 423
423 
Содержание
- Главная проблема - Airflow не умеет заходить в Spark "из коробки"
- Шаг 1. Модернизируем Docker-образ для поддержки Java и Apache Spark
- Шаг 2. Добавляем Spark-кластер
- Шаг 3. Настраиваем Connection
- Практика: PySpark Job для обработки данных
- Шаг 4. AirFlow DAG со SparkSubmitOperator
- Troubleshooting: Почему Spark падает?
- Помощь Cursor: Пишем PySpark код для DAG Airflow
- Использованные референсы и материалы
- Полный перечень статей Бесплатного курса "Apache Airflow для начинающих"
Мы построили пайплайн, где данные забираются из базы и бережно складываются в HDFS. Теперь они лежат там мертвым грузом. Чтобы превратить сырые CSV в полезные отчеты, их нужно обработать: отфильтровать, агрегировать, джойнить. Делать это внутри самого Airflow (через PythonOperator и Pandas) — плохая идея если:
- Память: Если файл весит 100 ГБ, ваш воркер Airflow просто лопнет (OOM Kill).
- Скорость: Pandas работает на одном ядре. Spark распределяет задачу на сотни ядер.
Airflow здесь выступает только как кнопка «Пуск». Он запускает задачу на кластере Spark и смиренно ждет, пока «большой брат» закончит работу. Для этого используется SparkSubmitOperator.
Главная проблема — Airflow не умеет заходить в Spark «из коробки»
Здесь новички ломают копья. SparkSubmitOperator — это, по сути, обертка над консольной командой spark-submit. Чтобы этот оператор сработал, на машине (или в контейнере), где крутится воркер Airflow, должны быть физически установлены:
- Java (OpenJDK) — потому что Spark работает на JVM.
- Клиент Spark — набор бинарных файлов, чтобы отправить команду кластеру.
Стандартный образ apache/airflow, который мы использовали до этого, не содержит Java. Если вы попробуете запустить Spark-задачу сейчас, вы получите ошибку JAVA_HOME not set или spark-submit not found. Помните как мы с вами костылизировали с Apache Hadoop и AirFlow на прошлом уроке?
Анализ данных с помощью современного Apache Spark
Код курса
SPARK
Ближайшая дата курса
6 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Шаг 1. Модернизируем Docker-образ для поддержки Java и Apache Spark
Нам придется снова немного «запачкать руки» и пересоздать свой образ Airflow, который мы с вами использовали на прошлом уроке ( поддержка Hadoop provider) и добавить туда Spark с поддержкой Java. Не пугайтесь, это стандартная практика.
Создайте(или отредактируйте существующий) файл Dockerfile в корне проекта (рядом с docker-compose):
FROM apache/airflow:2.8.1
USER root
# 1. ОБЪЕДИНЕННАЯ УСТАНОВКА СИСТЕМНЫХ ПАКЕТОВ
# gcc, libkrb5-dev... — нужны для компиляции HDFS провайдера (Урок 5)
# default-jdk, procps, curl — нужны для работы Spark (Урок 6)
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
gcc \
libkrb5-dev \
krb5-user \
libffi-dev \
default-jdk \
procps \
curl \
&& apt-get autoremove -yqq --purge \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# 2. НАСТРОЙКА JAVA (Урок 6)
ENV JAVA_HOME=/usr/lib/jvm/default-java
export JAVA_HOME
# 3. УСТАНОВКА SPARK-КЛИЕНТА (Урок 6)
ENV SPARK_VERSION=3.5.1
ENV HADOOP_VERSION=3
RUN curl -O https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz \
&& tar zxf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz -C /opt/ \
&& rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz \
&& ln -s /opt/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} /opt/spark
# 4. НАСТРОЙКА ПУТЕЙ SPARK
ENV SPARK_HOME=/opt/spark
ENV PATH=$PATH:$SPARK_HOME/bin
USER airflow
# 5. УСТАНОВКА ПРОВАЙДЕРОВ
# Ставим сразу оба: и для HDFS (чтобы работал DAG из 5 урока), и для Spark
RUN pip install --no-cache-dir \
apache-airflow-providers-apache-hdfs \
apache-airflow-providers-apache-spark
Пересоздаем наш образ «франкенштейн» состоящий теперь из бинарников Hadoop, Spark и провайдеров для них в Airflow вместе с Java — такова цена интеграции.
