 382
382 
Содержание
- Почему LocalExecutor - это тупик для роста
- Новые игроки в команде: роль Redis и Celery
- Развертывание через Docker Compose - собираем конструктор
- Практика. Запускаем параллельные вычисления в Apache AirFlow
- Управление ресурсами в Apache Airflow
- Целевое распределение (Queues) - Высший пилотаж
- Тонкости настройки и типичные ошибки Docker-окружения
- Проблема 1: "Permission denied" и файлы логов
- Проблема 2: Воркер не видит код
- Проблема 3: Redis Connection Error
- Помощь Cursor в документировании инфраструктуры
- Использованные референсы и материалы
- Полный перечень статей Бесплатного курса "Apache Airflow для начинающих"
В предыдущей статье мы запустили Airflow в режиме «все в одном». Это когда и планировщик, и исполнитель задач живут внутри одного процесса. Для обучения это подходит идеально, но в реальной жизни такая схема умирает первой. Представьте, что вам нужно запустить десять тяжелых SQL-запросов к базе данных и параллельно обработать пять гигабайт логов на Python. Если использовать LocalExecutor (локальный исполнитель), ресурсы вашего сервера — процессор и оперативная память — закончатся мгновенно. Интерфейс начнет тормозить, а новые задачи просто встанут в бесконечную очередь, ожидая, пока освободится хоть один байт памяти.
Важное примечание: Обработка 5 ГБ данных внутри Airflow — это на самом деле плохая практика (анти-паттерн). Airflow — это оркестратор, а не движок обработки. Но мы приводим этот пример, потому что в реальности такие ошибки случаются, и ваша архитектура должна уметь их переживать, не роняя весь продакшен.
Чтобы система не упала под нагрузкой, нам нужно разделить обязанности. В этой статье мы перейдем на промышленный стандарт архитектуры Airflow — CeleryExecutor. Мы разнесем «мозги» (планирование) и «мускулы» (выполнение) по разным углам, а связующим звеном между ними станет Redis.
Почему LocalExecutor — это тупик для роста
Главная проблема локального запуска — это так называемое вертикальное масштабирование. Когда задач становится больше, единственный способ выжить — это добавить больше оперативной памяти и ядер в ваш единственный сервер. Но это дорого и имеет физический предел.
