 549
549 
Содержание
- Зачем нужен Vector Database: Проблема поиска по смыслу
- Как работает Vector Database: Векторизация и ANN
- Шаг 1. Векторизация (Embeddings)
- Шаг 2. Поиск по сходству (Similarity Search)
- Шаг 3. Индексы ANN (Approximate Nearest Neighbor)
- Сценарии использования: От RAG до рекомендаций
- Обзор решений: Opensource, DIY и российские разработки
- Приоритет Opensource: "Чистокровные" Vector DB
- DIY и российские корни: Используем то, что уже есть
- Облачные (SaaS) решения
- Вызовы и "подводные камни"
- Заключение
- Референсные ссылки
Vector Database (Векторная база данных) — это специализированная система хранения данных, предназначенная для эффективного хранения, индексации и поиска векторов (embeddings). Векторы, в свою очередь, являются математическими представлениями неструктурированных данных, таких как текст, изображения, аудио или видео.
В отличие от традиционных баз данных, которые хранят данные в таблицах (строки и столбцы) или документах (JSON), Vector Database организована вокруг векторных пространств. Это позволяет ей выполнять главную задачу — находить объекты не по точному совпадению, а по смысловой близости.
Проще говоря, такая база данных — это не «картотека», а «карта смыслов». Она позволяет задавать вопросы вроде «Найди мне все, что похоже на вот это», а не «Найди мне то, что точно равно вот этому».
Зачем нужен Vector Database: Проблема поиска по смыслу
Фундаментальная проблема традиционных баз данных (например, SQL) заключается в их неспособности понимать неструктурированные данные. Они отлично работают с запросами WHERE name = ‘Иван’ или WHERE price > 100, но они абсолютно бессильны, если вам нужно:
- Найти статью, похожую по смыслу на заданный параграф.
- Найти изображение, на котором «собака бежит по пляжу», имея в качестве запроса другую картинку с собакой.
- Найти аудиофрагмент, похожий по тональности на образец.
Традиционные базы ищут синтаксическое (буквальное) совпадение. Vector Database выполняет семантический поиск (semantic search), или поиск по смысловой близости. Он ищет «ближайших соседей» в многомерном пространстве. Например, в этом пространстве векторы слов «король», «королева» и «монарх» будут расположены очень близко друг к другу.
Как работает Vector Database: Векторизация и ANN
Чтобы понять «магию» векторного поиска, нужно разделить процесс на три ключевых этапа. Я объясню их «на пальцах», как я сам в этом разбирался.
Шаг 1. Векторизация (Embeddings)
Прежде чем данные попадут в базу, их нужно превратить в векторы. Этот процесс называется векторизация (vectorization). Этим занимаются модели машинного обучения (ML-модели), такие как BERT, CLIP или Sentence Transformers.
- Модель берет «сырые» данные (например, текст «Привет, мир!») и преобразует их в массив чисел (вектор), например: [0.12, -0.45, 0.89, … , 0.33].
- Этот вектор — это «отпечаток» или «координата» смысла в многомерном пространстве.
- Важно: Сама Vector Database чаще всего не создает векторы. Она их только получает, хранит и индексирует.
Шаг 2. Поиск по сходству (Similarity Search)
Когда в базу поступает поисковый запрос (например, текст «Прощай, друг!»), он также проходит векторизацию. База данных получает вектор запроса и ищет в своем хранилище «ближайших соседей» (Nearest Neighbors) — векторы, которые расположены к нему ближе всего.
Для измерения «близости» используются математические функции, такие как Косинусное сходство (Cosine Similarity) или Евклидово расстояние (Euclidean Distance).
Шаг 3. Индексы ANN (Approximate Nearest Neighbor)
Если бы база данных «в лоб» сравнивала вектор запроса с каждым из миллиардов векторов в хранилище (полный перебор или Exact Nearest Neighbor), поиск был бы мучительно долгим.
Здесь и кроется «секретный соус» производительности — ANN (Approximate Nearest Neighbor), или Приблизительный поиск ближайших соседей.
Vector Database строит специальные индексы (самый популярный — HNSW, Hierarchical Navigable Small World), которые позволяют находить «почти» самых близких соседей, но делать это в тысячи раз быстрее. Мы сознательно жертвуем 1-2% точности (находим 98% самых похожих, а не 100%) в обмен на колоссальный прирост скорости. Для 99% задач AI этого более чем достаточно.