#--- и пересобираем его с нуля для уверенности - процесс может занять 5-10 минут docker build --no-cache -t airflow-hdfs:2.8.1 . #--- почистим старые images docker image ls #для проверки docker image prune docker image ls #для проверки #--- Уже запущенные контейнеры не обновят автоматически используемый image без опции --build docker compose up -d --build
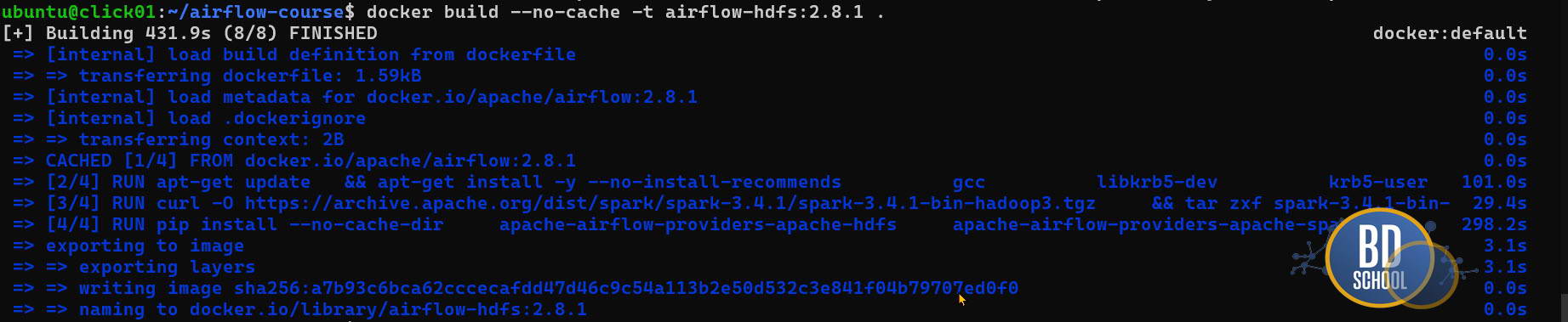
Теперь нужно сказать docker-compose, чтобы он использовал вновь созданный файл image ‘airflow-hdfs:2.8.1‘, а не готовый образ из интернета. Измените секцию x-airflow-common в docker-compose.yaml добавив новые переменные и volumes для Spark Jobs:
x-airflow-common:
&airflow-common
image: airflow-hdfs:2.8.1 # Изменяем используемый имидж
# build: .
environment:
# ... старые переменные ...
JAVA_HOME: /usr/lib/jvm/default-java # Добавляем новые переменные для Spark
SPARK_HOME: /opt/spark
volumes:
# --- НОВЫЙ ТОМ ДЛЯ УРОКА 6 (Скрипты Spark) ---
- ${AIRFLOW_PROJ_DIR:-.}/jobs:/opt/airflow/jobs
Шаг 2. Добавляем Spark-кластер
Нам нужен сам Spark, который будет выполнять работу. Добавим мастер и один воркер в docker-compose.yaml (в секцию services):
# Урок 6 Spark jobs - кластер для Airflow tasks
spark-master:
image: apache/spark:3.5.1
container_name: spark-master
hostname: spark-master
profiles:
- spark
environment:
- SPARK_NO_DAEMONIZE=true
- SPARK_MASTER_HOST=spark-master
ports:
- "9090:8080" # Web UI (сместили на 9090, чтобы не конфликтовал с Airflow)
- "7077:7077" # Мастер-порт
command: /opt/spark/bin/spark-class org.apache.spark.deploy.master.Master
spark-worker:
image: apache/spark:3.5.1
container_name: spark-worker
profiles:
- spark
environment:
- SPARK_NO_DAEMONIZE=true
- SPARK_WORKER_CORES=1
- SPARK_WORKER_MEMORY=1G
depends_on:
- spark-master
command: /opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:7077
Не забудьте включить hadoop & datanode из прошлого примера или применить —profile spark. Теперь выполняем команду пересборки и запуска: docker-compose up -d —build

Зайдите на localhost:9090. Вы должны увидеть интерфейс Spark Master с одним живым воркером (Alive Workers: 1).