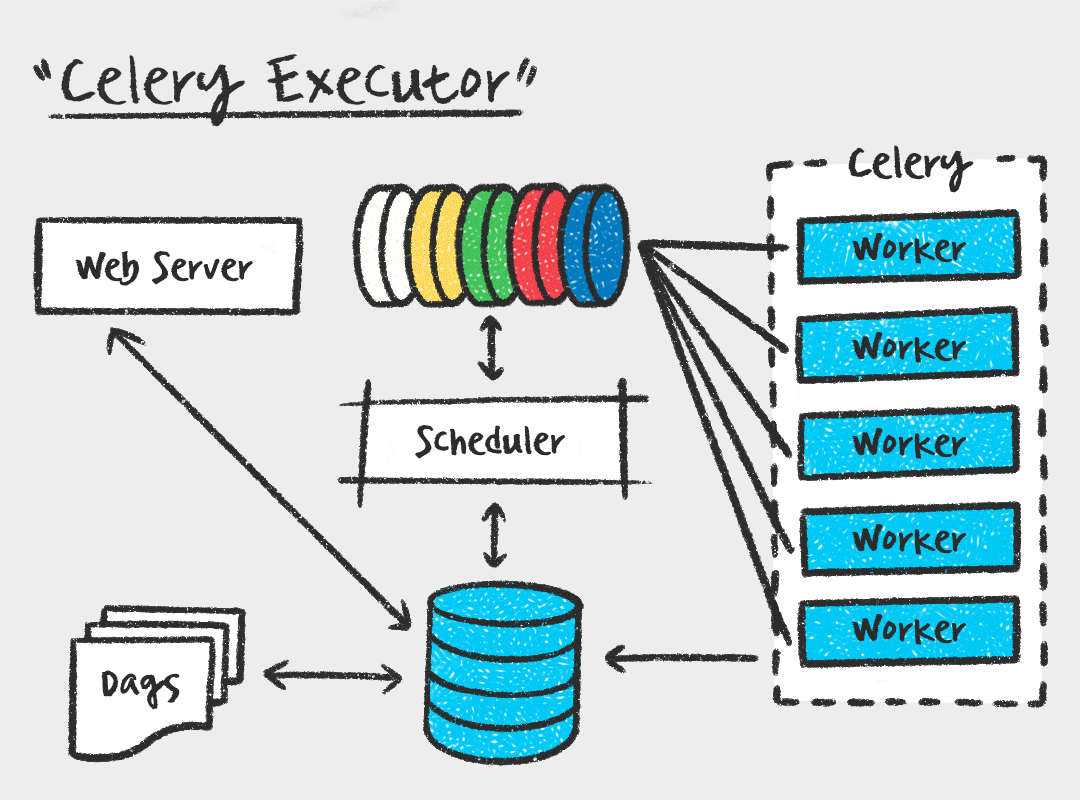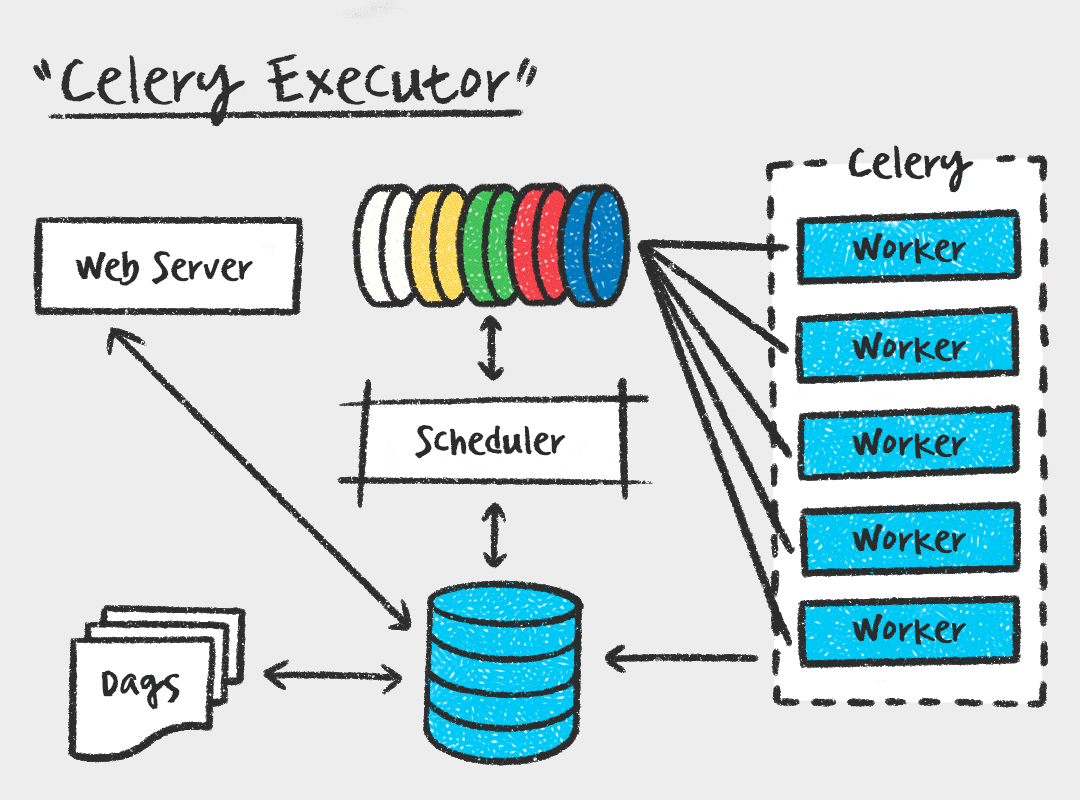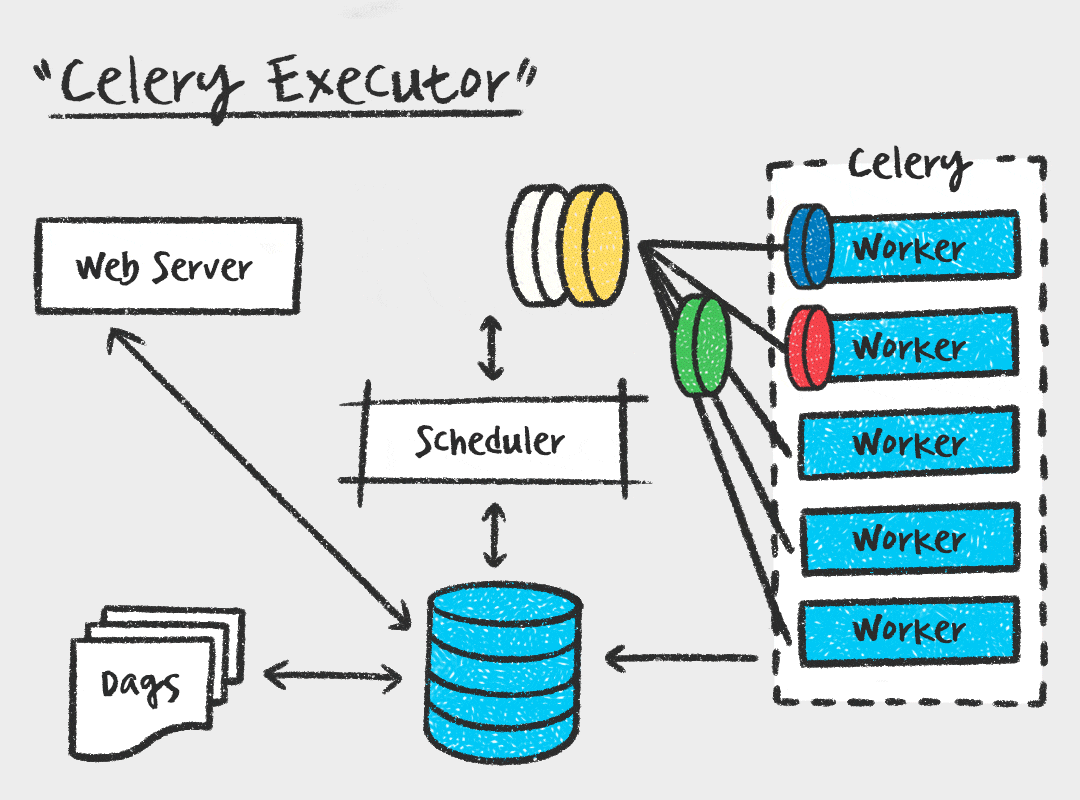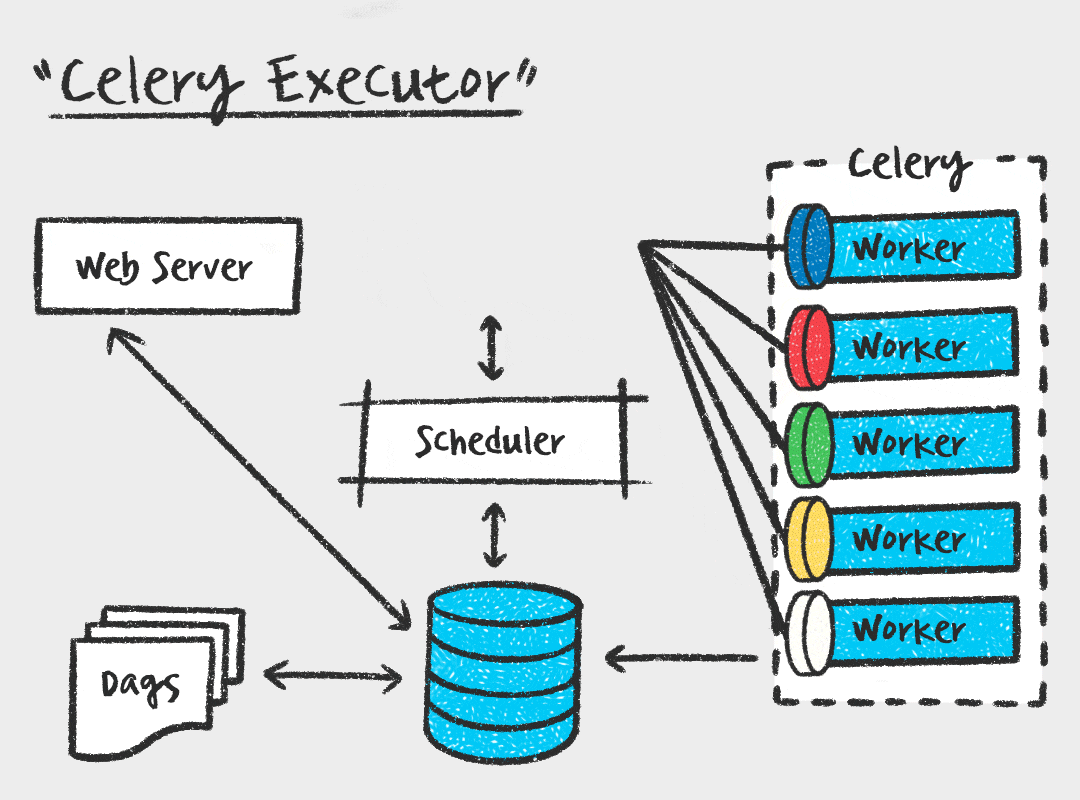
В продакшене используется горизонтальное масштабирование. Мы хотим иметь возможность просто добавить еще один, два или десять серверов-воркеров, если нагрузка выросла, и отключить их, когда нагрузка спала. LocalExecutor так не умеет. Он жестко привязан к той машине, где запущен планировщик (Scheduler). Если этот сервер упадет, встанет вообще все. Нам нужна архитектура, где падение одного исполнителя не влияет на общую картину, и где планировщик занимается только управлением, не тратя силы на тяжелые вычисления.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Новые игроки в команде: роль Redis и Celery
Чтобы разорвать жесткую связь между постановкой задачи и ее выполнением, нам нужен посредник. В экосистеме Python стандартом для таких задач является связка Celery (фреймворк для распределенных задач) и Redis (брокер сообщений).