ИИ-агенты для оптимизации бизнес-процессов
Код курса
AGENT
Ближайшая дата курса
18 мая, 2026
Продолжительность
24 ак.часов
Стоимость обучения
66 000
Сценарии использования: От RAG до рекомендаций
Vector Database — это не просто хайп, это компонент, который открыл дорогу для множества современных AI-технологий.
- Retrieval-Augmented Generation (RAG). Это самый главный сценарий использования. Vector Database служит «внешней памятью» для LLM (Больших Языковых Моделей).
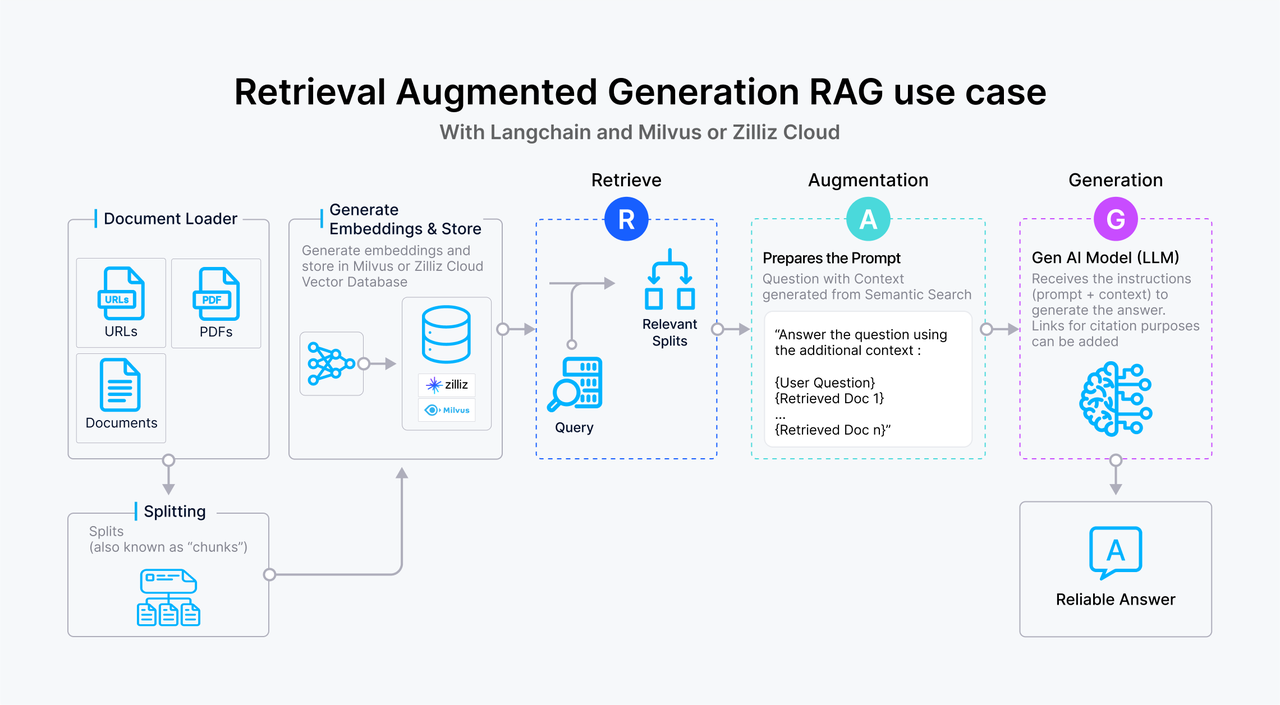
Когда вы задаете вопрос чат-боту, он сначала ищет в векторной базе релевантные куски вашей документации, а затем «скармливает» их LLM вместе с вашим вопросом. Это позволяет LLM отвечать по вашим данным и бороться с галлюцинациями.
- Семантический поиск. Поиск по смыслу в больших базах документов, научных статей, тикетов техподдержки или корпоративных базах знаний.
- Рекомендательные системы. Классическая задача «пользователи, похожие на вас, также купили…» или «видео, похожие на то, что вы смотрели».
