 1057
1057 
Содержание
Пример ETL-процесса в DAG Apache AirFlow: извлечение данных о выполненных заказах из PostgreSQL, преобразование в JSON-документ и загрузка в NoSQL-хранилище Elasticsearch в виде JSON-документа с отправкой уведомления в Telegram. Разработка и запуск кода в Google Colab.
Постановка задачи и проектирование конвейера в виде DAG AirFlow
О том, как построить простой ETL-конвейер в Apache AirFlow на примере выгрузки старых заказов из базы данных интернет-магазина на PostgreSQL, я уже здесь и здесь. Сегодня усложним прошлый вариант и будем выгружать данные о выполненных заказах не в файл на Google-диске, а в NoSQL-хранилище с мощным поисковым движком Elasticsearch.
Опишем каждую задачу в отдельном py-файле, выстраивая их последовательность в общем конвейере. Мой конвейер, т.е. DAG состоит из следующих задач:
- start_task — фиктивный оператор, представляющий начало DAG;
- extract_task — оператор Python, который вызывает функцию read_from_PostgreSQL_function для извлечения данных из PostgreSQL. Для параметра Provide_context установлено значение True, чтобы получить доступ к контексту выполнения.
- transform_task – оператор Python, который вызывает функцию write_to_JSON_function для преобразования данных, ранее считанных из БД, в файл JSON. Для параметра Provide_context также установлено значение True, поскольку результаты задачи extract_task будут входом для transform_task.
- load_task – оператор Python, который вызывает функцию write_to_ElasticDB_function для загрузки данных в ElasticDB. Для параметра Provide_context также установлено значение True, поскольку результаты задачи transform_task будут входом для load_task.
- send_notification_task – оператор Telegram, т.е. задача, которая отправляет уведомление в Telegram о выполнении процесса ETL. В тексте уведомления используются значения текущей даты и времени, а также результат выполнения задачи load_task.
- end_task – фиктивный оператор, представляющий конец DAG.
Задачи связаны между собой стрелками, которые указывают направление выполнения. Например, start_task выполняется перед extract_task, extract_task перед transform_task и т.д.

В результате выполнения данного DAG данные из PostgreSQL будут извлечены, преобразованы в формат JSON и загружены в Elasticserch, а затем будет отправлено уведомление о выполнении процесса.
Код DAG-файла выглядит следующим образом:
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.providers.telegram.operators.telegram import TelegramOperator
from datetime import datetime, timedelta
from ANNA_extract_task import read_from_PostgreSQL_function
from ANNA_transform_task import write_to_JSON_function
from ANNA_load_task import write_to_ElasticDB_function
default_args = {
'owner': 'airflow',
'start_date': datetime.now() - timedelta(days=1),
'retries': 1
}
dag = DAG(
dag_id='ANNA_DAG_ETL_from_PG_2_ElK',
default_args=default_args,
schedule_interval='@daily'
)
start_task = DummyOperator(task_id='start_task', dag=dag)
extract_task = PythonOperator(
task_id='extract_task',
provide_context=True,
python_callable=read_from_PostgreSQL_function,
dag=dag
)
transform_task = PythonOperator(
task_id='transform_task',
provide_context=True,
python_callable=write_to_JSON_function,
dag=dag
)
load_task = PythonOperator(
task_id='load_task',
provide_context=True,
python_callable=write_to_ElasticDB_function,
dag=dag
)
telegram_token = 'my TG-token'
telegram_chat_id = 'my chat id'
now=datetime.now()
send_notification_task = TelegramOperator(
task_id='send_notification_task',
token=telegram_token,
chat_id=telegram_chat_id,
text='ETL-process has been done {} with result {}'.format(
now.strftime("%m/%d/%Y, %H:%M:%S"),
'{{ ti.xcom_pull(key="return_value", task_ids="load_task") }}'
),
dag=dag
)
end_task = DummyOperator(task_id='end_task', dag=dag)
start_task >> extract_task >> transform_task >> load_task >> send_notification_task >> end_task
