, который опишет все необходимые связи между компонентами.
Во избежания ошибок при работе с docker и docker compose требуется проверить и обновить конфигурацию docker compose в вашей OS.
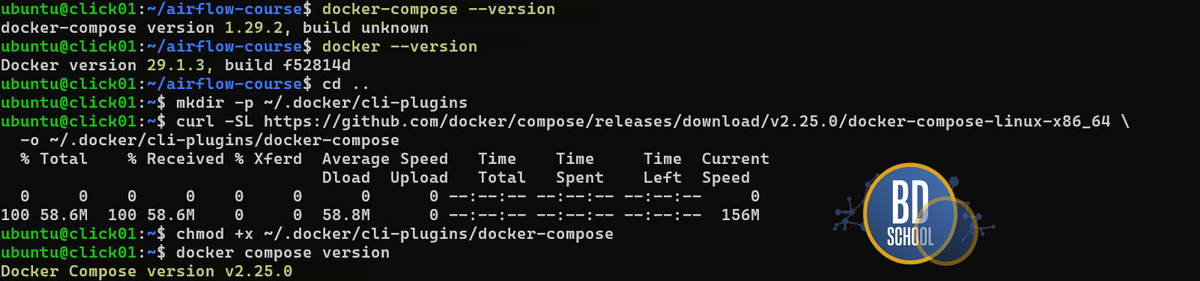
Bash скрипт для обновления
docker-compose --version # должно быть выше v1 docker --version # должно быть выше 20.10 mkdir -p ~/.docker/cli-plugins curl -SL https://github.com/docker/compose/releases/download/v2.25.0/docker-compose-linux-x86_64 -o ~/.docker/cli-plugins/docker-compose chmod +x ~/.docker/cli-plugins/docker-compose docker compose version # проверяем снова # удаляем старую версию which docker-compose sudo rm /usr/bin/docker-compose
Ниже приведен пример конфигурации (полный оригинальный вариант docker-compose.yaml доступен здесь), которая разворачивает связку из базы данных Postgres и самого Airflow в режиме LocalExecutor. Создайте пустую папку, положите туда этот текст и создайте рядом подпапку dags. Обратите внимание на переменную AIRFLOW_UID: она нужна, чтобы файлы, созданные внутри контейнера, принадлежали вашему пользователю, а не руту (root).
Примечание: Если у вас не слишком мощный компьютер (ноутбук) и вы не можете выделить 6-8 гигабайт оперативной памяти под Docker — рассмотрите вариант использования бесплатного (evaluation) аккаунта на одной из Cloud платформ. Обычно каждая из них предлагает Free tier (AWS) или какое то количество денег (Yandex Cloud) . В этом случае просто создайте вирутальную машину с одной из стандартных операционных систем ( Ubuntu 24) и установите Docker.
# Создаем папку проекта mkdir airflow-course && cd airflow-course mkdir -p dags logs plugins # Скачиваем официальный docker-compose файл curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.7.1/docker-compose.yaml' #-- для получения AIRFLOW UID создаем файл .env для текущего пользователя, и теперь мы можем получить доступ к папке с DAGs echo "AIRFLOW_UID=$(id -u)" > .env # Инициализация и запуск docker compose up airflow-init docker compose up -d
Инициализируем базу данных postgres
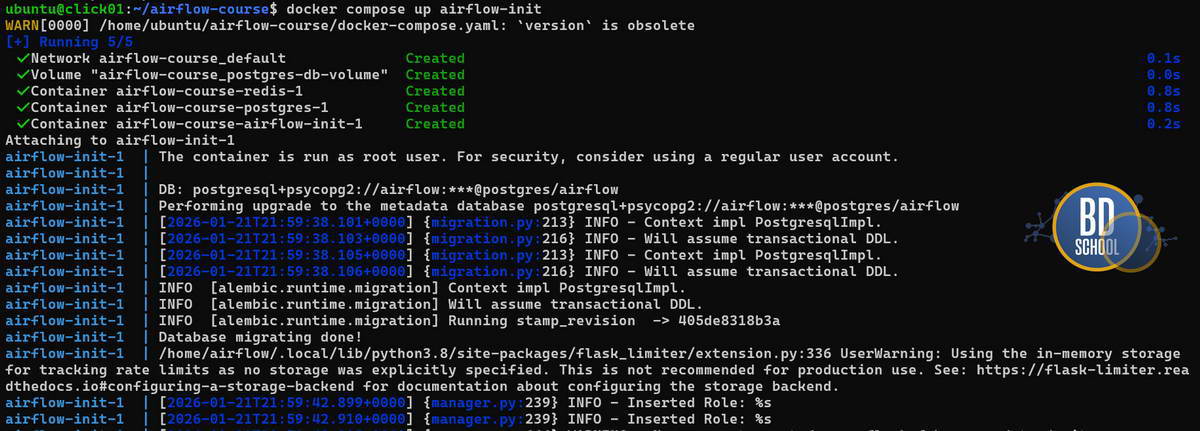
После того как файл готов, выполните команду docker compose up -d. Через пару минут интерфейс будет доступен по адресу localhost:8080 с логином и паролем admin. Теперь у вас есть полноценная лаборатория для опытов, где можно безбоязненно ломать и чинить любые процессы, просто перезапуская контейнеры.