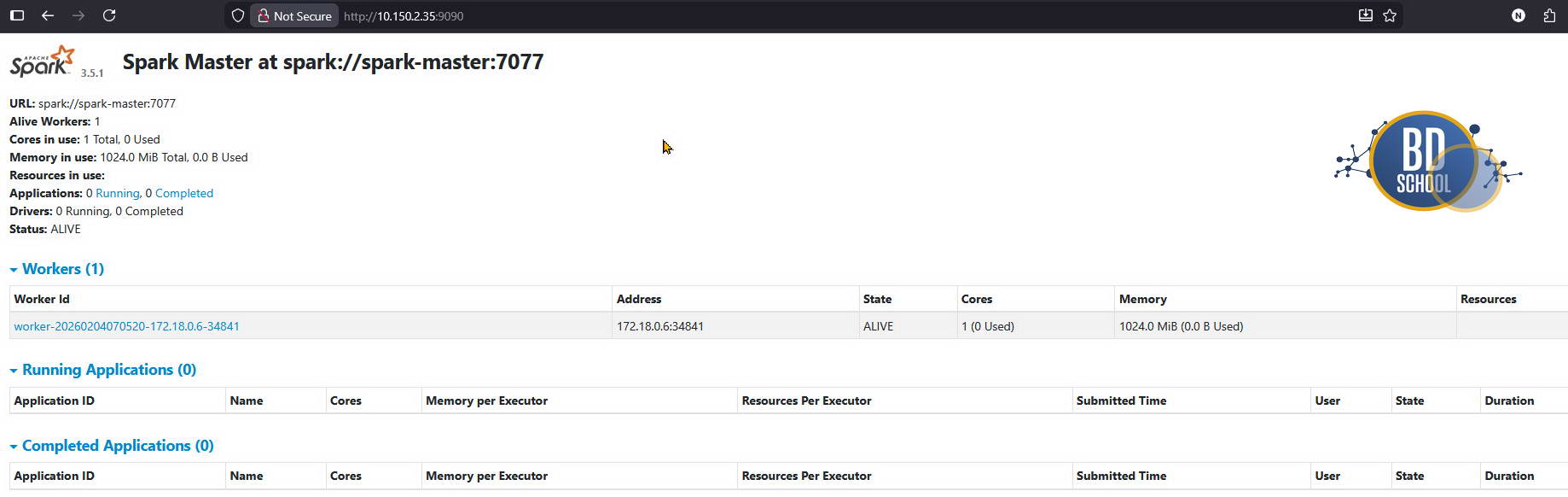
Шаг 3. Настраиваем Connection
Airflow должен знать, где живет Spark Master.
- Admin -> Connections.
- Новое соединение:
| Conn Id | my_spark_conn | |
| Conn Type | Spark | |
| Host | spark://spark-master | |
| Port | 7077 | |
| Extra ( или Deploy mode) | {«deploy-mode»: «client»} | или cluster, но для Docker проще client, чтобы видеть логи сразу |
Практика: PySpark Job для обработки данных
В прошлой статье мы положили файл users_{ds}.csv в HDFS. Давайте напишем скрипт на PySpark, который читает этот файл, считает распределение пользователей по датам и сохраняет отчет обратно в HDFS (или выводит в консоль).
