 1315
1315 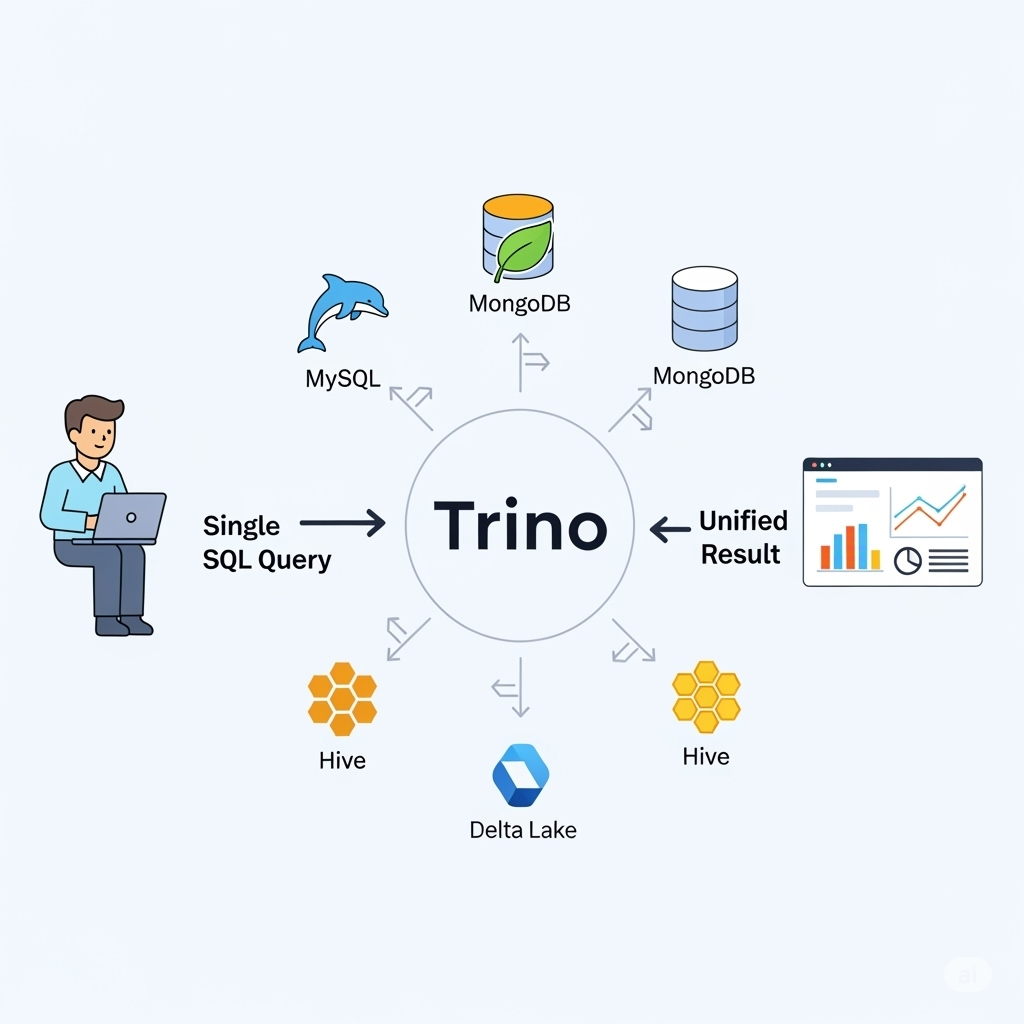
Содержание
Trino — это высокопроизводительный, распределенный SQL-движок с открытым исходным кодом. Он предназначен для выполнения быстрых интерактивных аналитических запросов к данным из различных источников. Его главная особенность — способность запрашивать данные там, где они находятся (querying data in-place), без необходимости их перемещения в единое хранилище. Таким образом, Трино не является базой данных, а представляет собой мощный вычислительный слой, который позволяет объединять данные из нескольких систем в одном запросе.
Представьте Trino как универсального переводчика. Он понимает ваш вопрос на языке SQL, обращается к разным источникам данных (озера данных, реляционные базы, NoSQL системы), получает от них ответы и объединяет их в единый результат. Это значительно упрощает аналитику в сложных, гетерогенных средах.
Trino что это: история и экосистема
Для полного понимания роли Trino важно знать его происхождение и окружение.
История: Trino vs. Presto Trino изначально был разработан в Facebook под названием Presto. Он был создан для быстрых интерактивных запросов к их огромному хранилищу данных. Со временем пути основной команды разработчиков и Facebook разошлись. Команда создала форк проекта под названием PrestoSQL, чтобы развивать его как независимый open-source продукт. В 2020 году, чтобы избежать путаницы, PrestoSQL был переименован в Trino. Сегодня Trino и PrestoDB (проект Facebook) — это два разных движка, хотя и с общей историей. Trino развивается более активно и считается стандартом де-факто в сообществе.