Для проверки запуска сервисов используйте
# ---- список запущенныз docker container docker ps #---- проверка логов сервера airflow ( на выбор) docker compose logs airflow-scheduler
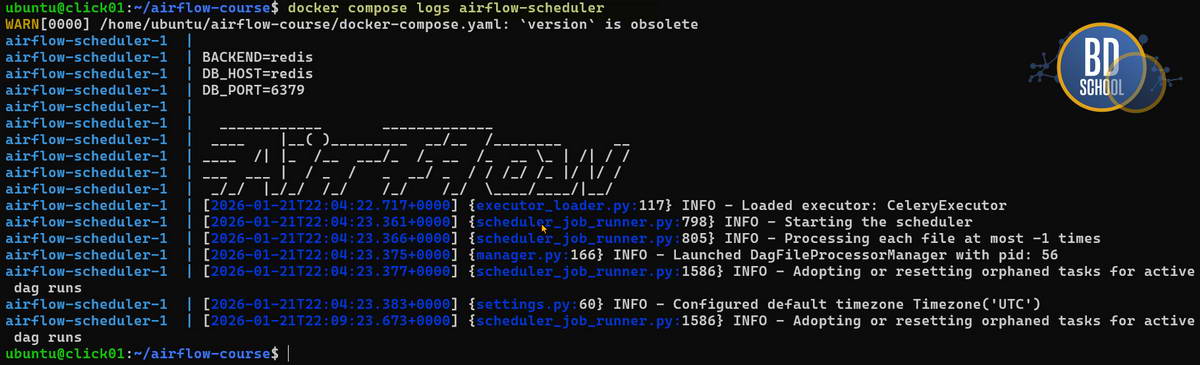
BashOperator против PythonOperator
В Airflow вся работа выполняется Операторами. Это кирпичики, из которых строится DAG. Когда база настроена, пора переходить к написанию кода. Самый простой выбор для новичка — это BashOperator и PythonOperator. Давайте сравним их на примере простой задачи: нужно создать папку с текущей датой, чтобы понять, какой инструмент лучше подходит для ваших сценариев.
BashOperator — это способ выполнить любую команду в терминале. Если вы привыкли писать скрипты на bash или использовать готовые утилиты вроде curl или rsync, этот оператор станет вашим лучшим другом. Он очень быстрый и потребляет минимум ресурсов, потому что просто пробрасывает команду в операционную систему. Однако его трудно отлаживать, если логика становится сложнее одного предложения, так как передавать данные между задачами через bash — то еще удовольствие.
PythonOperator, напротив, дает вам всю мощь языка программирования. Вы можете импортировать любые библиотеки, работать с API или делать сложные вычисления прямо в коде задачи. Это гибко, но требует больше ресурсов сервера, так как каждый запуск задачи порождает новый тяжеловесный процесс Python. В таблице ниже мы собрали ключевые различия, чтобы вам было проще ориентироваться.
| Характеристика | BashOperator | PythonOperator |
|---|---|---|
| Когда использовать | Системные команды, перемещение файлов, запуск бинарников | Сложная логика, работа с API, обработка данных в Pandas |
| Скорость запуска | Почти мгновенно | Зависит от объема импортируемых библиотек |
| Читаемость | Хорошая для коротких однострочников | Отличная для разработчиков Python |
| Передача данных | Через временные файлы или переменные окружения | Нативная через механизм XCom (Cross-Communication) |
Выбор часто зависит от того, где живет логика. Если у вас уже есть готовый скрипт на 500 строк, проще запустить его через BashOperator. Если же вы строите новый процесс с нуля, PythonOperator обеспечит лучшую интеграцию с экосистемой Apache Airflow.
Чтение логов: как понять что пошло не так
Когда задача запускается, Airflow начинает подробно записывать каждое свое действие. Умение читать эти логи — половина успеха инженера данных. В интерфейсе вы всегда можете кликнуть на квадратик задачи и нажать кнопку Log. Там вы увидите не только вывод вашего кода, но и служебную информацию от самой системы, которая часто оказывается важнее самого кода.
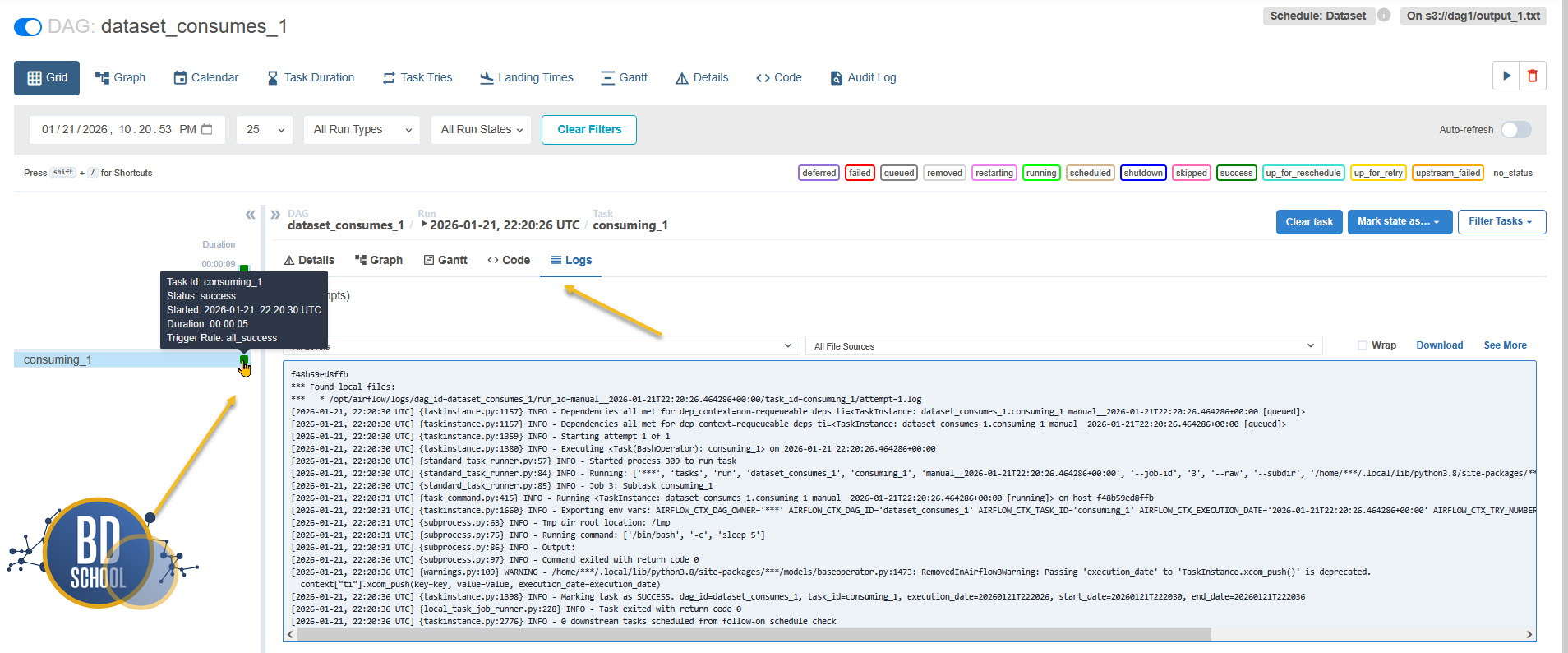
В успешном логе вы увидите пометку о начале работы процесса (PID), информацию о том, какой Executor взял задачу, и заветную строчку Marking task as SUCCESS. Если же задача упала, ищите ключевые слова Traceback или ERROR. Airflow честно покажет вам строку кода, на которой произошел сбой. Часто бывает, что проблема не в логике, а в окружении: например, вы забыли установить нужную Python-библиотеку внутри Docker-контейнера, и система просто не может сделать import. Помните, что логи планировщика и логи конкретной задачи — это разные вещи. Если задача даже не началась, ответ нужно искать в логах контейнера scheduler.
Частые затыки и как из них выбираться
Даже с готовой инструкцией легко совершить ошибки, которые ставят в тупик. Самая частая из них связана с параметром start_date. Новички часто ставят текущее время и удивляются, почему ничего не происходит. Логика Airflow такова, что он запускает задачу только после завершения первого интервала времени. Если вы хотите, чтобы DAG запустился прямо сейчас, ставьте дату начала на один день в прошлом. Это классика, через которую проходят абсолютно все.
Еще один камень преткновения — это отсутствие динамики в интерфейсе. Если вы изменили код в файле, а в браузере ничего не поменялось, проверьте вкладку Import Errors в самом верху страницы. Скорее всего, где-то пропущена запятая или нарушены отступы. Планировщик просто не может прочитать битый файл и продолжает показывать вам старую версию из своей памяти, чтобы не ломать работающую систему. Если там пусто, зайдите внутрь контейнера планировщика (docker exec -it <container_id> bash) и выполните airflow dags list-import-errors. Или просто посмотрите логи планировщика в терминале.
Наконец, не забывайте про ресурсы вашего компьютера. Если вы запускаете тяжелую обработку данных внутри PythonOperator на слабом ноутбуке, Docker-контейнер может просто молча перезагрузиться или зависнуть. Всегда следите за тем, сколько оперативной памяти выделено вашему Docker Desktop (минимум 4 ГБ для комфортной работы), иначе даже самый правильный код будет вылетать без внятных объяснений.Проверьте, запущен ли сервис scheduler. В нашем Docker-compose это отдельный контейнер. Если он упал (например, из-за нехватки памяти OOM), задачи никогда не перейдут в статус Running.
Помощь Cursor в документировании и отладке
Современные редакторы кода с искусственным интеллектом, такие как Cursor, значительно ускоряют освоение оркестратора. Вместо того чтобы часами искать примеры в документации, вы можете общаться с кодом напрямую. Это особенно полезно на этапе написания первых операторов, когда вы еще не помните все аргументы наизусть.
Примечание: использование VibeCoding для написания кода может вам помочь, только если вы потом подробно и детально разбираете код, который вы «накодили 🙂» иначе получается ситуация как в пословице «Дурак думкой богатеет» — учитесь не Вы, а тот самый искусственный интеллект AI (ChatGPT, Claude AI, Gemini или Cursor)
Например, вы можете выделить кусок кода и попросить: «Добавь подробные комментарии к аргументам DAG, объяснив, что делает catchup=False». Это поможет не просто скопировать код, а понять его смысл. Также полезно копировать текст ошибки из логов Airflow прямо в чат Cursor с вопросом: «В чем причина этого сбоя и как поправить мой Python-коллбэк?». ИИ отлично находит опечатки в путях или неправильное использование контекста задачи, что экономит массу времени на старте.
Мы разобрались с основами, поняли архитектуру и подняли локальную среду для экспериментов. Это важный первый шаг, который превращает магию оркестрации в понятный рабочий инструмент. Однако в реальном бизнесе Airflow редко работает на одном сервере. В следующей статье мы научим его масштабироваться, развернем полноценную распределенную очередь задач и узнаем, зачем нам нужны Redis и Celery для обеспечения настоящей отказоустойчивости в продакшене.
Референсные источники
-
Apache Airflow Concepts (Architecture):
https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/overview.htmlОфициальное описание архитектуры: Scheduler, Webserver, Worker и как они связаны. -
Install Airflow with Docker Compose:
https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.htmlТот самый официальный docker-compose.yaml, который мы упрощали в статье. -
Airflow vs Cron (Astronomer Blog):
https://www.astronomer.io/blog/airflow-vs-cron/Хороший разбор, почему Cron умирает в Data Engineering. -
Directed Acyclic Graphs (DAGs) Concept:
https://en.wikipedia.org/wiki/Directed_acyclic_graphДля тех, кто хочет понять математическую суть графов.