Создайте папку jobs рядом с dags и положите туда скрипт user_analytics.py:
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, count
def main(input_path, output_path):
# Создаем сессию
spark = SparkSession.builder \
.appName("AirflowUserAnalytics") \
.getOrCreate()
print(f"Reading from: {input_path}")
# Читаем CSV. Так как хедер мы писали сами, указываем header=True
df = spark.read.option("header", "true").csv(input_path)
# Простая аналитика: сколько регистраций в каждую дату
report = df.groupBy("date").agg(count("*").alias("total_users"))
report.show()
# Сохраняем результат (в формате Parquet, это стандарт для Big Data)
# report.write.mode("overwrite").parquet(output_path)
spark.stop()
if __name__ == "__main__":
# Аргументы передаются из Airflow
if len(sys.argv) != 3:
print("Usage: user_analytics.py <input_path> <output_path>")
sys.exit(-1)
main(sys.argv[1], sys.argv[2])
Шаг 4. AirFlow DAG со SparkSubmitOperator
Теперь самое главное — связать всё вместе. Код DAG-а (dags/process_spark.py):
from airflow import DAG
from airflow.providers.apache.spark.operators.spark_submit import SparkSubmitOperator
from datetime import datetime
# Путь к HDFS, куда мы писали в прошлой статье
# Обратите внимание: spark внутри Docker-сети может обращаться к namenode
HDFS_INPUT = "hdfs://namenode:8020/user/airflow/backup/users_{{ ds }}.csv"
HDFS_OUTPUT = "hdfs://namenode:8020/user/airflow/reports/daily_{{ ds }}"
with DAG(
dag_id="06.spark_processing",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False