Ключевые проекты в экосистеме
- Starburst: Это компания, основанная создателями Trino. Она предоставляет коммерческую, полностью поддерживаемую версию Trino (Starburst Enterprise и Starburst Galaxy) с дополнительными функциями безопасности, коннекторами и инструментами управления.
- Apache Iceberg, Delta Lake, Hudi: Это современные форматы таблиц для озер данных. Trino имеет отличную интеграцию с ними. Это позволяет выполнять ACID-транзакции и надежные операции с данными прямо в озере данных.
Ключевые характеристики
Трино обладает набором мощных характеристик, которые делают его популярным выбором для современной аналитики:
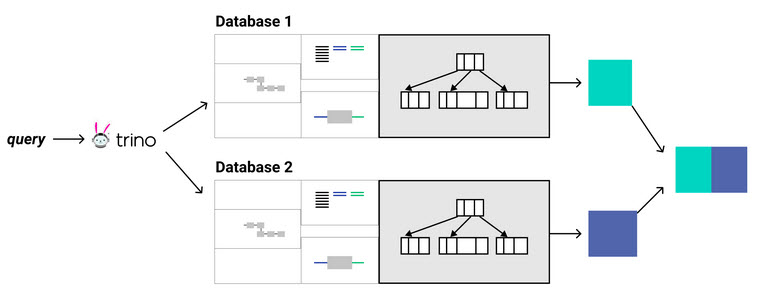
- Федеративные запросы. Это главная сила Trino. Он позволяет выполнять один SQL-запрос, который может объединять данные из нескольких совершенно разных источников. Например, вы можете соединить (JOIN) данные клиентов из PostgreSQL с логами из Amazon S3 без необходимости в сложном ETL-процессе.
- Разделение вычислений и хранения. Trino работает как независимый вычислительный слой, отделенный от систем хранения. Такая архитектура дает гибкость, позволяя масштабировать вычисления и хранение независимо друг от друга.
- Высокая производительность. В основе дивжка Трино SQL лежит архитектура MPP (Massively Parallel Processing), где запросы распараллеливаются на множество узлов кластера. Обработка данных происходит в оперативной памяти, что минимизирует задержки и обеспечивает высокую скорость выполнения запросов.
- Масштабируемость. Кластер Трино легко масштабируется горизонтально путем добавления новых рабочих узлов (Worker nodes). Это позволяет эластично наращивать вычислительную мощность для соответствия нагрузке.
- Совместимость с ANSI SQL. Trino использует стандартный синтаксис SQL, что снижает порог вхождения для аналитиков и инженеров, позволяя им использовать уже знакомые инструменты.
Архитектура и принцип работы Trino
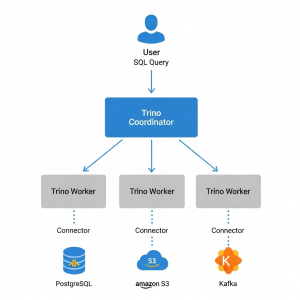
Понимание архитектуры Trino помогает осознать его мощь. Кластер состоит из двух типов узлов: Координатора и Воркеров.
Координатор (Coordinator) — это «мозг» кластера, который принимает запросы от клиента. Он отвечает за парсинг, анализ и планирование SQL-запроса, но сам не выполняет обработку данных, а распределяет задачи между рабочими узлами.
Воркер (Worker) — это «рабочие руки» кластера. Воркеры выполняют задачи, полученные от координатора, и подключаются к источникам данных через специальные плагины — коннекторы. Они извлекают данные, обрабатывают их в памяти и передают результаты друг другу или координатору.
Коннекторы являются ключевым элементом Трино, так как именно они «учат» движок общаться с конкретным источником данных. Существуют коннекторы для десятков систем, включая озера данных (Hive, Iceberg), реляционные БД (PostgreSQL, MySQL), NoSQL-системы (MongoDB) и платформы потоковой обработки (Kafka).
Процесс выполнения запроса проходит в несколько логичных этапов. Сначала клиент отправляет SQL-запрос координатору, который парсит его и проверяет синтаксис. Затем координатор запрашивает метаданные у коннекторов для понимания структуры таблиц и создает оптимальный план выполнения. Этот план разбивается на этапы (Stages) и задачи (Tasks), которые назначаются доступным воркерам. Наконец, воркеры через коннекторы извлекают данные из источников, обрабатывают их и возвращают финальный результат клиенту через координатор.