- Поиск по изображениям, видео и аудио. Поиск дубликатов, поиск похожих товаров по фото, модерация контента.
Обзор решений: Opensource, DIY и российские разработки
Рынок векторных баз растет, но для практика-самоучки важно уметь работать с открытыми и доступными инструментами. Вместо того чтобы сразу «покупать» дорогое облачное решение (SaaS), мы можем построить 90% систем на Opensource.
Приоритет Opensource: «Чистокровные» Vector DB
Это базы, созданные с нуля специально для векторов. Их можно развернуть локально или на своих серверах.
- Milvus: Один из самых популярных и зрелых Opensource-проектов. Масштабируемый, поддерживаемый большим сообществом.
- Qdrant: Очень быстрая и эффективная база, написанная на Rust. Отлично подходит для высоких нагрузок и ценится за производительность.
- Weaviate: Еще один мощный игрок, который также умеет хранить и сами объекты, а не только векторы.
DIY и российские корни: Используем то, что уже есть
Это мой любимый подход — «сделай сам» (DIY). Зачем разворачивать новую базу, если можно «прикрутить» векторный поиск к тому, что уже отлично работает?
- ClickHouse (Российские корни). Это главное решение, на которое стоит обратить внимание. ClickHouse — это колоночная СУБД с российскими корнями, известная своей невероятной скоростью. С недавних пор она получила мощные функции для векторного поиска. Используя индексы типа annoy или hnsw, ClickHouse позволяет хранить миллиарды векторов и выполнять по ним поиск с той же скоростью, что и специализированные базы. Для многих компаний, у которых ClickHouse уже используется для аналитики, это идеальный и «бесшовный» способ добавить AI-функции в свой стек.
- PostgreSQL (pg_vector). Для небольших и средних проектов (до нескольких миллионов векторов) можно не усложнять. Популярное расширение pg_vector превращает ваш «старый добрый» Postgres в полноценную векторную базу. Идеально для стартапов и прототипов.
Облачные (SaaS) решения
Для полноты картины стоит упомянуть Pinecone. Это одна из первых «облачных» (SaaS) векторных баз. Она очень проста в использовании (не нужно ничего настраивать), но это коммерческий продукт, который вы не можете развернуть у себя.
Вызовы и «подводные камни»
Работа с Vector Database не так проста, как кажется на первый взгляд. Есть несколько «подводных камней»:
- «Проклятие размерности» (Curse of Dimensionality): Чем больше измерений (например, 1536 у векторов OpenAI) в ваших векторах, тем «дальше» все векторы друг от друга. Это усложняет поиск и требует больше ресурсов.
- Выбор индекса: Выбор правильного ANN-индекса (HNSW, IVF_FLAT и т.д.) и его настройка — это компромисс между скоростью, точностью и потреблением памяти.
- Стоимость векторизации: Процесс превращения данных в векторы (Шаг 1) может быть вычислительно дорогим и медленным.
- Хранение: Векторы занимают много места. Миллиард векторов размерности 768 — это сотни гигабайт и терабайты RAM для индексов.
Практическое применение Big Data аналитики для решения бизнес-задач
Код курса
PRUS
Ближайшая дата курса
20 апреля, 2026
Продолжительность
32 ак.часов
Стоимость обучения
102 400
Заключение
Vector Database (Векторная база данных) — это не просто хайп или очередная модная технология. Это новый фундаментальный слой в современном стеке данных. Это «движок», который позволяет машинам понимать смысл неструктурированного мира.
Для инженера или аналитика, особенно с фокусом на Opensource и российских технологиях, крайне важно освоить эти инструменты. Использование таких систем, как ClickHouse, для векторного поиска доказывает, что мощные AI-системы можно и нужно строить на базе открытых и эффективных решений, не привязываясь к дорогим облачным провайдерам.
Референсные ссылки
- ClickHouse Vector Search (Официальная документация) (https://clickhouse.com/docs/en/guides/vector-search)
- Milvus.io (Официальный сайт) (https://milvus.io/)
- Qdrant.tech (Официальный сайт) (https://qdrant.tech/)
- Расширение pg_vector для PostgreSQL (https://github.com/pgvector/pgvector)
- Weaviate.io (Официальный сайт) (https://weaviate.io/)