Задачи extract_task, transform_task и load_task описаны в отдельных файлах. Код задачи извлечения (extract_task), которая выполняет чтение из базы данных PostgreSQL заказов, выполненных за последние 3 месяца, т.е. 90 дней от текущей даты:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import psycopg2
def read_from_PostgreSQL_function(**kwargs):
connection_string = 'postgres://my-database'
conn = psycopg2.connect(connection_string)
select_query = """
SELECT
orders.id,
orders.date,
orders.sum,
product.name,
product.price,
order_product.quantity,
provider.name,
customer.name,
customer.phone,
customer.email,
customer_states.name,
delivery.date,
delivery.address,
delivery.price
FROM
orders
JOIN order_product ON order_product.order = orders.id
JOIN product ON product.id=order_product.product
JOIN provider ON provider.id = product.provider
JOIN customer ON orders.customer = customer.id
JOIN customer_states ON customer_states.id = customer.state
JOIN order_states ON order_states.id = orders.state
JOIN delivery ON orders.delivery = delivery.id
WHERE (orders.state=4) AND (orders.date BETWEEN (CURRENT_DATE-90) AND (CURRENT_DATE))
"""
cur = conn.cursor()
cur.execute(select_query)
results = cur.fetchall()
cur.close()
conn.close()
return results
В этом коде идет обращение к экземпляру PostgreSQL, развернутом в облачной платформе Hasura Cloud (Neon). Задача преобразования этих данных в JSON-файл transform_task выглядит так:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import json
import os
def write_to_JSON_function(**kwargs):
results = kwargs['ti'].xcom_pull(task_ids='extract_task')
orders = []
order_dict = {}
for result in results:
order_id, order_date, order_sum, product_name, product_price, product_quantity, product_provider, customer_name, customer_phone, customer_email, customer_status, delivery_date, delivery_address, delivery_price = result
if order_id not in order_dict:
order_dict[order_id] = {
'order_id': order_id,
'order_date': str(order_date),
'order_sum': order_sum,
'products': [],
'customer': {
'customer_name': customer_name,
'customer_phone': customer_phone,
'customer_email': customer_email,
'customer_status': customer_status
},
'delivery': {
'delivery_date': str(delivery_date),
'delivery_address': delivery_address,
'delivery_price': delivery_price
}
}
product = {
'product_name': product_name,
'product_price': product_price,
'product_quantity': product_quantity,
'product_provider': product_provider
}
order_dict[order_id]['products'].append(product)
orders = list(order_dict.values())
data = {
'orders': orders
}
filename = datetime.now().strftime("%Y-%m-%d_%H-%M-%S.json")
filepath = os.path.join('/content/airflow/files/delivered', filename)
with open(filepath, 'w') as f:
json.dump(data, f)
f.close()
return data
Помимо формирования JSON-документов для их передачи в задачу load_task я также записываю результаты выполнения SQL-запроса в файл на Google-диске для отладки в директорию /content/airflow/files/delivered.

Задача загрузки этих JSON-данных load_task в NoSQL-хранилище Elasticsearch выглядит так:
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import requests
from elasticsearch7 import Elasticsearch
def write_to_ElasticDB_function(**kwargs):
data = kwargs['ti'].xcom_pull(task_ids='transform_task')
# Установка подключения к Elasticsearch
es = Elasticsearch(
hosts=[{'host': my_elasict_host.bonsaisearch.net', 'port': 443, 'use_ssl': True}],
http_auth=('my-elastic-user', 'my-password')
)
# запись данных в индекс
response = es.index(index='orders_index', body=data)
# Проверка статуса ответа
if response['result'] == 'created':
print("Данные успешно записаны в индекс orders_index")
notification = 'success'
else:
print("Не удалось записать данные в индекс")
notification = 'failed'
return notification