Пошаговое выполнение запроса в Trino
- Клиент отправляет SQL-запрос координатору.
- Координатор парсит запрос и проверяет его синтаксис.
- Он запрашивает метаданные у коннекторов. Это нужно для понимания структуры таблиц.
- Координатор создает оптимальный план выполнения запроса (Query Plan).
- План разбивается на этапы (Stages), а этапы — на задачи (Tasks).
- Координатор назначает задачи доступным воркерам.
- Воркеры через коннекторы извлекают данные из источников.
- Данные обрабатываются параллельно на воркерах. Обработка идет в памяти.
- Промежуточные результаты передаются между воркерами для дальнейшей обработки.
- Финальный результат отправляется на координатор.
- Координатор передает итоговый результат клиенту.
Сценарии применения
Гибкость Trino открывает множество сценариев его использования:
- Интерактивная аналитика для озера данных. Это основной сценарий, позволяющий аналитикам выполнять быстрые ad-hoc запросы напрямую к файлам в S3 или HDFS.
- Федеративная аналитика. Компании могут объединять данные из операционных баз (например, MySQL) и хранилищ (например, ClickHouse) в одном отчете без перемещения данных.
- Создание единой точки доступа. Trino может выступать в роли единого окна для доступа ко всем данным компании, что упрощает управление доступом для BI-инструментов.
- BI и отчетность. Инструменты вроде Tableau, Power BI или Superset могут подключаться к Trino для построения дашбордов и отчетов.
Сравнение Trino с другими SQL-инструментами
Trino часто сравнивают с другими инструментами для анализа больших данных, однако он занимает свою уникальную нишу.
- Trino vs. Presto. Trino является форком PrestoDB и развивается независимым сообществом, которое включает первоначальных создателей движка. На сегодняшний день Trino считается более активно развиваемым проектом с более широким набором функций и улучшенной производительностью, что делает его предпочтительным выбором для большинства новых внедрений.
- Trino vs. Greenplum (с PXF). Greenplum — это MPP-хранилище данных, то есть система, которая хранит данные и обрабатывает их. Его компонент PXF добавляет возможность федеративных запросов, подобно Трино. Основное отличие в том, что Greenplum — это в первую очередь база данных, а Трино— исключительно движок запросов, не имеющий своего хранилища. Трино предлагает большую гибкость в выборе источников данных.
- Trino vs. ClickHouse. ClickHouse — это сверхбыстрая аналитическая СУБД, оптимизированная для OLAP-запросов к данным, которые загружены внутрь неё. Хотя ClickHouse и может запрашивать данные из внешних источников, это не является его основной функцией. Trino же создан именно для федеративных запросов к внешним, распределенным системам. Выбор между ними зависит от задачи: для анализа данных в едином хранилище лучше подойдет ClickHouse, а для объединения данных из множества систем — Trino.
Trino для инженеров данных
Код курса
TRINO
Ближайшая дата курса
27 апреля, 2026
Продолжительность
16 ак.часов
Стоимость обучения
51 200
Практическое использование: Примеры запросов
Работа с Трино обычно происходит через CLI или любой SQL-клиент с JDBC-драйвером. В запросах используется трехуровневое именование: catalog.schema.table, где catalog соответствует настроенному коннектору.
Подключение через CLI
# Подключение к координатору Trino ./trino-cli --server http://localhost:8080 --user admin --catalog hive
Простой SELECT из одного источника (каталог hive)
Этот запрос получает данные из таблицы users, которая находится в озере данных и управляется через Hive Metastore.
-- Выбрать имена и email всех пользователей из Франции SELECT full_name, email FROM hive.web_logs.users WHERE country_code = 'FR' LIMIT 100;
Федеративный запрос: JOIN между PostgreSQL и Hive
Это самый показательный пример мощи Trino. Запрос объединяет данные о покупателях из базы данных PostgreSQL (каталог postgres_db) с логами просмотров из озера данных S3 (каталог hive).
-- Найти email-адреса активных покупателей, -- которые недавно просматривали товары на сайте. SELECT u.email, p.last_view_timestamp FROM postgres_db.public.customers u JOIN hive.web_logs.page_views p ON u.customer_id = p.customer_id WHERE u.status = 'ACTIVE';
Использованные источники и материалы
- Официальная документация Trino https://trino.io/docs/current/
- Starburst Resources https://www.starburst.io/resources/
- Статья о федеративных запросах в Trino (Preset.io) https://preset.io/blog/2021-6-22-trino-superset/
- Блог Redpanda о совместном использовании с Trino https://www.redpanda.com/blog/data-lake-query-federation-tutorial
- Trino курс — обучение в «Школе Больших Данных»