) as dag:
process_task = SparkSubmitOperator(
task_id="run_spark_job",
conn_id="my_spark_conn",
# Путь к скрипту внутри контейнера AIRFLOW
application="/opt/airflow/jobs/user_analytics.py",
# Аргументы для скрипта (input и output)
application_args=[HDFS_INPUT, HDFS_OUTPUT],
# Конфигурация ресурсов (сколько отдать Спарку)
conf={
"spark.driver.memory": "512m",
"spark.executor.memory": "512m"
},
# Важно! Указываем пакеты, если нужно работать с S3 или другими системами
# packages="org.apache.hadoop:hadoop-aws:3.2.0",
verbose=True
)
Как это работает — объяснялки
- Airflow (Worker) берет параметры из оператора
- Он формирует длинную команду: /opt/spark/bin/spark-submit —master spark://spark-master:7077 … user_analytics.py ….
- Эта команда запускается в контейнере Airflow
- Клиент Spark связывается с мастером, передает ему код
- Мастер распределяет задачу на spark-worker
- Воркер читает данные из HDFS, считает и пишет результат
- Airflow видит, что процесс spark—submit завершился с кодом 0, и красит задачу в зеленый цвет
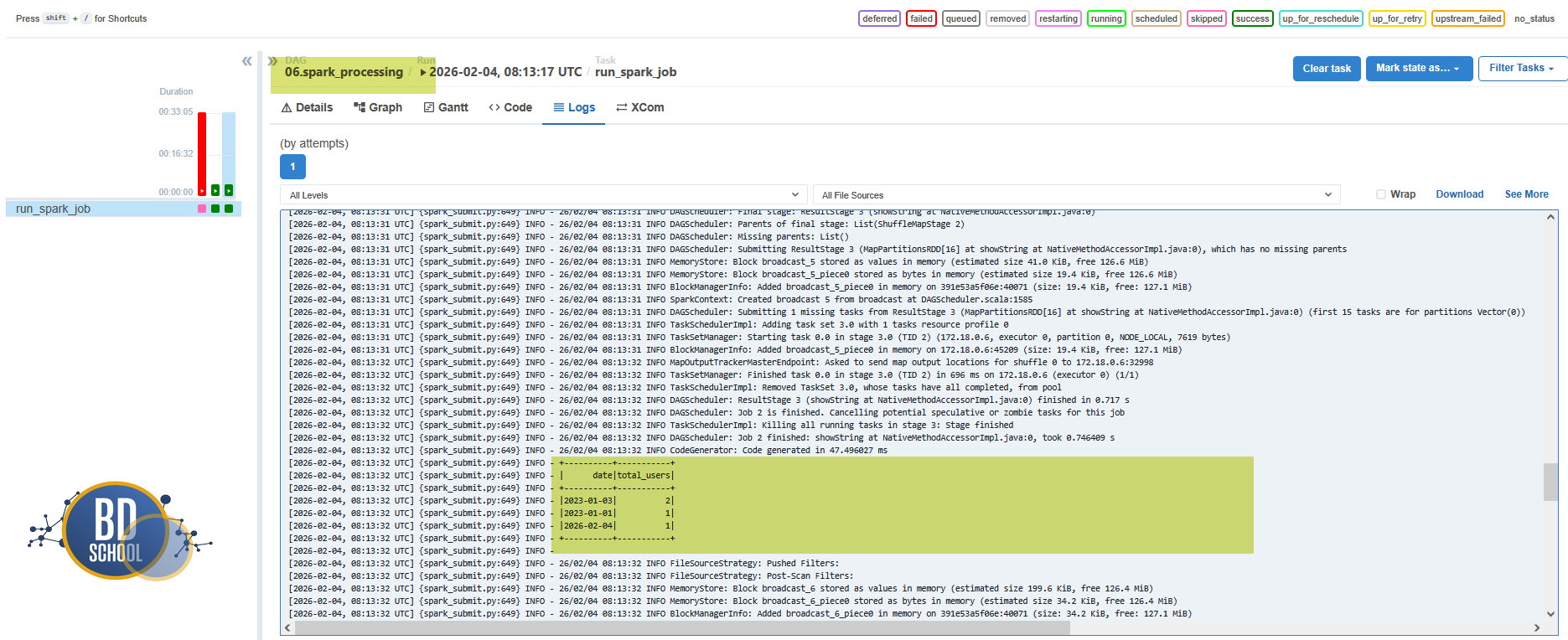
Давайте попробуем?
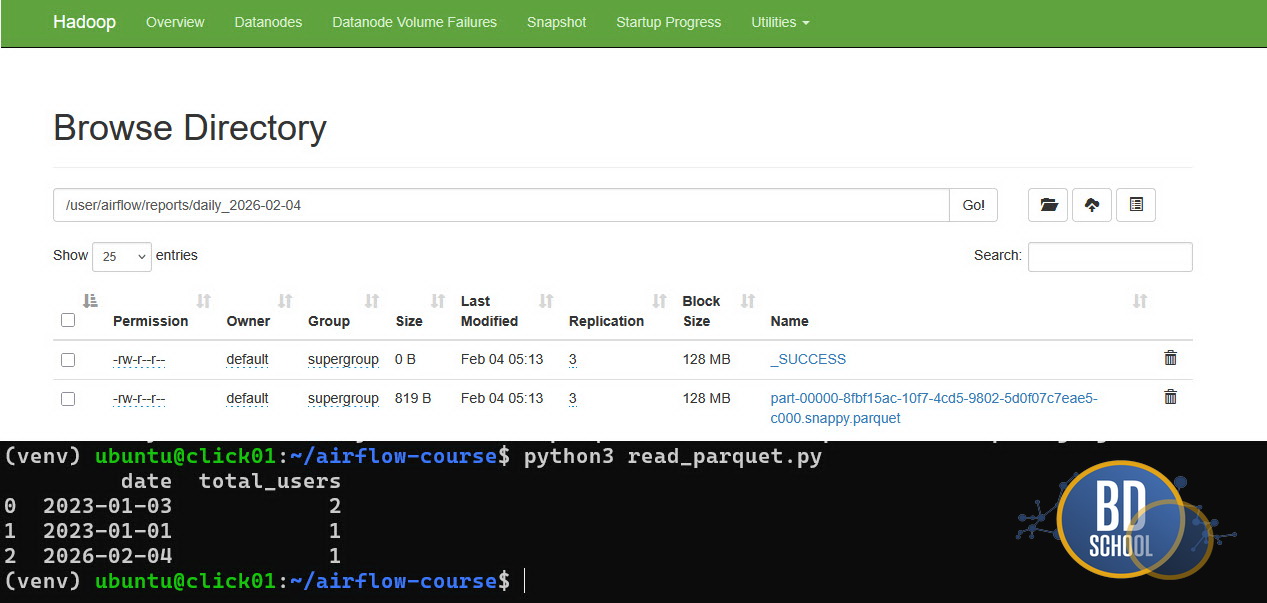
Конечно проверить финальный результат из карманного Hadoop и в паркетном формате тот еще дополнительный квест, но он того стоил ( через docker exec -it скопировать данные с hdfs на локальную систему namenode, потом через docker cp скопировать все с namenode локально и уже финально установив pandas и fastparquet прочитать все с использованием простого питон скрипта).