Экземпляр Elasticsearch у меня развернут в облачной платформе bonsai. В этой документо-ориентированной СУБД с мощным поисковым движком аналогом таблицы реляционной базы данных является индекс. Поэтому я заранее создала индекс с помощью команды PUT^
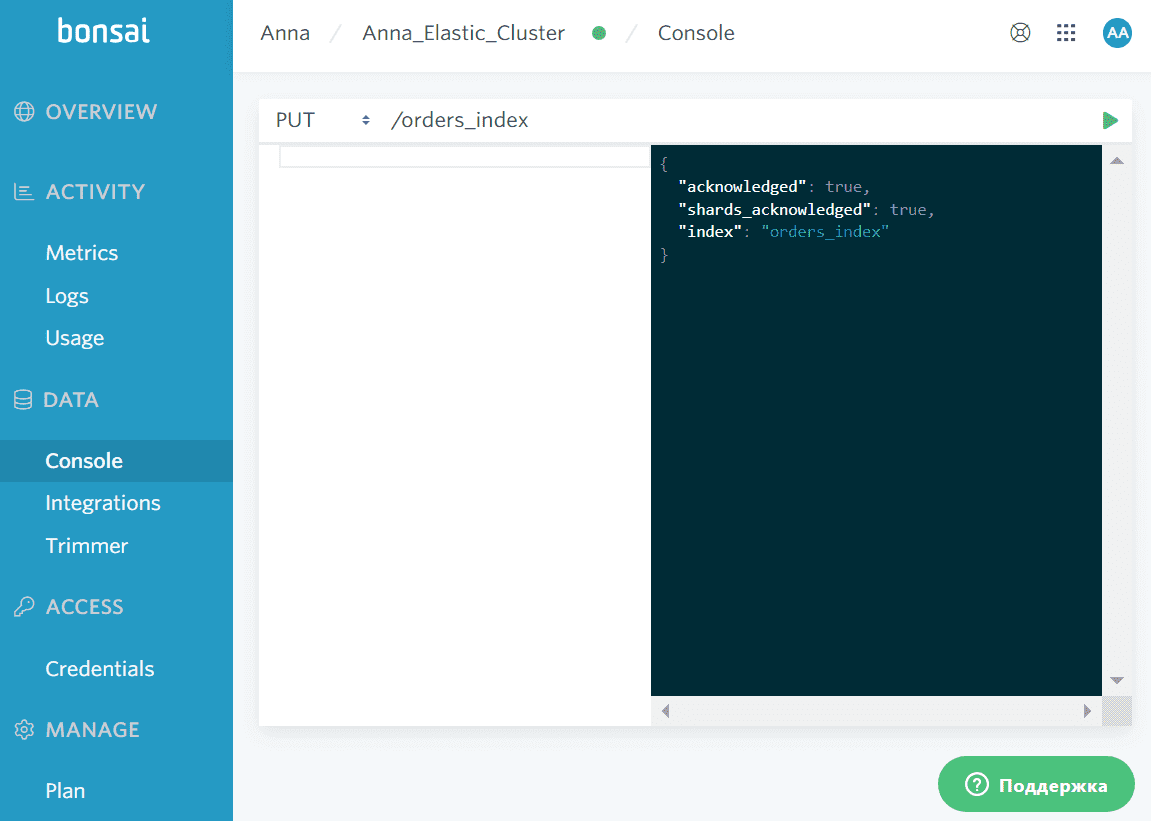
В этот индекс будут загружаться JSON-документы, которые в хранятся в Elasticsearch подобно строкам в таблице реляционной базы данных. После загрузки JSON-документов их можно будет запрашивать в Kibana – веб-интерфейсе Elasticsearch. Чтобы сделать это, сперва необходимо сформировать и загрузить эти документы, что я буду делать с помощью задач в DAG Apache AirFlow.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Реализация и запуск DAG AirFlow в Google Colab
Поскольку я запускаю код в интерактивной среде Google Colab, он будет более многословным. В частности, поскольку экземпляр Apache AirFlow развернут на удаленной машине Google Colab, придется прокинуть туннель, чтобы сделать ее локальный хост доступным извне по URL. Как обычно, для этого я использую утилиту ngrok.
Сперва установим все необходимые библиотеки и импортируем пакеты:
###############################################ячейка №1 в Google Colab#############################
#Установка Apache Airflow и инициализация базы данных.
!pip install apache-airflow
!airflow initdb
!pip install elasticsearch7==7.10.1
from elasticsearch7 import Elasticsearch
#Установка инструмента ngrok для создания безопасного туннеля для доступа к веб-интерфейсу Airflow из любого места
!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip
!unzip ngrok-stable-linux-amd64.zip
!pip install pyngrok
!pip install apache-airflow-providers-telegram
#импорт модулей
from pyngrok import ngrok
import sys
import os
import datetime
from airflow import DAG
from airflow.providers.telegram.operators.telegram import TelegramOperator
from google.colab import drive
drive.mount('/content/drive')
os.makedirs('/content/airflow/dags', exist_ok=True)
dags_folder = os.path.join(os.path.expanduser("~"), "airflow", "dags")
os.makedirs(dags_folder, exist_ok=True)
Затем следует запустить веб-сервер AirFlow в режиме демона, чтобы выполнение кода в этой ячейке Colab не блокировало другие:
!airflow webserver --port 8888 --daemon
Запускаем тунелирование с ngrok, задав токен аутентификации этой службы:
#Задание переменной auth_token для аутентификации в сервисе ngrok.
auth_token = " токен аутентификации, взятый с https://dashboard.ngrok.com/signup "
#Аутентификация в сервисе ngrok с помощью auth_token
os.system(f"ngrok authtoken {auth_token}")
#Запуск ngrok, который создаст публичный URL для сервера через туннель
#для доступа к веб-интерфейсу Airflow из любого места.
#addr="8888" указывает на порт, на котором запущен веб-сервер Airflow, а proto="http" указывает на использование протокола HTTP
public_url = ngrok.connect(addr="8888", proto="http")
#Вывод публичного URL для доступа к веб-интерфейсу Airflow
print("Адрес Airflow GUI:", public_url)
В результате в области вывода Colab появится URL-адрес, по которому будет доступен ранее запущенный веб-сервер AirFlow. Потом необходимо создать пользователя Apache AirFlow, установить логин и пароль. Моего пользователя традиционно зовут anna с ролью администратора и паролем password:
!airflow db init #Инициализация базы данных Airflow !airflow upgradedb #Обновление базы данных Airflow #Создание нового пользователя в Apache Airflow с именем пользователя anna, именем Anna, фамилией Anna, адресом электронной почты anna.doe@example.com и паролем password. #Этот пользователь будет иметь роль Admin, которая дает полный доступ к интерфейсу Airflow. !airflow users create --username anna --firstname Anna --lastname Anna --email anna@example.com --role Admin --password password
Теперь можно войти в веб-интерфейс пакетного оркестратора, используя эти учетные данные.