Давайте представим работу современного таксопарка или агрегатора такси.
- Scheduler (Планировщик) — это центральная диспетчерская служба или алгоритм распределения заказов. Диспетчер знает расписание:
- в 8:00 нужно подать машину к офису (запустить ETL процесс),
- а в 9:00 — забрать отчет. Но сам диспетчер за руль не садится. Его задача — сформировать «заказ-наряд».
- Redis — это эфир или общая цифровая база заказов. Диспетчер отправляет туда заявку: «Заказ №123, маршрут от S3 до Postgres, оплата по тарифу High Memory». Эта заявка висит в базе и ждет.
- Celery Workers (Воркеры) — это таксисты на линии. Их может быть много. Свободный водитель смотрит в приложение (Redis), видит новый заказ, нажимает «Принять» и едет выполнять маршрут. Как только он освободился, он снова готов брать заказы.
- Flower — это панель администратора таксопарка. На ней видно, сколько машин сейчас на линии, кто стоит в пробке (зависшая задача), а кто сломался.
Почему именно Redis? Потому что это база данных, работающая целиком в оперативной памяти. Операции записи и чтения там происходят за микросекунды. Для Airflow, который может генерировать тысячи «заказов» в минуту, скорость передачи информации от диспетчера к водителю критически важна.
Развертывание через Docker Compose — собираем конструктор
Теперь самое интересное. Наш файл docker-compose.yaml станет сложнее. Нам нужно добавить сервис Redis, сервис для воркера и сервис мониторинга Flower.
Обратите внимание: все сервисы, которые работают с кодом (scheduler, webserver, worker), должны иметь доступ к одной и той же папке dags. Это критически важно. Если вы положите файл с DAG-ом в папку планировщика, но забудете пробросить ее воркеру, повар(worker) просто не поймет, по какому рецепту готовить, и выдаст ошибку.
Примечание: Не забудьте перед заменой( или редактированием) docker-compose.yaml погасить ваш кластер командой «docker compose down»
# Скачиваем официальный docker-compose файл curl -LfO 'https://airflow.apache.org/docs/apache-airflow/2.8.1/docker-compose.yaml' #-- для получения AIRFLOW UID создаем файл .env для текущего пользователя, и теперь мы можем получить доступ к папке с DAGs echo "AIRFLOW_UID=$(id -u)" > .env # Инициализация и запуск docker compose up airflow-init docker compose up -d
Детальный разбор настройки Redis
Давайте посмотрим на строку подключения, которую мы добавили: AIRFLOW__CELERY__BROKER_URL=redis://:@redis:6379/0
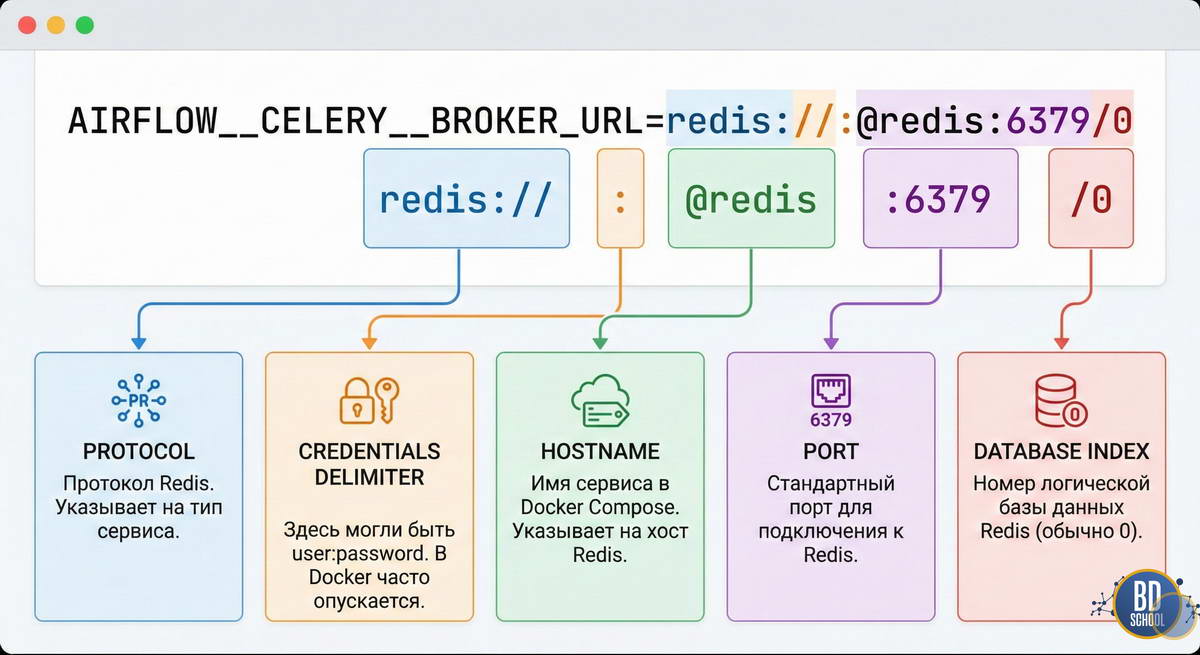
Без этой строки CeleryExecutor не запустится, так как он не будет знать, куда складывать сообщения.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Практика. Запускаем параллельные вычисления в Apache AirFlow
Теперь запустим нашу ферму командой docker compose up -d. Подождите пару минут, пока поднимутся все контейнеры. Теперь у вас доступны два интерфейса:
- Airflow: localhost:8080
- Flower: localhost:5555 ( Если flower не настроен на запуск автоматом его можно стартовать с помощью docker compose up flower)
Давайте напишем DAG, который наглядно покажет работу распределенной системы. Мы создадим задачу, которая имитирует долгую обработку данных (просто «спит» 30 секунд), и запустим 5 таких задач параллельно. В старой схеме с LocalExecutor (если бы у нас был 1 слот) они шли бы друг за другом 2.5 минуты. Здесь они должны выполниться одновременно за 30 секунд.
Создайте файл dags/parallel_test.py:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime
import time
import os
def heavy_computation(task_number):
print(f"Воркер начал задачу {task_number}")
# Имитируем бурную деятельность
time.sleep(30)
print(f"Воркер закончил задачу {task_number}")
return f"Done {task_number}"
with DAG(
dag_id="celery_parallel_demo",
start_date=datetime(2023, 1, 1),
schedule=None,
catchup=False
) as dag:
for i in range(1, 6):
PythonOperator(
task_id=f"processing_chunk_{i}",
python_callable=heavy_computation,
op_kwargs={"task_number": i}
)
Зайдите в Airflow, включите DAG и нажмите кнопку запуска (Trigger). Сразу после этого переключитесь в Flower (localhost:5555). Вы увидите магию: на вкладке Tasks появятся 5 задач со статусом STARTED. Это значит, что воркер подхватил их все одновременно. Redis отработал как диспетчер, мгновенно раздав поручения.
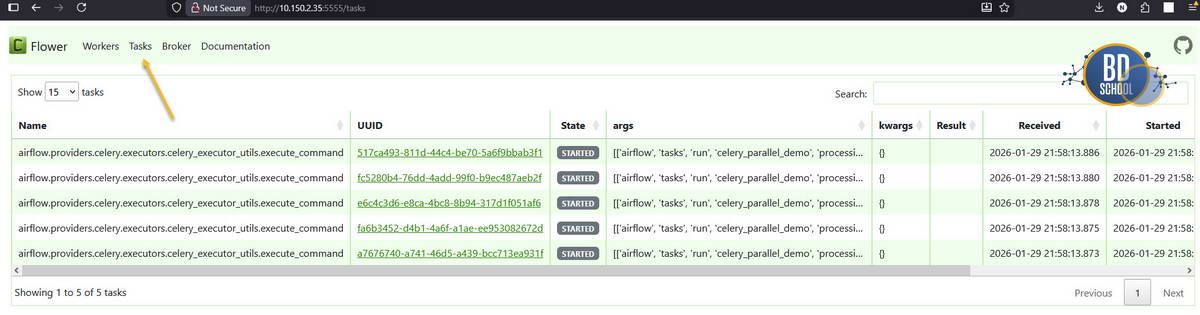
А теперь представьте, что задач стало 50. Один воркер захлебнется. В Docker Compose вы можете сделать финт ушами и добавить мощности одной командой:
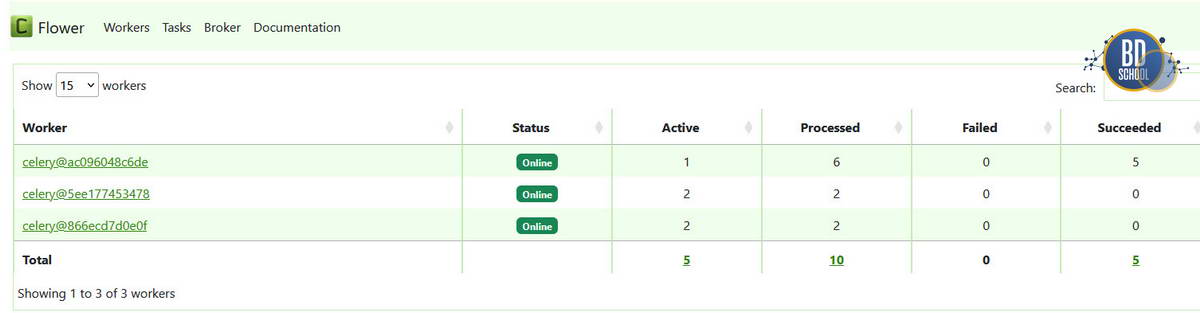
docker-compose up -d --scale worker=3

Эта команда запустит еще два контейнера с воркерами. Теперь у вас три «повара» на кухне, и они разберут очередь в три раза быстрее. LocalExecutor о таком мог только мечтать.
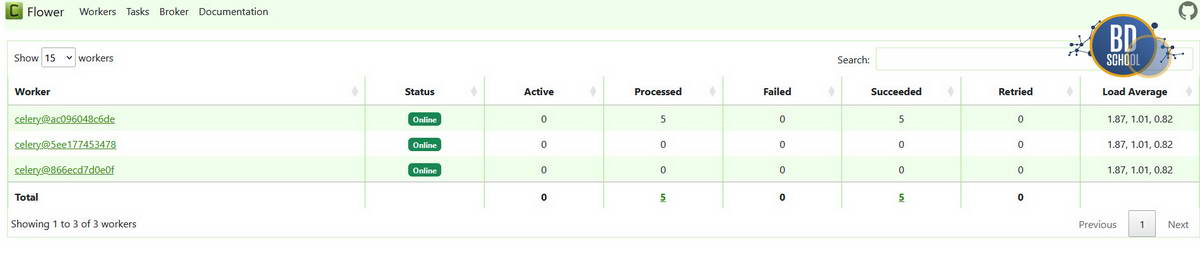
Конечно уже запущенные задачи вряд ли получат преимущества от новых Workers, но попробуйте снова запустить наш DAG и посмотрите как распределятся задачи между воркерами
Управление ресурсами в Apache Airflow
В Airflow с CeleryExecutor есть два способа распределения задач: Автоматический (по умолчанию) и Целевой (через Очереди/Queues).
Автоматическое распределение (Load Balancing)
Когда вы запустили docker-compose up -d —scale worker=3, вам ничего не нужно делать для перераспределения. Это работает само. Представьте, что Redis — это общая доска объявлений.
-
Планировщик вешает туда 50 задач.
-
Три ваших воркера — это три фрилансера, которые постоянно смотрят на доску.
-
Как только воркер освобождается, он «хватает» первую попавшуюся задачу с доски, помечает её как «взято» и начинает выполнять.
Celery сам балансирует нагрузку. Если один воркер застрял на тяжелой задаче, два других просто возьмут на себя больше мелких задач. Это называется Round Robin (или близко к тому, в зависимости от настроек prefetch).
Целевое распределение (Queues) — Высший пилотаж
А теперь представьте реальный кейс когда у вас есть задачи ML (Machine Learning), которым нужно 64 ГБ оперативной памяти и GPU и есть задачи SQL, которым памяти не нужно вообще, они просто ждут ответа от базы. Если вы пустите всё на самотек, тяжелая ML-задача может попасть на слабый воркер и убить его (OOM Kill). Или три тяжелых задачи попадут на один сервер и «задушат» друг друга, пока два других сервера простаивают. Здесь в игру вступают Очереди (Queues).
Шаг А: Размечаем задачи в коде DAG-а
Вы можете явно сказать задаче: «Ты должна идти только в очередь для тяжеловесов».
heavy_task = PythonOperator(
task_id='train_model',
python_callable=train_model,
queue='gpu_queue' # <--- ВОТ ЭТОТ МАГИЧЕСКИЙ ПАРАМЕТР
)
light_task = PythonOperator(
task_id='run_sql',
python_callable=run_sql,
queue='default' # По умолчанию все задачи летят в очередь 'default'
)
Шаг Б: Настраиваем Воркеров в Docker Compose
Теперь вам нужно специализировать своих «поваров». Вместо того чтобы просто копировать одинаковых воркеров (scale), мы создадим два разных сервиса в docker-compose.yaml.
# Воркер для обычных задач (дешевый сервер)
worker-light:
<<: *airflow-common
command: airflow celery worker -q default
# ...
# Воркер для ML задач (мощный сервер с GPU)
worker-heavy:
<<: *airflow-common
command: airflow celery worker -q gpu_queue
deploy:
resources:
limits:
memory: 32G
Что происходит теперь происходит при запуске DAG?
-
Воркер worker-heavy слушает только очередь gpu_queue. Он будет игнорировать обычные задачи.
-
Воркер worker-light слушает очередь default. Он никогда не возьмет задачу ML.

Таким образом если задачи однородные (примерно одинаковой тяжести) — просто используйте —scale worker=N. Celery сам разберется, кто свободен. А Если задачи разные по паттерну доступа и нагрузки — используйте параметр queue=’name‘ в DAG-е и запускайте воркеров с флагом -q name.
Вы можете проверить свои конфигурационные файлы docker-compose.yaml, dockerfile, и DAGи у нас на нашем репозитории к Бесплатному курсу для начинающих работать с оркестратором Apache Airflow
Тонкости настройки и типичные ошибки Docker-окружения
Переход на распределенную архитектуру часто сопровождается болью настройки. Разберем главные грабли.
Проблема 1: «Permission denied» и файлы логов
Docker-контейнеры по умолчанию любят работать от имени root. Если воркер создаст файл лога от root, а вы попытаетесь открыть его с хост-машины (или другой контейнер попробует прочитать его), будет ошибка доступа. Именно для этого мы добавили переменную user: «${AIRFLOW_UID:-5000}:0». Она заставляет процессы внутри контейнера работать с тем же ID пользователя, что и у вас в системе. Это критически важно для Linux-пользователей. Если видите ошибки доступа к папке logs — проверьте .env файл.
Проблема 2: Воркер не видит код
Новички часто меняют код DAG-а и не понимают, почему воркер выполняет старую версию. Причина: воркер загружает код в память при старте процесса. В Airflow есть настройка, как часто сканировать папку, но иногда проще перезапустить воркер. В Docker Compose это делается так: docker-compose restart worker
Проблема 3: Redis Connection Error
Если в логах воркера вы видите ConnectionRefusedError по адресу redis, проверьте две вещи:
- Запущен ли контейнер Redis (docker ps).
- Правильно ли указано имя хоста в AIRFLOW__CELERY__BROKER_URL. Оно должно совпадать с именем сервиса в docker-compose.yaml.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Помощь Cursor в документировании инфраструктуры
Когда ваш docker-compose.yaml разрастается, в нем легко запутаться. Здесь Cursor может стать вашим техническим писателем.
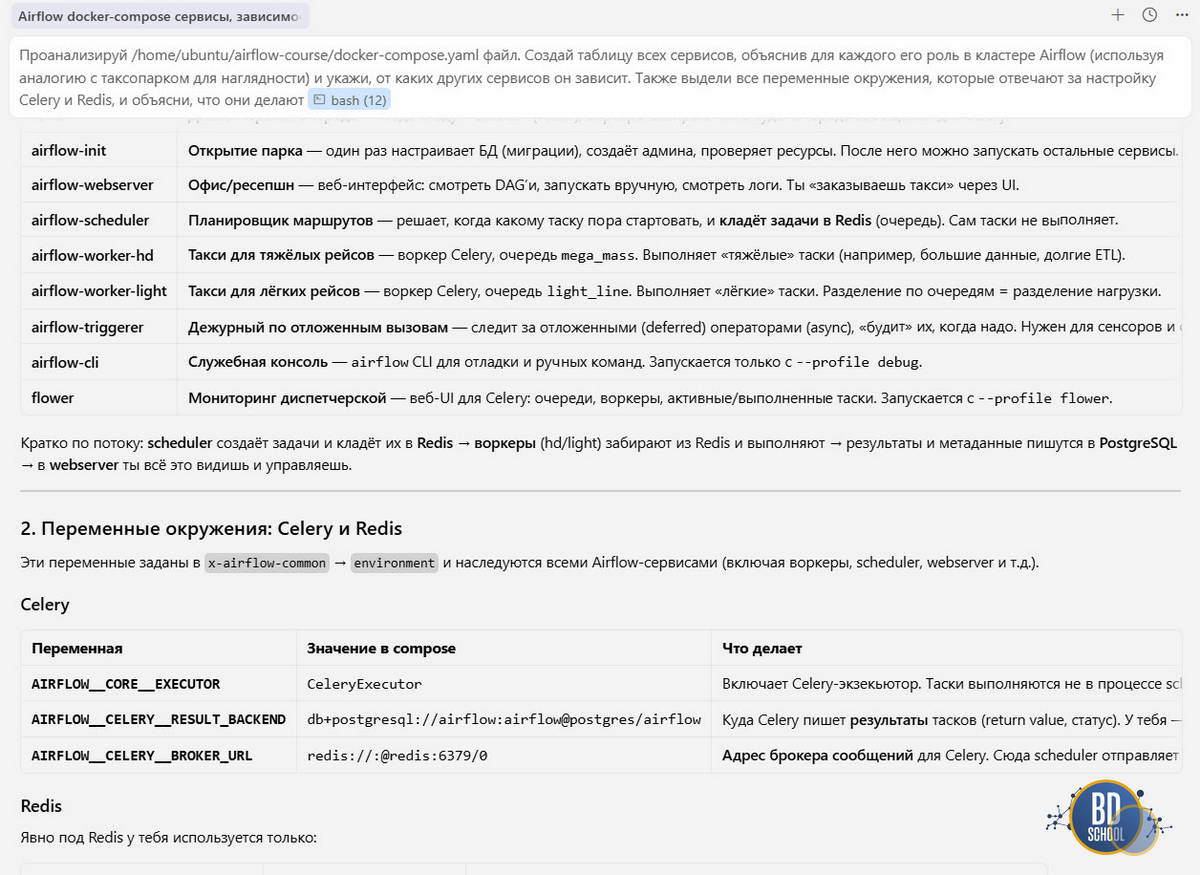
Попробуйте выделить весь файл конфигурации и отправить в чат Cursor такой промпт:
«Проанализируй этот docker-compose файл. Создай таблицу всех сервисов, объяснив для каждого его роль в кластере Airflow и укажи, от каких других сервисов он зависит. Также выдели все переменные окружения, которые отвечают за настройку Celery и Redis, и объясни, что они делают.»
Результат можно сразу копировать в README.md вашего проекта. Это спасет вас через полгода, когда вы забудете, зачем добавили flower или почему используется порт 5555.
Также можно попросить Cursor сгенерировать скрипт очистки (Это полезно при экспериментах, чтобы сбросить базу данных):
«Напиши bash-скрипт, который останавливает все контейнеры, удаляет их и очищает Docker volumes для этого проекта, чтобы я мог начать установку с чистого листа.»
В этой статье мы построили настоящий завод по переработке данных. Теперь у нас есть очередь задач, масштабируемые воркеры и мониторинг. Но пока что наши данные лежат либо в локальных файлах, либо в игрушечной базе.
В следующей статье мы выйдем во внешний мир: подключимся к объектному хранилищу S3 (MinIO). Мы научимся писать собственные Хуки (Hooks), чтобы Airflow мог забирать файлы из облака и класть их обратно, и разберем, как безопасно хранить пароли и ключи доступа, не светя их в коде. Готовы переходить к работе с S3?
Использованные референсы и материалы
- Scaling Out with Celery Executor
https://airflow.apache.org/docs/apache-airflow/stable/core-concepts/executor/celery.html
Официальное руководство по настройке распределенной очереди задач. - Celery: Distributed Task Queue
https://docs.celeryq.dev/en/stable/getting-started/introduction.html
Документация самой библиотеки Celery, чтобы понять, как работают воркеры и брокеры без привязки к Airflow. - Flower: Real-time monitor and web admin
https://flower.readthedocs.io/en/latest/
Инструкция к инструменту мониторинга, который мы запускаем на порту 5555.
Полный перечень статей Бесплатного курса «Apache Airflow для начинающих»
Урок 1. Apache Airflow с нуля: Архитектура, отличие от Cron и запуск в Docker
Урок 2. Масштабирование Airflow: Настройка CeleryExecutor и Redis для распределенности
Урок 3. Работа с базами данных в Airflow: Connections, Hooks и PostgresOperator
Урок 4. Airflow и S3: Интеграция с MinIO и Yandex Object Storage
Урок 5. Airflow и Hadoop: Настройка WebHDFS и работа с сенсорами (Sensors)
Урок 6. Запуск Apache Spark из Airflow: Гайд по SparkSubmitOperator
Урок 7. Airflow и Dask: Масштабирование тяжелых Python-задач и Pandas
Урок 8. Event-Driven Airflow: Запуск DAG по событиям из Apache Kafka
Урок 9. Загрузка данных в ClickHouse через Airflow: Быстрый ETL и батчинг
Урок 10. Airflow Best Practices: Динамические DAGи, TaskFlow API и Алертинг