По традиции все финальные версии файлов вы сможете найти у нас на GitHub
Troubleshooting: Почему Spark падает?
Запуск Spark в контейнерах — это минное поле.
Ошибка 1: JAVA_HOME is not set
- Причина: Вы не пересобрали Docker-образ или забыли ENV JAVA_HOME в Dockerfile.
- Лечение: Проверьте docker exec -it <airflow_container> java -version. Если команды нет — пересобирайте образ.
Ошибка 2: Connection refused к HDFS внутри Spark-джобы
- Причина: Spark Worker (отдельный контейнер) не может достучаться до Namenode.
- Лечение: Убедитесь, что все контейнеры (spark-worker, namenode) находятся в одной сети default (docker-compose делает это автоматически, но если вы запускали их разными файлами — будут проблемы).
Ошибка 3: Driver runs, but Executor fails
- Причина: Часто это нехватка памяти. Spark по умолчанию может просить 1ГБ на экзекьютор, а выделили вы Докеру всего 2ГБ на всё.
- Лечение: Явно занижайте память в параметре conf: «spark.executor.memory«: «512m».
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Помощь Cursor: Пишем PySpark код для DAG Airflow
Если вы не помните синтаксис DataFrame API, Cursor сделает это за вас.
"Напиши скрипт на PySpark, который читает Parquet-файлы из папки /data/input, фильтрует пользователей старше 18 лет, группирует их по городам и сортирует по убыванию количества. Результат сохрани в CSV."
Промпт для дебага:
"Вот лог ошибки SparkSubmitOperator: [текст ошибки]. Объясни, почему Airflow не может найти класс org.apache.hadoop.fs.s3a.S3AFileSystem и какой пакет нужно добавить в spark-submit."
Итог: Мы преодолели самый сложный барьер интеграции — настроили запуск Java-приложений из Python-оркестратора. Теперь Airflow управляет мощнейшим кластером обработки данных Apache Spark.
Но Spark — это тяжело, долго и требует много памяти. Всегда ли нам нужен такой монстр если тем более у Вас его еще нет и не кому его приручить? В следующей статье мы рассмотрим легкую, питоническую альтернативу — Dask. Мы узнаем, как масштабировать Pandas-код на несколько серверов без установки Java и мучений с spark-submit.
Переходим к Dask?
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Использованные референсы и материалы
- Apache Spark: Submitting Applications
https://spark.apache.org/docs/latest/submitting-applications.html
Что такое spark-submit, и какие флаги памяти/ядер там есть. - Airflow Spark Provider: SparkSubmitOperator
https://airflow.apache.org/docs/apache-airflow-providers-apache-spark/stable/operators/spark_submit.html
Как переложить параметры из консоли в Python-код оператора. - Bitnami Docker Image for Spark
https://hub.docker.com/r/bitnami/spark/
Описание образа, который мы используем в нашем docker-compose для кластера Spark.
Полный перечень статей Бесплатного курса «Apache Airflow для начинающих»
Урок 1. Apache Airflow с нуля: Архитектура, отличие от Cron и запуск в Docker
Урок 2. Масштабирование Airflow: Настройка CeleryExecutor и Redis в Docker Compose
Урок 3. Работа с базами данных в Airflow: Connections, Hooks и PostgresOperator
Урок 4. Airflow и S3: Интеграция с MinIO и Yandex Object Storage
Урок 5. Airflow и Hadoop: Настройка WebHDFS и работа с сенсорами (Sensors)
Урок 6. Запуск Apache Spark из Airflow: Гайд по SparkSubmitOperator
Урок 7. Airflow и Dask: Масштабирование тяжелых Python-задач и Pandas
Урок 8. Event-Driven Airflow: Запуск DAG по событиям из Apache Kafka
Урок 9. Загрузка данных в ClickHouse через Airflow: Быстрый ETL и батчинг
Урок 10. Airflow Best Practices: Динамические DAGи, TaskFlow API и Алертинг