Чтобы управлять задачами и самим DAG программным образом, я дополнила их код инструкциями записи в файл, сохранения в рабочую директорию AirFlow и копирования в пользовательскую папку для просмотра. Например, Python-код задачи извлечения данных из PostgreSQL выглядит так:
########################Задача чтения из PostgreSQL#######################################
'postgres://my-database'
import psycopg2
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import os
import psycopg2
#import requests
def read_from_PostgreSQL_function(**kwargs):
connection_string = 'postgres://my-database'
conn = psycopg2.connect(connection_string)
select_query = """
SELECT
orders.id,
orders.date,
orders.sum,
product.name,
product.price,
order_product.quantity,
provider.name,
customer.name,
customer.phone,
customer.email,
customer_states.name,
delivery.date,
delivery.address,
delivery.price
FROM
orders
JOIN order_product ON order_product.order = orders.id
JOIN product ON product.id=order_product.product
JOIN provider ON provider.id = product.provider
JOIN customer ON orders.customer = customer.id
JOIN customer_states ON customer_states.id = customer.state
JOIN order_states ON order_states.id = orders.state
JOIN delivery ON orders.delivery = delivery.id
WHERE (orders.state=4) AND (orders.date BETWEEN (CURRENT_DATE-90) AND (CURRENT_DATE))
"""
cur = conn.cursor()
cur.execute(select_query)
results = cur.fetchall()
cur.close()
conn.close()
return results
'''
with open('/root/airflow/dags/ANNA_extract_task.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_extract_task.py /content/airflow/dags/ANNA_extract_task.py
А задача их преобразования извлеченных данных в JSON-документ выглядит так:
############################задача формирования JSON-документов##################################
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
import json
import os
def write_to_JSON_function(**kwargs):
results = kwargs['ti'].xcom_pull(task_ids='extract_task')
orders = []
order_dict = {}
for result in results:
order_id, order_date, order_sum, product_name, product_price, product_quantity, product_provider, customer_name, customer_phone, customer_email, customer_status, delivery_date, delivery_address, delivery_price = result
if order_id not in order_dict:
order_dict[order_id] = {
'order_id': order_id,
'order_date': str(order_date),
'order_sum': order_sum,
'products': [],
'customer': {
'customer_name': customer_name,
'customer_phone': customer_phone,
'customer_email': customer_email,
'customer_status': customer_status
},
'delivery': {
'delivery_date': str(delivery_date),
'delivery_address': delivery_address,
'delivery_price': delivery_price
}
}
product = {
'product_name': product_name,
'product_price': product_price,
'product_quantity': product_quantity,
'product_provider': product_provider
}
order_dict[order_id]['products'].append(product)
orders = list(order_dict.values())
data = {
'orders': orders
}
filename = datetime.now().strftime("%Y-%m-%d_%H-%M-%S.json")
filepath = os.path.join('/content/airflow/files/delivered', filename)
with open(filepath, 'w') as f:
json.dump(data, f)
f.close()
return data
'''
with open('/root/airflow/dags/ANNA_transform_task.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_transform_task.py /content/airflow/dags/ANNA_transform_task.py
Задача загрузки в Elasticsearch:
############################задача записи в Elasticsearch##################################
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
import requests
from elasticsearch7 import Elasticsearch
def write_to_ElasticDB_function(**kwargs):
data = kwargs['ti'].xcom_pull(task_ids='transform_task')
# Установка подключения к Elasticsearch
es = Elasticsearch(
hosts=[{'host': my_elasict_host.bonsaisearch.net', 'port': 443, 'use_ssl': True}],
http_auth=('my-elastic-user', 'my-password')
)
# Запись данных в индекс
response = es.index(index='orders_index', body=data)
# Проверка статуса ответа
if response['result'] == 'created':
print("Данные успешно записаны в индекс orders_index")
notification = 'success'
else:
print("Не удалось записать данные в индекс")
notification = 'failed'
return notification
'''
with open('/root/airflow/dags/ANNA_load_task.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_load_task.py /content/airflow/dags/ANNA_load_task.py
Сам DAG-файл создается следующим кодом:
########################из разных файлов DAG чтения из PostgreSQL и записи JSON в Elastic############################
from google.colab import files
code = '''
from airflow import DAG
from airflow.operators.python import PythonOperator
from airflow.operators.dummy_operator import DummyOperator
from airflow.providers.telegram.operators.telegram import TelegramOperator
from datetime import datetime, timedelta
from ANNA_extract_task import read_from_PostgreSQL_function
from ANNA_transform_task import write_to_JSON_function
from ANNA_load_task import write_to_ElasticDB_function
default_args = {
'owner': 'airflow',
'start_date': datetime.now() - timedelta(days=1),
'retries': 1
}
dag = DAG(
dag_id='ANNA_DAG_ETL_from_PG_2_ElK',
default_args=default_args,
schedule_interval='@daily'
)
start_task = DummyOperator(task_id='start_task', dag=dag)
extract_task = PythonOperator(
task_id='extract_task',
provide_context=True,
python_callable=read_from_PostgreSQL_function,
dag=dag
)
transform_task = PythonOperator(
task_id='transform_task',
provide_context=True,
python_callable=write_to_JSON_function,
dag=dag
)
load_task = PythonOperator(
task_id='load_task',
provide_context=True,
python_callable=write_to_ElasticDB_function,
dag=dag
)
telegram_token = 'my TG-token'
telegram_chat_id = 'my chat-id'
now=datetime.now()
send_notification_task = TelegramOperator(
task_id='send_notification_task',
token=telegram_token,
chat_id=telegram_chat_id,
text='ETL-process has been done {} with result {}'.format(
now.strftime("%m/%d/%Y, %H:%M:%S"),
'{{ ti.xcom_pull(key="return_value", task_ids="load_task") }}'
),
dag=dag
)
end_task = DummyOperator(task_id='end_task', dag=dag)
start_task >> extract_task >> transform_task >> load_task >> send_notification_task >> end_task
'''
with open('/root/airflow/dags/ANNA_DAG_from_PotgreSQL_2_Elastic.py', 'w') as f:
f.write(code)
!cp ~/airflow/dags/ANNA_DAG_ETL_from_PG_2_ElK.py /content/airflow/dags/ANNA_DAG_ETL_from_PG_2_ElK.py
!airflow dags unpause ANNA_DAG_ETL_from_PG_2_ElK
Чтобы увидеть этот DAG в списке всех конвейеров, нужно запустить планировщик AirFlow в фоновом режиме:
!airflow scheduler --daemon
При отсутствии ошибок DAG появится в веб-интерфейсе:
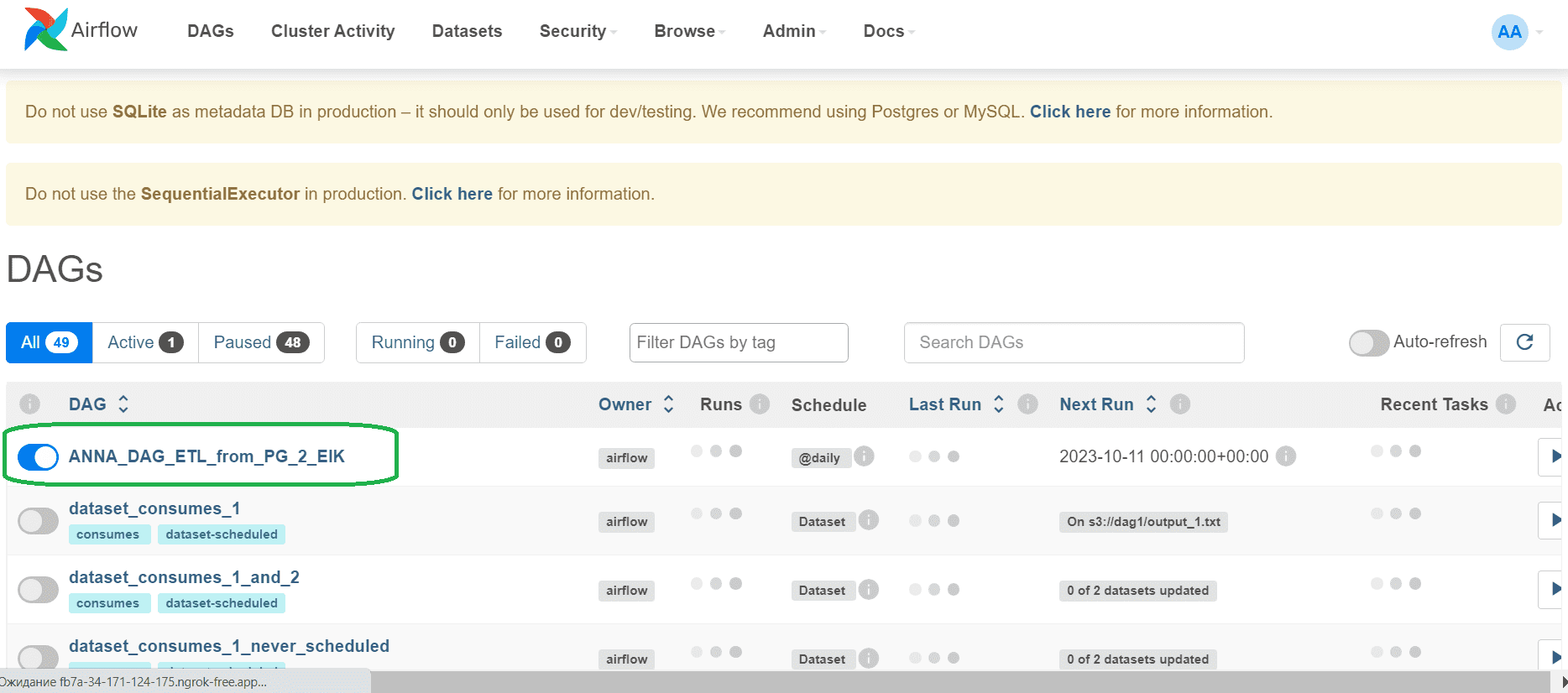
Передача данных между задачами происходит через механизм XCom, список всех этих объектов что можно также посмотреть в веб-интерфейсе.
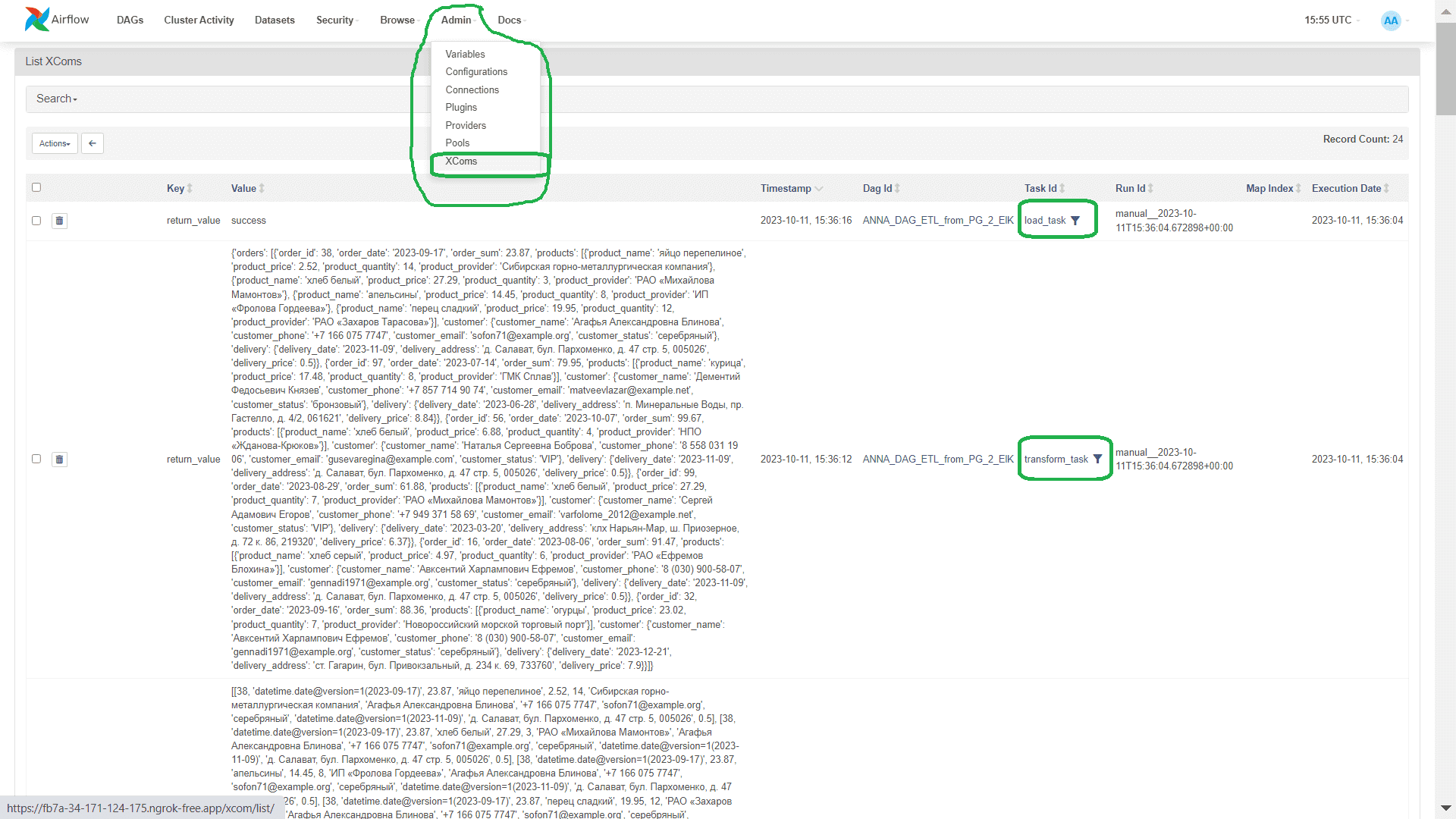
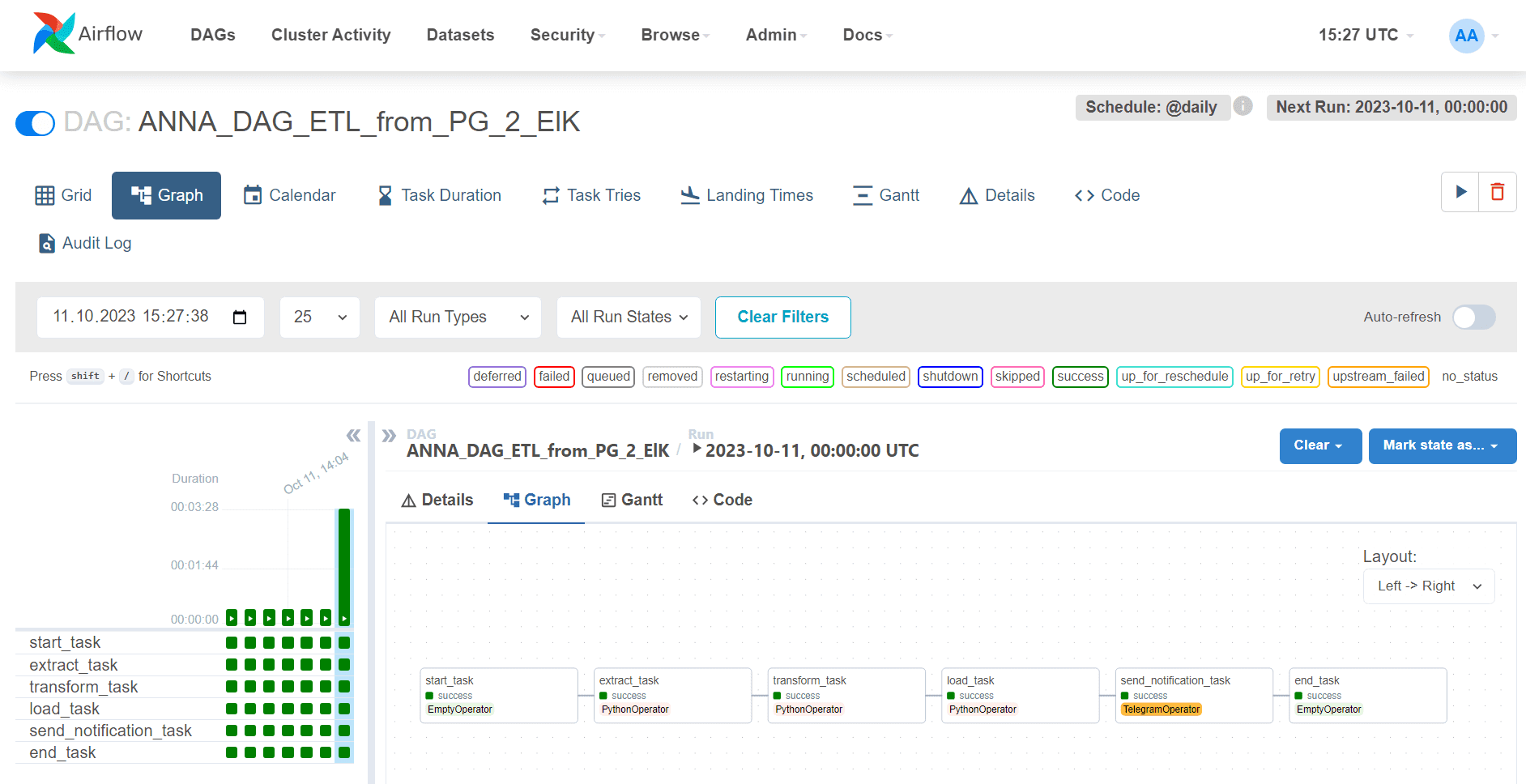
Результаты выполнения запусков созданного DAG и каждой из его задач можно просмотреть в его деталях.
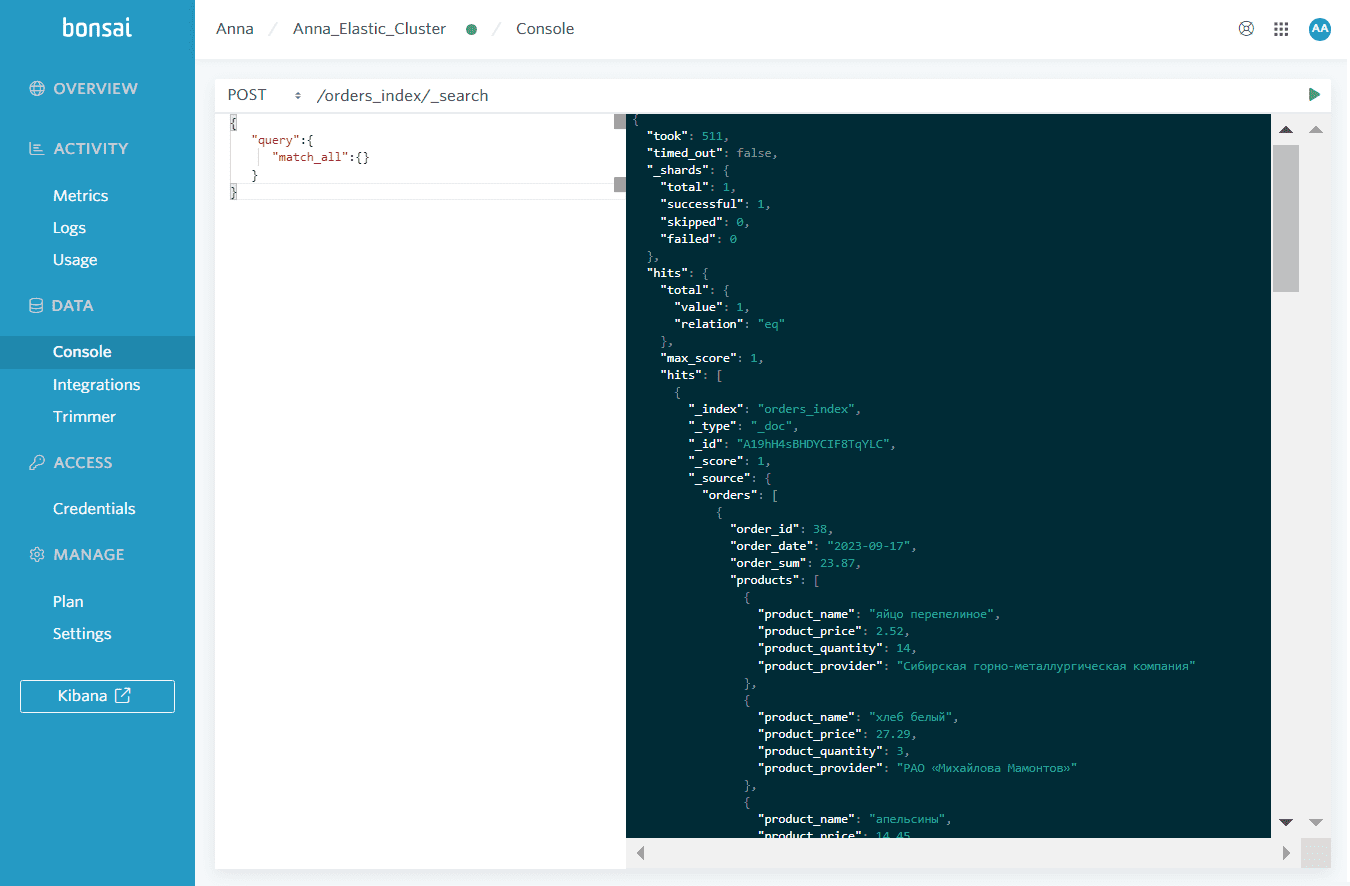
После успешного выполнения DAG в пользовательской папке Colab появятся JSON-файлы с данными, а в Elasticsearch – данные из этих JSON-документов. Проверить это можно, отправив POST-запрос к индексу, используя DSL-язык запросов Elasticsearch в консоли платформы bonsai. Запрос с использованием API поиска будет отправляться к индексу по маршруту /orders_index/_search, а в теле запроса будет выражение для возврата всех результатов:
{
"query":{
"match_all":{}
}
}
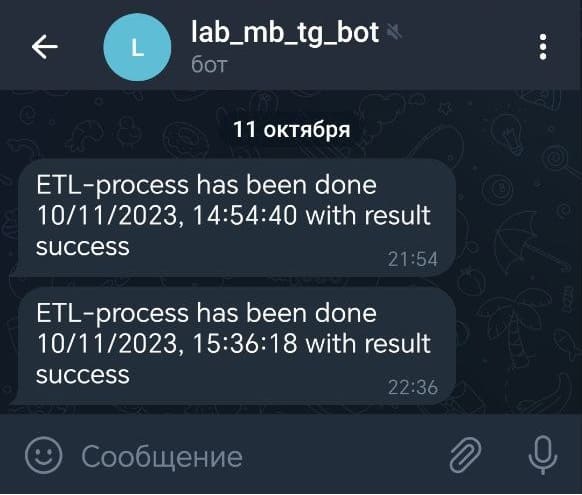
Поскольку последней задачей в моем DAG является отправка уведомления о результатах ETL-процесса в Телеграмм-бот, сообщение окажется в чате.
Как улучшить этот DAG, реализовав программное подключение к внешним источникам и чтение SQL-запросов из файлов, читайте в нашей новой статье.
Apache Airflow для инженеров данных
Код курса
AIRF
Ближайшая дата курса
23 марта, 2026
Продолжительность
24 ак.часов
Стоимость обучения
76 800
Освойте Apache AirFlow и его применение в дата-инженерии и аналитике больших данных на специализированных курсах в нашем лицензированном учебном центре обучения и повышения квалификации для разработчиков, менеджеров, архитекторов, инженеров, администраторов, Data Scientist’ов и аналитиков Big Data в Москве:

